隨著半導體科技的進步,大型叢集運算系統也應運而生。國家高速網路與計算中心(簡稱國網中心)在2006年便開始規劃建置的新一代高速計算平台,並於2007年9月1日正式上線供國網中心計算用戶使用。
計算節點監控機制
計算節點監控機制的運作方式為自行撰寫shell script,在管理節點上以cron job方式,每隔一小時對所有計算節點進行監控,並將異常狀況發信通知系統一線、二線人員及廠商系統工程師。當計算節點之排程系統停止運作時先嘗試啟動排程系統,如因網路斷線無法啟動排程系統,則透過IBM CSM提供的rpower指令重開系統。如果rpower不成功,一線人員便進入機房以手動方式重開,當無法開機或重開後檢查有硬體損壞,則立即通報廠商到場維修。
說明
雖然每台計算節點的記憶體容量為16GB,由於使用者工作資料量太大,所以偶有paging space用盡導致系統異常狀況發生。此監控機制可找出異常節點並提供適當處理機制,以減少系統當機的時間。
節點記憶體監測機制
節點記憶體監測的運作方式為,自行撰寫shell script,在所有節點上以cron job方式,每隔5分鐘記錄該節點記憶體用量前20大的process。當系統paging space用盡發生異常時,則於系統重開後檢查紀錄檔,並通知相關使用者。
說明
以下為shell script內容,利用一些簡單的Linux指令,記錄每個節點記憶體使用量,當節點資源耗盡發生異常時,則於系統重開後檢視紀錄檔。
以下為紀錄檔內容,其中SZ單位為4KB,節點當機前使用者使用之記憶體為81.20GB(=5321570×4÷1024÷1024×4)。
乙太網路交換器監測機制
乙太網路交換器監測的運作方式為,自行撰寫shell script,在管理節點上以cron job方式,每隔2分鐘將2台乙太網路交換器的系統記錄寄給系統一線和二線人員,如果需要則通知廠商系統工程師做進一步檢查。
說明
由於不熟悉乙太網路交換器的操作指令,所以將2台Force10的系統紀錄轉到管理節點的messages檔中,每隔2分鐘將相關紀錄,包括交換器連線紀錄、主機斷線或記憶體發生錯誤等訊息,發信告知系統一線及二線人員。以下為部分紀錄內容。
值得一提是,在97年9月23日,force10-2同時出現2台電源供應器(Power Supply)故障的情況,如果再當掉有1台,整座force10-2將無法運作,進而影響到整套系統。
由於廠商已事先備妥關鍵零件,所以在接獲通知後5小時就完成零件更換,因此未造成服務中斷。
表2則為乙太網路子系統異常事件的統計,雖然次數不多,不過每次都要花上很多的時間才能完成修復。以Force10-2更換Chassis為例子,修復的時間就長達了12小時。
儲存設備監測機制
儲存設備監測機制的運作方式是,當IBM DS4800儲存系統發現設備異常時便發信通知系統一線、二線人員及廠商系統工程師,系統一線人員先進行初步檢查,如屬硬體問題,則通知廠商硬體工程師處理。
說明
在完成IBM DS4800告警功能設定後,一旦發生異常狀況時便主動發信通知系統一線、二線人員和廠商系統工程師。下圖為告警信件內容,系統一線人員可至DS4800管理介面進行確認,再通知廠商硬體工程師到場換修。
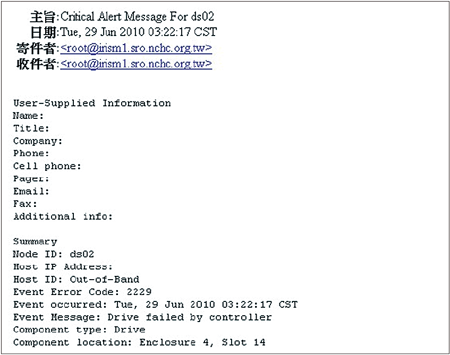 |
| ▲IBM DS4800儲存系統告警信件內容。 |
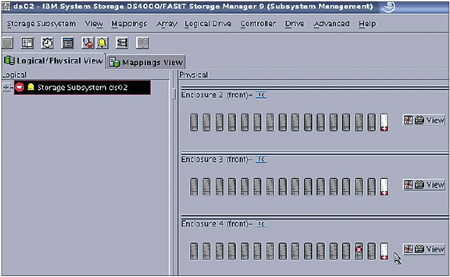 |
| ▲IBM DS4800管理介面。 |
表3為儲存子系統異常事件統計,大多為硬碟故障問題,平均每41天就有1顆硬體故障,如未能及時修復,2009年桃園機場的36小時電腦大當機就會出現在國網中心。
高速InfiniBand網路監控機制
高速InfiniBand網路監控機制的運作方式是自行撰寫shell script,在管理節點上以cron job方式,每4小時執行一次,測試未被使用的計算節點是否可正常執行mpi工作,並將問題節點抽出,以免使用者程式進入該節點後因無法執行而中斷。一線人員在收到通知後,先進行初步故障排除,如屬硬體損壞,則通報廠商維修。
說明
國網中心的使用者是透過IBM Loadleveler排程軟體將工作送到計算節點上執行。如果某節點的InfiniBand卡異常,所造成的衝擊要比該節點當機還要多上數十倍。