隨著半導體科技的進步,大型叢集運算系統也應運而生。國家高速網路與計算中心(簡稱國網中心)在2006年便開始規劃建置的新一代高速計算平台,並於2007年9月1日正式上線供國網中心計算用戶使用。
舉例來說,下頁圖示為當時使用者工作執行狀況,其中點狀線為正在排隊工作所需要的總CPU數,下方曲線則為正在執行工作所使用的總CPU數。此時點狀線如同瀑布一般,一瀉而下,這好比一群人在跑步,路面上突然出現一個石頭,不僅第一個踢到人會跌倒,連後面的人也可能會受到影響。
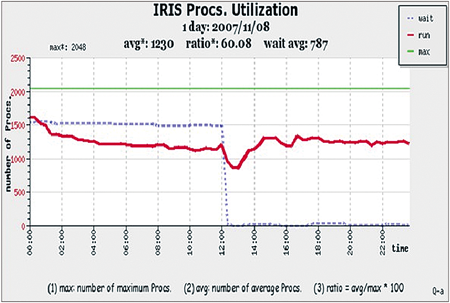 |
| ▲改善前使用者工作執行狀況 |
要避免這種情形,只要將石頭移開即可。當監控機制完成後,這種現象就不再出現,而系統使用率也由60%提升到96%。
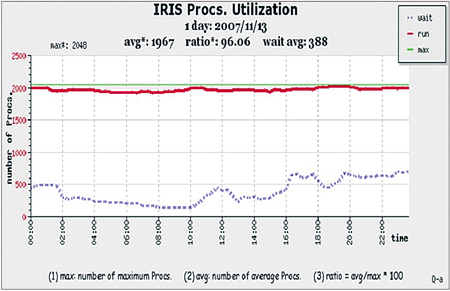 |
| ▲改善後使用者工作執行狀況 |
表4則為高速InfiniBand網路子系統異常事件統計,看來這部分的硬體故障率還算蠻低的。
異常連線監測機制
異常連線監測機制的運作方式也是自行撰寫shell script,在管理節點上以cron job方式,每天00:01執行,將前一天所有節點連線紀錄寄給系統一線和二線人員,檢查是否有異常連線紀錄。
說明
為了避免使用者不使用Loadleveler,直接將工作送到計算節點上執行,或是有心人士貪圖這麼大的計算資源,利用IBM CSM的dsh及Linux的last,便可以收集到每個節點的連線紀錄。以下為每日各節點連線紀錄部分內容。
節點異常紀錄監測機制
節點異常紀錄監測機制的運作方式同樣為自行撰寫shell script,在irism1上以cron job方式,每天1:20執行,將前一天所有節點reventlog記錄寄給系統一線和二線人員,一線人員依據這些訊息至機房確認該節點是否有硬體故障情形。
說明
利用IBM CSM的dsh及reventlog指令便可以收集到所有節點前一天的異常紀錄,包含硬碟、記憶體、溫度或關機紀錄。以下為reventlog紀錄部分內容。
計算節點上異常工作監控機制
計算節點上異常工作監控機制的運作方式為自行撰寫shell script,在irism1上以cron job方式,每4小時檢查並清除計算節點上未透過Loadleveler派送或不受Loadleveler控管的process,並將執行結果寄給系統一線和二線人員。如果仍然有存在無法清除的process,一線人員則須登入問題節點以手動方式清除。
說明
當計算節點上存在著未經由Loadleveler派送或不受其控管的process,將影響正常派送工作之執行效能或佔用軟體License數量,導致工作執行時間變長或無法執行。本監控程式主要利用IBM CSM的dsh及Loadleveler的llq、llstatus指令,檢查出異常工作並加以清除。
結語
一套大型的叢集運算系統要能夠持續穩定運作,確保服務不中斷,除了事前完善的備援規劃,適當的監控機制,也是十分重要的。而在建置監控系統前,先詢問硬體廠商是否提供類似的管理工具,不但可以精確地掌握系統狀況,同時也能減少程式開發的時間。
對於系統經常發生的問題,如現有監控機制無法處理的話,則必須另外增加監測和監控機制以解決這類狀況。網路上也有一些叢集運算系統的監視程式,使用前請先評估這些軟體是否能得到什麼協助,一味相信它所提供的訊息,不僅浪費寶貴的系統資源,還可能會錯失事件處理的先機。
(本文原載於網管人第60期)