EMC ScaleIO這幾年不斷地演進改善,已能滿足複雜的企業流程需求,而且其效能校調設計出許多配套方式,可結合現有架構來達到效能最佳化。本文將透過實作來示範其中Elasticity、Self-healing兩項實測。
第二個實驗則創建一個1TB的空間並調為Thin Provisioning,結果並沒有直接切割空間來使用,仍保持原來的10.1TB。因為Thin Provisioning是當未來有檔案加入時,才會按照實際使用量扣除可用空間,如圖24與圖25所示。
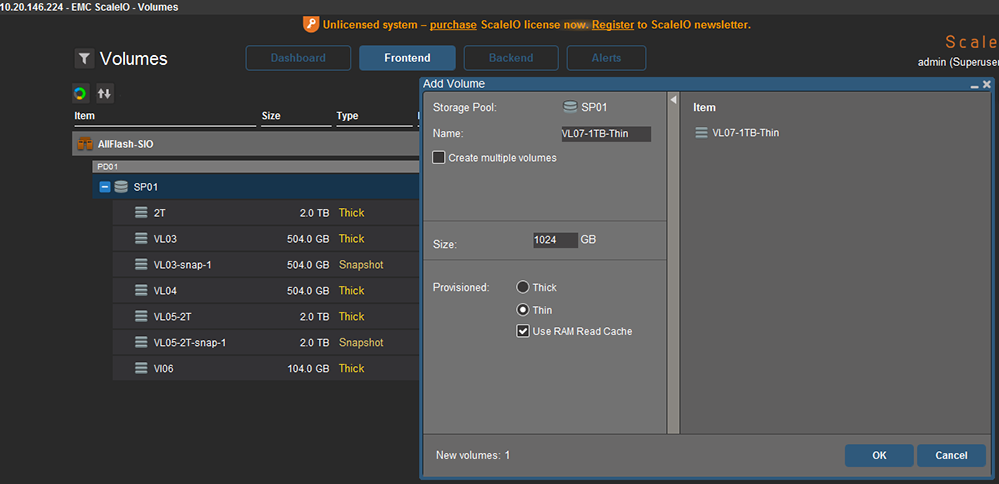 |
| ▲圖24 建立新的Volume配置為Thin。 |
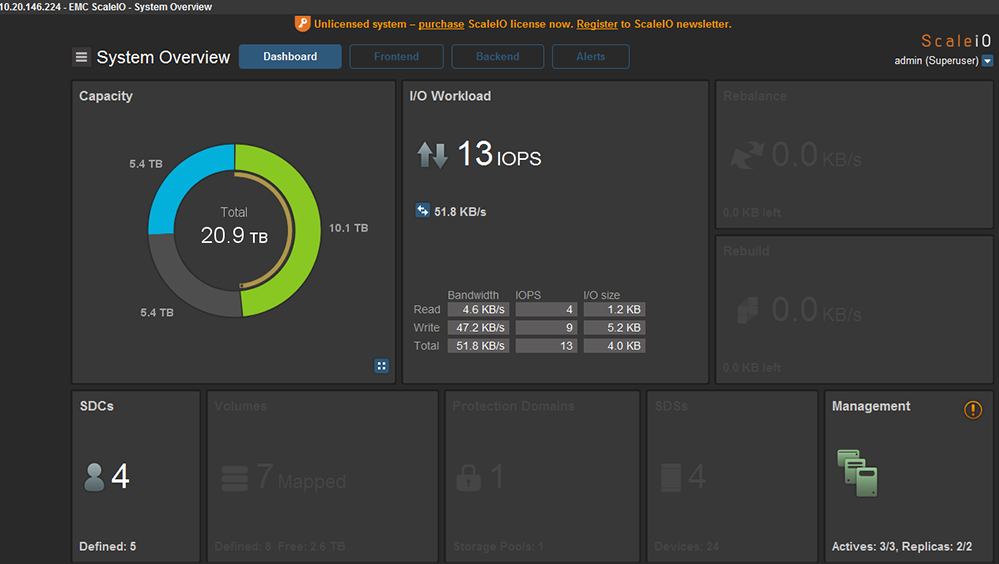 |
| ▲圖25 使用Thin Provisioning的Volume總容量保持在10.1TB。 |
ScaleIO功能實作 證明自我修復力
以下是四種ScaleIO功能的實作,分別加以說明。
Self-healing(Rebuild & Rebalance)
強大的自主能力(Self-healing)可分為Rebuild與Rebalance,皆可實現系統的高可用性及安全性。當ScaleIO擴充節點數量或是增加硬碟,Rebalance就會啟動,系統會分散所有資料,使每個儲存單元都是平均存量。如果是節點變少,也會平均讓儲存量一致,以下簡單模擬並驗證Self-healing功效。
Self-healing
系統面臨節點故障或網路失效時,SDS的Self-healing就會即時發揮功效。在傳統資料保護的方式有RAID和Replication,然而SDS最常使用的保護就是Replication,預設所有的資料隨機儲存成兩份放在現有的儲存媒體中,若其中一份有問題或遺失,Mete Data Manager(以下簡稱MDM)會幫忙把資料運算回來,讓系統永遠保有兩份副本,系統會參照自行設定的Replication Value還原資料應有狀態值,這個動作在ScaleIO裡稱為Rebuild。
Rebuild
Rebluid的操作步驟是,首先模擬一台主機毀損,手動把10.20.146.215主機關機,如圖26所示。
 |
| ▲圖26 模擬10.20.146.215節點毀損。 |
回到GUI後已經發現一台MDM消失,Cluster已亮起紅燈,代表MDM沒有備援。此時系統會立刻採取Rebuild動作,以確保兩份副本。
接著觀察Capacity有四分之一圈橘色的資料正等待運算,這意謂10.20.146.215主機關機造成整個副本數不足為二,如圖27所示,但實際上原本的資料已打散在各個主機中,所以至少都還有一份資料可供存取不影響現況。
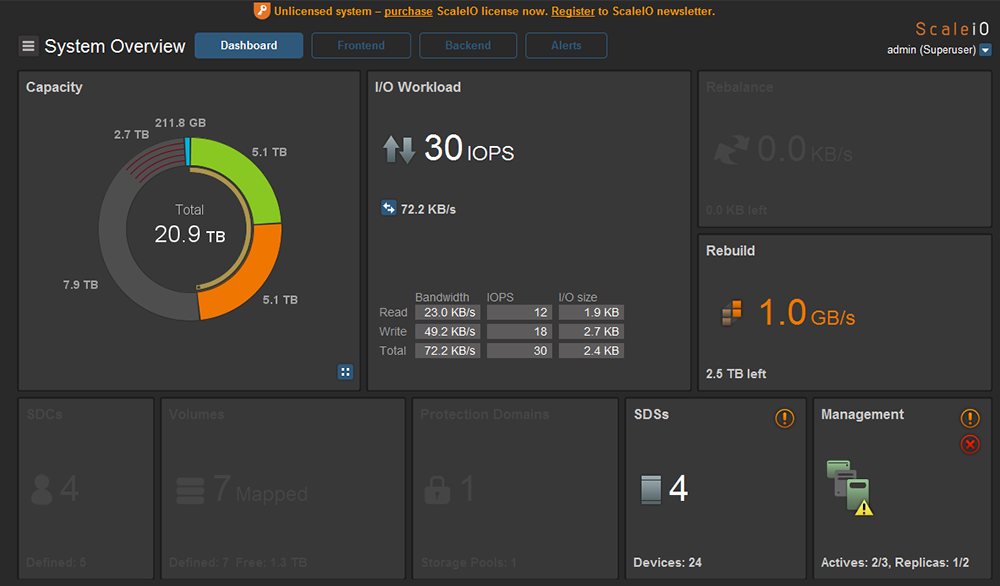 |
| ▲圖27 MDM角色三缺一,並且副本不足二份。 |
隨後觀察Backend的Overview處理,清楚得知由10.20.146.215主機遺失的資料部分正重新運算到其他三台主機,如圖28所示。
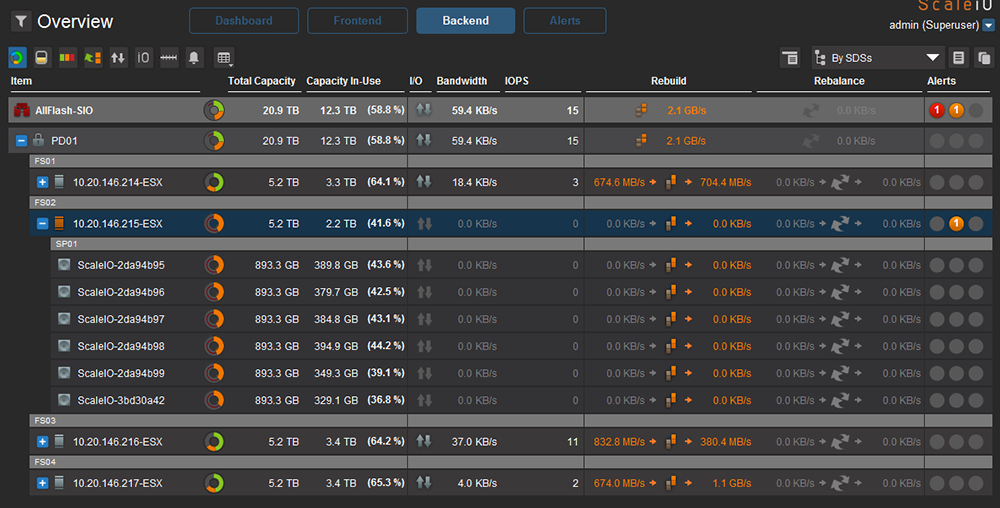 |
| ▲圖28 Overview檢視Rebuild已觸發。 |
Capacity Usage檢視能夠讓操作者清楚每個節點重建資料還剩餘多少百分比,10.20.146.215正逐漸將它毀壞的資料與副本建立在其他節點上,如圖29所示。
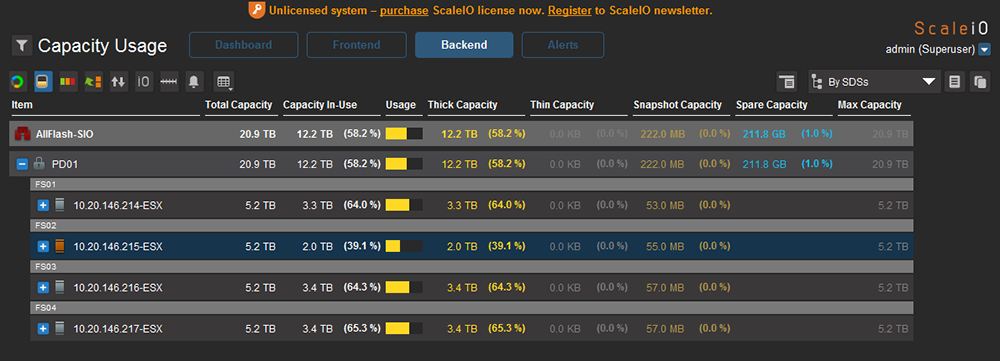 |
| ▲圖29 Capacity Usage可檢視百分比的情況。 |
而Capacity Health檢視是更偏向圖形化的呈現,注意右邊的箭號是將資料釋放,而左邊的箭號是將資料倒入,如圖30所示。
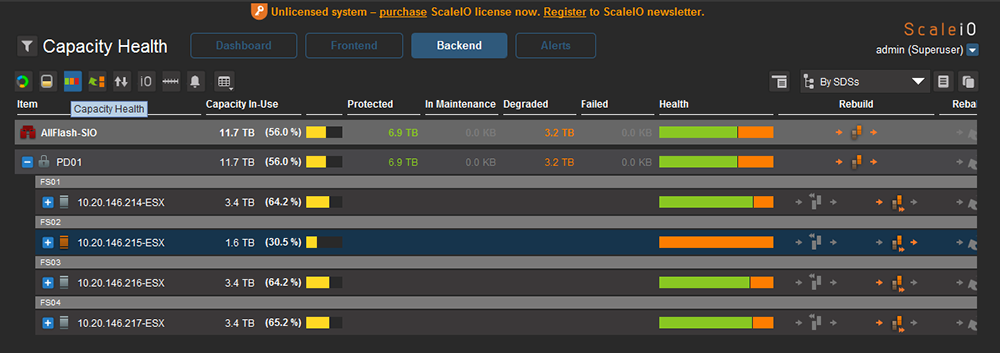 |
| ▲圖30 Capacity Health檢視。 |
比較圖30與圖31,10.20.146.215節點已逐漸將資料完整複製到另外三個節點。
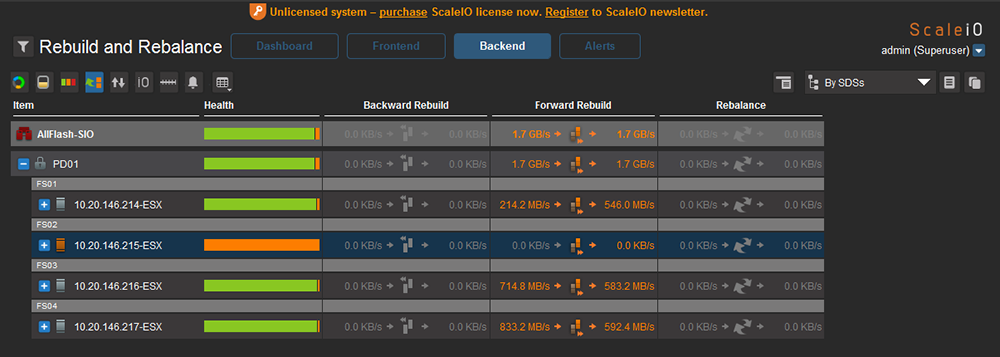 |
| ▲圖31 系統已快完成Rebuild動作。 |
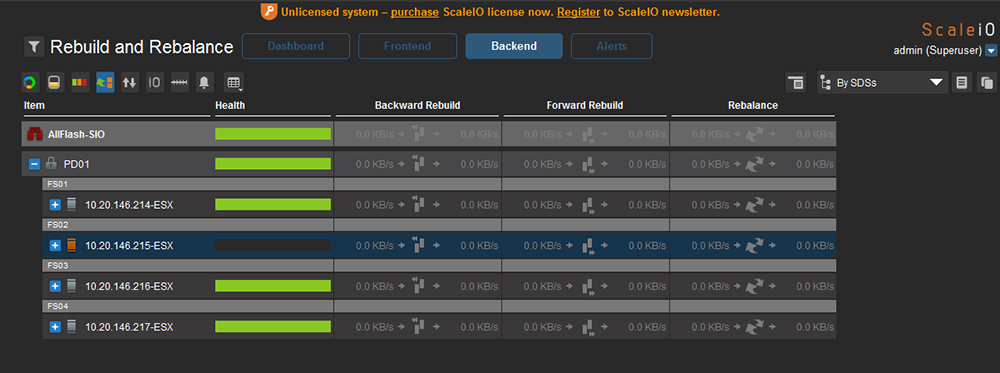 |
| ▲圖32 完成Rebuild動作。 |
最後,如圖32所示,Health由原本橘色情況變為全綠(請見框線部分),代表10.20.146.215節點將所有已存資料完整複製到另外三個節點,簡單來說,現在三個節點的ScaleIO均滿足兩份副本且可以再允許一個節點失效。
Rebalance
上一個範例是透過關閉其中一個vSphere節點來觸發Rebuild的功用,現在介紹SDS另一個重要功能「Rebalance」,其重要性顧名思義是要讓每個節點的儲存量平均。
先思考幾個問題:首先如果存量不平衡會產生哪些情形?再者什麼時候需要做Balance?想到了嗎?背後的意涵是要善用每個節點上的空間,讓Storage發揮最大效益。
Rebalance作用是讓恢復的節點或重新加入的節點,平均現有節點內所有的資料並且滿足兩份副本,這是ScaleIO基本保護原則。當然也可以再細看條件,還記得Fault Set的定義嗎?系統還會根據Fault Set領域來分離副本於同一個定義的Fault Set裡面。首先,回復已斷線的10.20.146.215節點,如圖33所示。
 |
| ▲圖33 重新啟動10.20.146.215節點。 |
再回來看GUI,圖34區塊內的Device皆為橘色,官方定義為Degraded(可譯為被降級的)。或許在傳統RAID1保護也曾看過Degraded代表鏡像(Mirror)保護沒有滿足,原因就是因為少了一份副本。
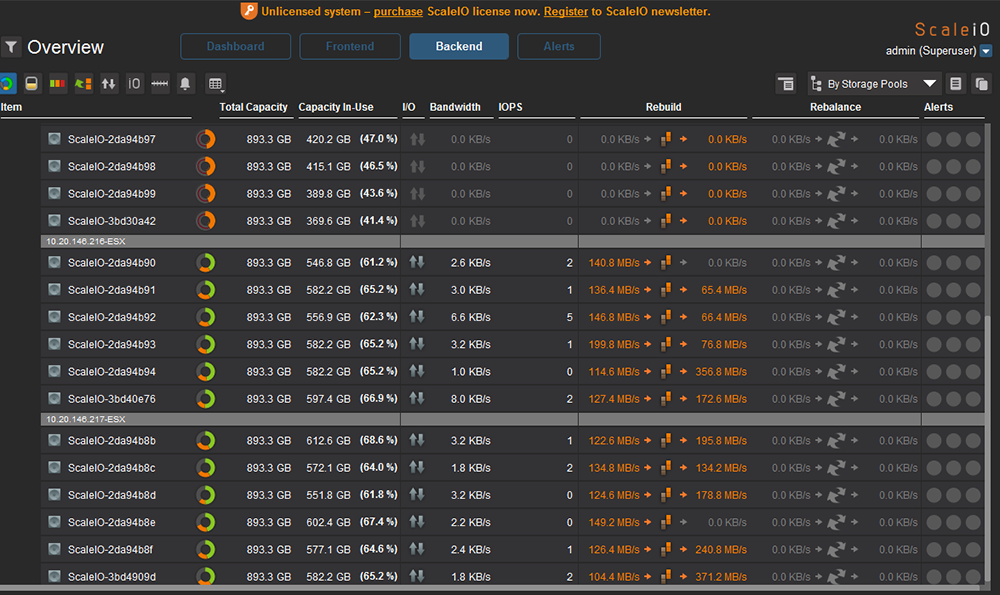 |
| ▲圖34 觀察10.20.146.215節點均為橘色,代表副本數量不一致。 |
如圖35所示,GUI顯示正在進行Rebalance動作,因為系統沒有滿足雙副本,所以演算法會讓所有的原則達到標準。最後切換到Overicew或Capacity Usage頁面,觀察到所有節點均為綠色,代表Rebalance作業均已完成,如圖36所示。
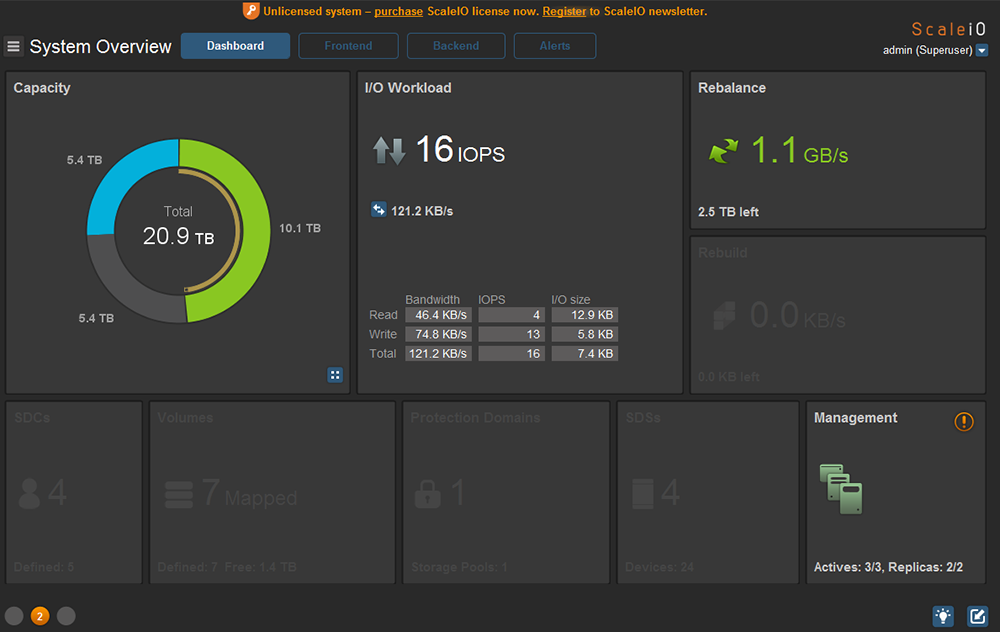 |
| ▲圖35 進行Rebalance動作。 |
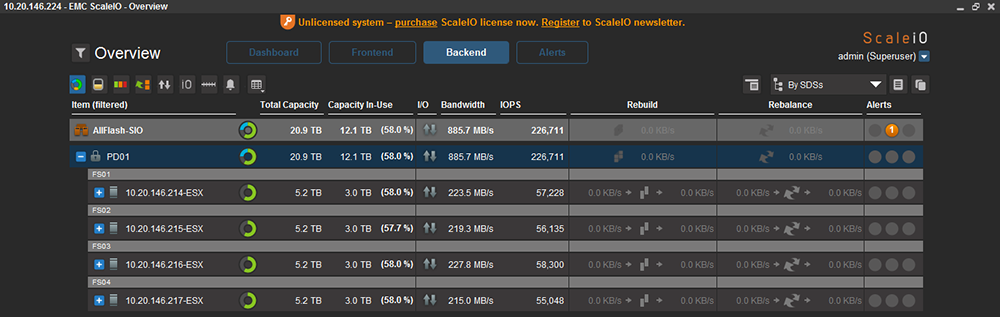 |
| ▲圖36 完成Rebalance動作。 |
結語
ScaleIO經過幾年的演進,愈來愈能滿足複雜的企業流程需求,特別是效能校調設計出許多方案配套,結合現有架構來達到效能最佳化,因此沒有絕對最佳的架構,而是經過時間不斷調校成適合的架構才是最終選擇。本文分享原本包含Elasticity、Self-healing、Performance、Data Protection、QoS,但因版面有限僅呈現前兩項實測,而下一期會再繼續為大家介紹Performance、Data Protection、QoS管理更詳細的實作。
<本文作者:黃明偉,任職於QCT雲達科技,經歷Networking、vSphere、VMware VDI、EMC VNX,目前從事雲端應用服務研究,接觸各大廠軟體定義式儲存解決方案SDS Solution。>