本文延續上篇的內容,進一步討論資料治理。在掌握資料治理的基礎後,該如何在不同資料來源中運用正確的資料授權模型。最後,以使用檢索增強生成(RAG)架構為例,說明實務上如何在生成式AI應用程式中執行資料授權機制。
在上篇文章中,深入探討在生成式AI應用程式中使用敏感資料的風險,並說明在不確定性大型語言模型(LLM)中使用敏感資料的各種挑戰,以及如何透過Amazon Bedrock Agents來降低相關風險。接下來,需要思考另一個問題:在LLM訓練、微調、向量資料庫、代理(Agents)與工具(Tooling)等環節中,該如何使用敏感資料?
本篇文章將延續上篇的內容,進一步討論資料治理。掌握資料治理的基礎後,應如何在不同資料來源中運用正確的資料授權模型。最後,將以使用檢索增強生成(RAG)架構為例,說明實務上如何在生成式AI應用程式中執行資料授權機制。
LLM的資料治理
本文將比上篇更深入探討資料治理在資料安全中扮演的角色。傳統工作負載多半依賴結構化資料儲存作為資料來源,如關聯式資料庫。相較之下,建構生成式AI應用程式的一大優勢,在於能從大量結構化與非結構化資料(例如系統日誌、文件、倉儲資料等來源)發掘洞察。
過去,通常只有特定的應用程式能存取非結構化資料,且只有授權的使用者可讀取資料。在這樣的架構中,前端應用程式須判斷使用者是否有權存取資料,並使用統一的AWS Identity and Access Management(IAM)角色來授權後端的資料存取,包含物件儲存、資料倉儲或其他資料來源。使用者是否能存取資料,或只能存取一部分資料,取決於前端應用程式的授權判斷。針對這類需求,AWS提供多種與使用者身分綁定的存取模式,包括AWS可信任身分傳遞(AWS Trusted Identity Propagation)與Amazon Simple Storage Service(Amazon S3)存取授權(Access Grants)。
當希望在生成式AI應用程式中整合多種資料來源時,資料存取管理也隨之變得更加困難。原因在於企業通常難以全面掌握資料的分布位置,也就無法確定資料來源是否包含敏感資訊。尤其資料橫跨不同位置、部門與系統,許多組織實際上不清楚每個資料來源中包含什麼資料。若不了解擁有什麼樣的資料,自然難以制定適當的授權政策來管控存取,甚至無法判斷該資料來源是否該被用於生成式AI應用程式中。
從資料治理的角度來看,應從四大面向全面檢視:資料可見度(Data Visibility)、存取控制(Access Control)、品質保證(Quality Assurance)以及資料擁有權(Ownership)。例如資料來源是否包含客戶資料?是否屬於內部資料?或是為兩者混合?資料來源是否需要移除特定檔案或文件,以符合應用程式的業務目標?若應用程式具備多層級授權需求,誰該被授權存取哪一層級的資料?對此,AWS提供多項服務,例如AWS Glue、Amazon DataZone與AWS Lake Formation,協助企業強化生成式AI應用程式中的資料治理,進而實施資料授權機制。
然而,企業該如何安全地將敏感資料整合到生成式AI應用中?接下來,將依序說明敏感資料可能出現的幾個位置,包括LLM訓練與微調、向量資料庫、工具與代理。
LLM訓練與微調
在生成式AI應用程式中,敏感資料可能出現的第一個位置是LLM本身。目前大多數的基礎模型(FM)與LLM皆由第三方組織開發,例如Anthropic、Cohere、Meta及其他模型供應商。這些模型規模日漸擴大,訓練資料涵蓋數兆筆資料點,內容除了來自公開資料,也包含其他LLM產生的合成資料(Synthetic Data)。然而,基於隱私與專利考量,多數模型供應商不會公開訓練資料來源。這些由第三方訓練的基礎模型不會使用我們的私人資料,但若企業規模夠大,可能會自行訓練專屬模型,或在既有模型上進行微調,並使用敏感資料、授權資料與公開資料來滿足特定業務需求,這樣的方式能夠主動決定要將什麼資料用於模型訓練。
然而,如同上篇文章所提,LLM本身不具備資料授權判斷的能力,這也使得對不同使用者群體進行權限管控變得更具挑戰。是否允許使用者調用模型,應該由應用程式負責進行授權決策。此外,若希望將資料從LLM中移除,目前唯一的方式是重新訓練模型,並排除該筆資料。儘管可透過微調與提示工程(Prompt Engineering)來影響模型的回應內容,但只要資料已用於訓練或微調階段,任何有存取權限的使用者都可能從模型回應中取得這些資料。因此,若選擇對既有模型進行微調,必須謹慎選擇訓練資料來源。若訓練過程中使用專利資料,這些資料在模型推論時可能會被外部存取。因此,建議在訓練前應審慎評估資料內容,移除所有個人身分識別資訊(PII)或任何需額外授權才能存取的資料。
值得注意的是,目前已經有部分LLM防護機制(Guardrails)支援負責任AI(Responsible AI)原則。例如,Amazon Bedrock Guardrails能自動從提示詞與模型回應中移除特定內容,包含違規主題、關鍵字過濾或PII資訊等。不過,這類防護機制本身具有不確定性,主要用途是過濾有害內容,並不適合作為主要的資料授權機制。
重要提醒:企業不應將資料安全完全依賴於Guardrails或模型內建防護機制這類的負責任AI功能,因為這些機制並未將使用者身分納入過濾條件。
檢索增強生成(RAG)
生成式AI應用程式中,敏感資料可能出現的第二個位置是向量資料庫。透過RAG架構,企業可以讓生成式AI應用程式讀取私人資料來源中的情境資訊(Contextual Information),進而讓LLM回應內容更加準確、相關、客製化,而無須將私人資料直接用於模型訓練或微調。RAG的運作原理,是將提示詞中缺乏的背景資訊補足後再傳送給LLM。當生成式AI應用程式使用RAG架構時,系統會先查詢向量資料庫,找出與使用者提示詞語意相近的文件或內容片段,這些檢索獲得的資料將與原始提示詞一起送往LLM,作為輸入上下文的一部分。在AWS的服務中,RAG可以透過Amazon Bedrock Knowledge Bases與Amazon Q Connectors來進行。
圖1為結合向量資料庫與模型所構成的RAG執行流程示意圖。使用者對生成式AI應用程式提出請求時,系統會將提示詞轉換為嵌入向量(Embeddings),並用來查詢向量資料庫中語意相近的內容。這些文件或資料片段將與原始提示詞合併,送往LLM中以生成最終回應。
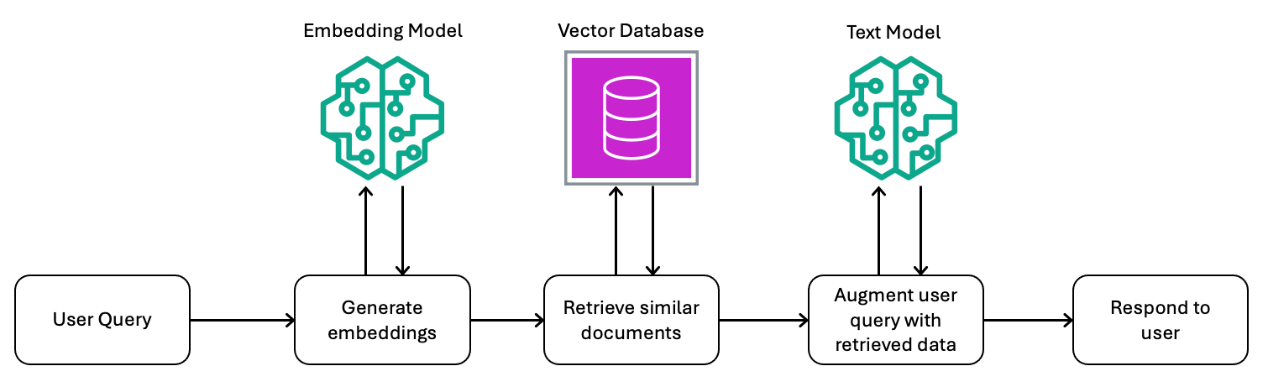 圖1 RAG執行流程示意圖。
圖1 RAG執行流程示意圖。
若希望在RAG架構中實施強化的資料授權,關鍵在將額外內容作為提示詞上下文傳送至LLM之前,先完成資料的授權檢查。這種授權機制可以在生成式AI應用程式或向量資料庫進行。透過RAG,可以在應用程式中設計專屬的授權流程,並依需求實施不同層級的授權。例如,若授權存取向量資料庫,則只要有權使用應用程式的使用者,也能存取向量資料庫中的所有文件。換言之,若企業內部有兩個部門(如財務部門與人資部門),可以為這兩個部門建立各自的向量資料庫。具有財務部門權限的使用者,可以存取財務向量資料,但無權存取人資部門的資料,反之亦然。
也可以進一步實施向量資料庫內部的細緻授權控管。在某些部署情境中,若同一個向量資料庫中同時儲存多個使用者群組的文件,則每一次對向量資料庫的API調用,都必須包含使用者的群組資訊。舉例來說,若人資部門的員工只能存取資料庫中的特定文件,則無論是應用程式或向量資料庫,都必須在回應查詢結果前,先驗證使用者是否具備相對應的存取權限。
在Amazon Bedrock Knowledge Bases中,企業可以透過retrievalConfiguration這個API欄位,於調用時加入metadata(中繼資料)欄位,進而實施文件層級的授權過濾。這類中繼資料採用key/value形式,資料庫能依據這些欄位內容進行結果篩選,運作邏輯與使用者群組授權類似。由於中繼資料過濾是API調用的一部分,而非提示詞的一部分,因此攻擊者無法透過提示詞注入(Prompt Injection)繞過授權限制,取得未授權的資料內容。這項授權會與應用程式傳送的使用者身分資訊綁定,並與執行RAG的中繼資料過濾結合運作。
若希望建構安全可靠的RAG架構,必須導入正確的授權與資料治理機制。傳送至LLM的資料,應僅限使用者有權存取的內容。由於LLM與Guardrails屬於機率式(Probabilistic)技術,因此不應作為資料授權判斷的依據。
工具
生成式AI應用程式中,第三種與敏感資料互動的常見模式,是函數或工具調用(Function or Tool Calling)。在這種模式下,LLM不會直接調用工具,而是在使用者提出查詢請求時,附帶一個或多個工具的說明,以協助LLM生成回應。若LLM判斷需要使用某個工具來生成回應,就會回傳請求要應用程式調用工具,同時提供需輸入的參數。接下來,生成式AI應用程式會代表LLM呼叫工具,例如執行一個API、AWS Lambda函數或其他軟體。應用程式會將工具的執行結果作為提示詞的一部分回傳給LLM,接著LLM便根據新資料生成回應。圖2為這種執行流程的示意圖。
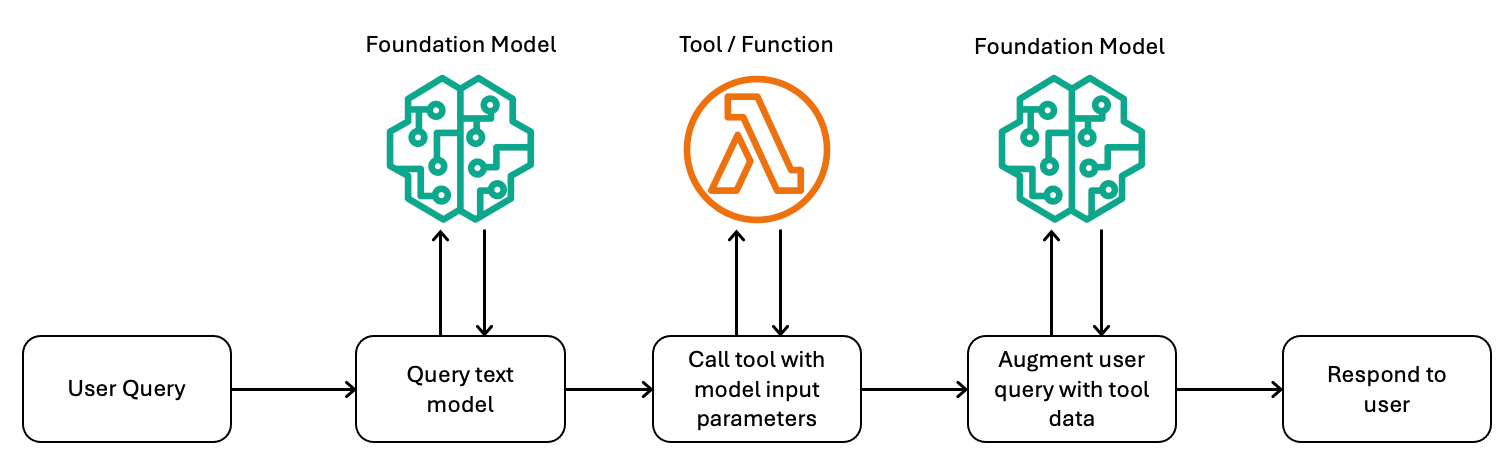 圖2 工具執行流程示意圖。
圖2 工具執行流程示意圖。
儘管由LLM判斷是否使用工具,但安全控管與授權判斷必須由應用程式執行。應用程式要針對LLM回傳的輸入參數進行驗證,評估什麼工具可被調用、工具具備什麼權限、允許執行什麼動作。傳統的資安機制在此仍然適用,例如在執行工具的環境應設置沙箱(Sandbox)以隔離副作用,避免干擾後續執行。此外,LLM產生的工具輸入參數也應經過清洗處理(Sanitized),以防止潛在的權限提升(Privilege Escalation)或遠端程式碼執行(Remote Code Execution)等資安風險。
如同先前介紹的RAG架構,工具的授權應由應用程式決定。企業可以在應用程式層級、群組層級或使用者層級,設計適當的授權機制,或透過身分憑證(Identity Token)將授權資訊傳送至工具端,這種設計在上篇文章的代理段落已有說明。透過這些機制,可以在同一個工具調用流程中使用多種不同資料集,包括敏感資料與公開資料。然而,如同現行的API授權原則,生成式AI應用程式中的授權決策應基於使用者身分,並在每次調用工具時進行驗證。我們一再強調,企業不該讓LLM判斷使用者擁有的資料存取權限,否則可能導致過度授權等安全風險。
代理 在上篇文章詳細說明代理的運作邏輯,現在將進一步探討如何透過代理整合多個來源的資料。代理的核心作用,是協助使用者根據輸入與提供給模型的資料,完成一連串的多步驟動作。這些代理(例如Amazon Bedrock Agents)能在LLM、資料來源(如RAG)、軟體應用程式(如工具)與使用者互動之間扮演協調者。在使用代理時,可以選擇一個LLM作為代理的核心模型,負責解析提示詞並根據執行過程中的需求進行後續的提示詞處理與回應。可以為代理設定一系列動作,例如向使用者提出進一步問題以釐清需求、調用API進行功能操作,或透過RAG從知識庫補足相關背景資訊。這些動作將在代理的協調流程中依序執行,可能包含許多不同步驟,直到成功回應使用者的原始查詢。如圖3所示,代理會組合上述元件並建立基礎提示詞,進而驅動整個協調流程,直到請求完成。
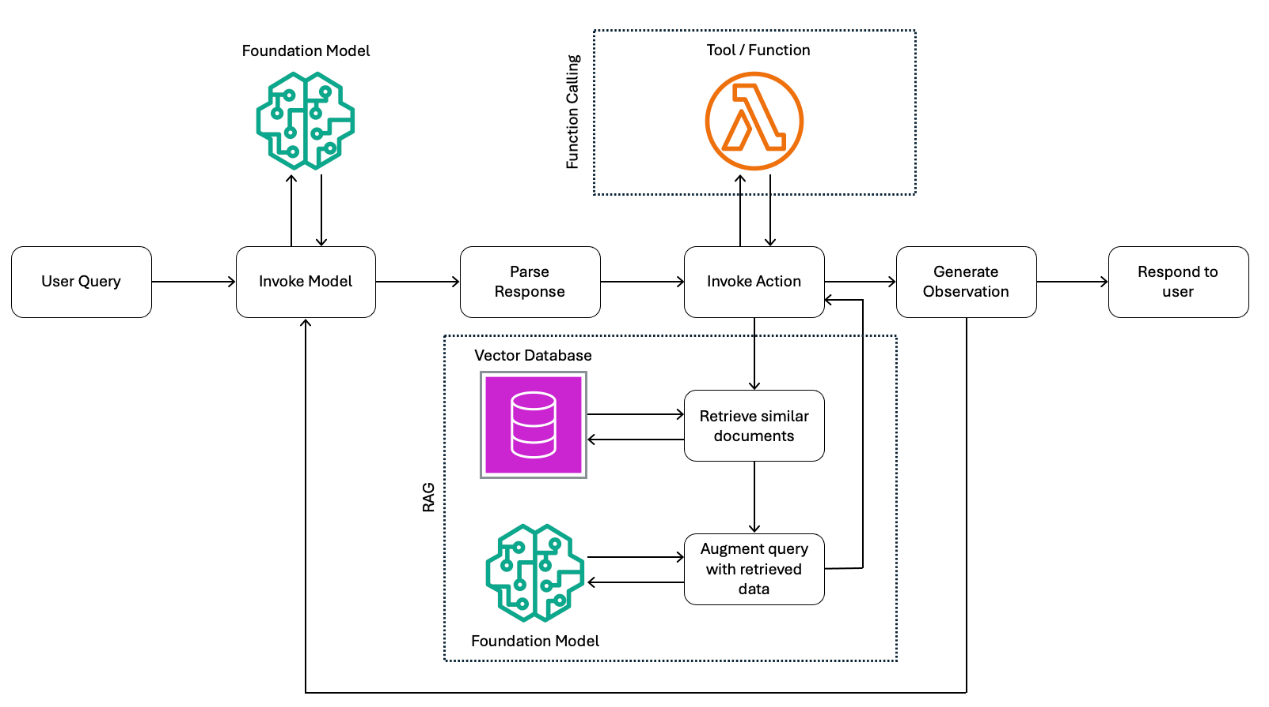 圖3 代理執行流程示意圖。
圖3 代理執行流程示意圖。
代理使用外部資料來源時,除了前述的資料授權判斷外,還須留意幾項額外的安全考量。首先,為了讓代理在調用資料來源時使用正確的授權上下文,必須在對代理進行API調用時一併傳送使用者的身分識別資訊。在Amazon Bedrock Agents中,這項身分資訊能透過工具的工作階段屬性(Session Attributes)或向量資料庫的中繼資料過濾傳送,並作為代理調用各種資料來源的重要依據。
其次,代理的目的是代表使用者執行任務。與RAG著重於「讀取資料」不同,代理常涉及「資料變更」,例如透過API調用來新增、更新或刪除資料,因此在授權設計上必須更加謹慎。企業在建構代理的執行流程時,務必仔細評估每一項授權配置,確保只有具備權限的使用者能觸發相對應的操作。
此外,企業也可以考慮為代理的工作流程加入驗證步驟,例如在代理修改資料或執行API調用前,先將執行結果交給使用者確認。這種設計能強化資料操作的透明度與安全性,避免代理自動執行的結果超出授權範圍。
至此,已逐一說明企業該如何在生成式AI應用程式中運用各類資料與執行位置,接下來將透過一個具體範例,展示如何在RAG架構中執行資料過濾與授權控制。
RAG中的資料過濾與授權
假設正為企業內部建構一個生成式AI應用程式,用以查詢各種政策與歷史紀錄。這個應用程式採用RAG架構,並以單一的Amazon S3資料來源作為向量資料庫,包含財務部門與人資部門的相關文件。在這個簡化範例中,使用者希望查詢工作所需的SECRET_KEY。每個部門都有各自獨立的SECRET_KEY,僅限部門成員可以存取。S3儲存貯體即為Amazon Bedrock知識庫的資料來源,而生成式AI應用程式則透過知識庫讀取資料。整體架構如圖4所示。
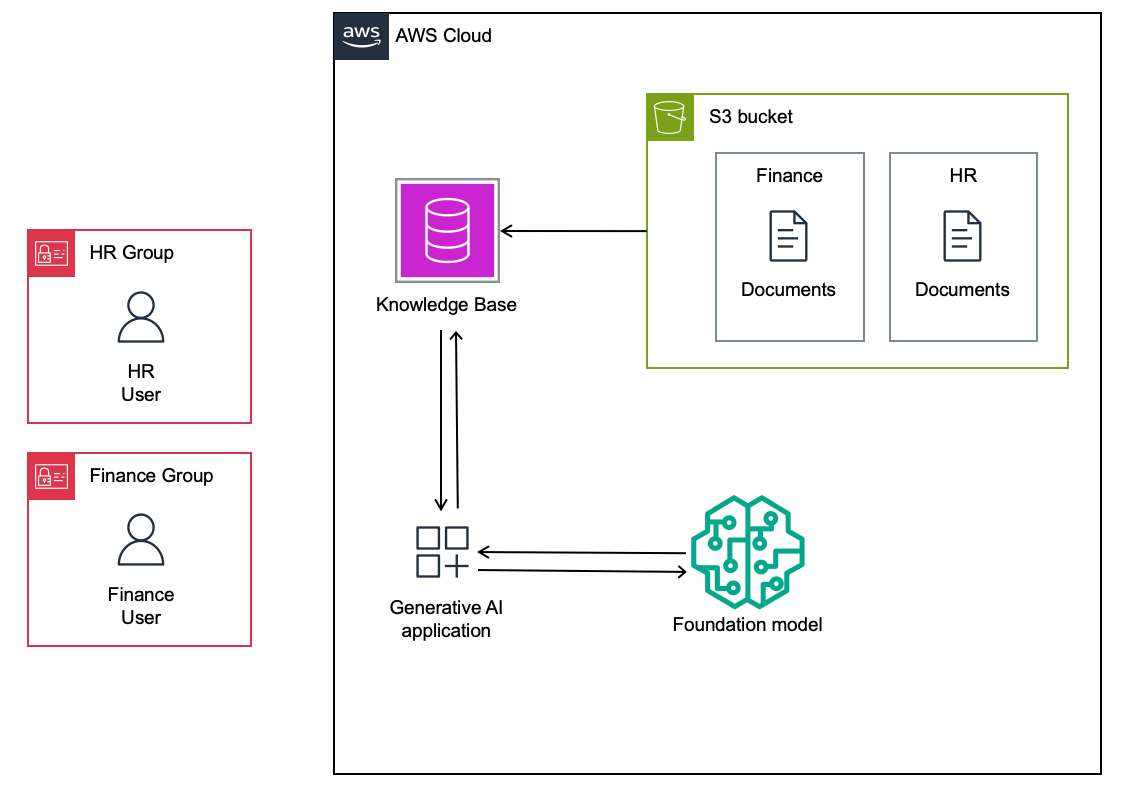 圖4 財務與人資部門使用者存取生成式AI應用程式的架構示意圖。
圖4 財務與人資部門使用者存取生成式AI應用程式的架構示意圖。
在這個架構中,應用程式可以透過Retrieve API調用Amazon Bedrock知識庫,並將結果回傳給生成式AI應用程式。與之不同,RetrieveAndGenerate API是將查詢結果與提示詞一起回傳LLM,應用程式要到LLM回應後才知道知識庫查詢的結果。若未實施任何資料授權機制,當人資部門的使用者查詢應用程式時,Retrieve API調用會從S3對應目錄中同時回傳財務部門與人資部門的SECRET_KEY。
然而,根據企業內部政策,財務部門與人資部門都不希望其他部門的使用者能存取專屬的S3資料,包括員工個人身分識別資訊(PII)、尚未公開的財務資料、內部人資政策等僅限部門成員使用的內容。那麼,該如何根據前文所述原則,實施正確的資料授權控管機制呢?
第一種方式是建立兩個獨立的向量資料庫,一個供財務部門使用、一個供人資部門使用。當財務部門使用者登入生成式AI應用程式時,應用程式僅會從財務部門的向量資料庫擷取資料,因為使用者無權存取人資部門的資料。反之亦然,人資部門的使用者也只能存取對應的人資向量資料庫。
第二種方式是使用共用的向量資料庫,雖然包含兩個部門的共用資料與敏感資料,但透過中繼資料過濾機制,生成式AI應用程式能在向量資料庫層級篩選提示詞所需的上下文資料。當在S3中的物件加上對應的*.metadata.json中繼資料檔案後,就能在Amazon Bedrock的API調用中套用過濾條件,排除不符合授權條件的資料。例如,在S3儲存貯體中的hr.txt與finance.txt檔案分別新增hr.txt.metadata.json與finance.txt.metadata.json中繼資料檔案,當向量資料庫從S3建立索引時,會自動讀取並套用這些中繼資料,後續就能根據每個檔案帶有的中繼資料進行過濾。
當這兩個中繼資料檔案就緒後,重新建立知識庫索引,將對應的中繼資料套用至每個檔案。在調用知識庫的API中加入過濾條件時,系統只會回傳來自人資資料夾的內容,因為只有hr.txt物件被加上"group' : "HR"的中繼資料屬性。如此一來,生成式AI應用程式便可以將這些內容與使用者的提示詞一起傳送至LLM,讓使用者取得所屬部門對應的SECRET_KEY。
無論採用哪一種方式在資料來源中設定中繼資料,API調用中所使用的過濾條件,都是生成式AI應用程式完成授權判斷之後才會套用。使用者登入應用程式時,系統會透過OpenID Connect(OIDC)或OAuth2等標準驗證機制確認身分與部門,這個步驟是實施強化授權機制的前提。驗證完成後,應用程式會根據授權加上適當的過濾條件,並於後續調用Amazon Bedrock知識庫時一併套用。值得再次強調的是,資料授權的決策是在應用程式中完成的,而不是由LLM判斷,API調用是在已授權的前提下執行的。透過將中繼資料作為API的安全旁通道(Side Channel)傳送,而非納入提示詞中,可以有效防止惡意提示詞注入或未授權使用者擷取資料的風險。
結語
當企業在生成式AI應用程式中使用敏感資料時,導入正確的資料授權機制是不可或缺的基礎步驟。根據資料在架構中所處的位置不同,需要實施的授權方式也會有所差異,並不存在一套適用所有情況的解方。 本文逐一說明如何在各種資料來源(包含LLM訓練與微調、向量資料庫、工具與代理)妥善使用敏感資料,並搭配適當的資料授權模型進行控管。接著,也進一步說明如何透過中繼資料過濾機制,在生成式AI應用程式與RAG架構中實施資料授權流程。
<本文由謝世衡潤譯。謝世衡目前就職於亞馬遜旗下Amazon Web Services(AWS),擔任AWS台灣解決方案架構部的部門負責人。其致力於為客戶提供良好的雲端運算體驗,並曾成功協助多家大型企業導入雲端運算技術。擁有超過十八年的資訊科技產業經驗,曾擔任其他外商公司雲端架構師、行銷科技公司技術顧問,以及新創公司營運長等職務。除了雲端運算、數據分析和機器學習等技術領域,也對零售科技、軟體服務和企業IT營運等領域具有廣泛的知識和經驗。>