在美國試圖透過晶片禁令遏制中國AI發展的同時,中國正採取「以退為進」與「彎道超車」的策略,透過高品質的開源模型,試圖重現當年Android對抗iOS的輝煌,建立全球開發者所依賴的生態。這場關於開源與封閉、地緣政治與技術霸權的博弈,正重新定義AI的未來。
回想2023年,當ChatGPT席捲全球時,科技界普遍認為AI的未來屬於封閉式大型語言模型。然而,隨著Meta發布Llama系列,以及中國AI開源模型如雨後春筍般湧現,風向正在發生劇烈轉變。在美國試圖透過晶片禁令遏制中國AI發展的同時,中國正採取「以退為進」與「彎道超車」的策略,透過高品質的開源模型,試圖重現當年Android對抗iOS的輝煌,建立全球開發者所依賴的生態。這場關於開源與封閉、地緣政治與技術霸權的博弈,正重新定義AI的未來。對身處硬體供應鏈核心但軟體應用相對薄弱的台灣而言,既是巨大的挑戰,也是千載難逢的機會。
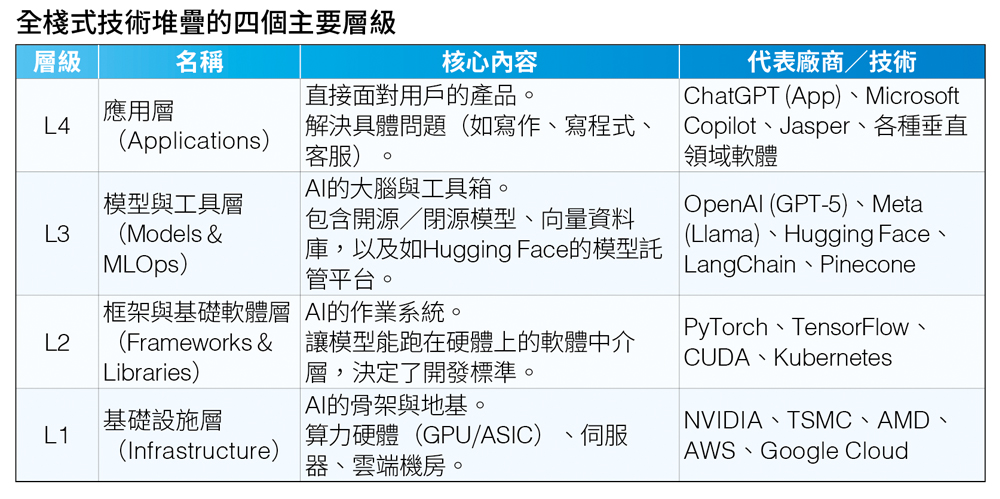
解構全棧式技術堆疊:以算力與數據為核心的開源競局
為了進一步解析開源在全棧式技術堆疊(AI Full Stack)所代表的意涵,可以歸納NVIDIA及相關研究機構的定義,由下而上分為四個主要層級,每一層都依賴下一層的支撐,而愈上層愈接近終端用戶。目前的獲利主要集中在L1(如賣鏟子的NVIDIA/TSMC等)。中間層與應用層(L2, L3, L4)競爭激烈,且正逐漸走向開源化或免費工具。
要理解這場戰爭,首先必須釐清「開源軟體」與「開源AI」的本質差異。在傳統軟體時代(如Linux、Apache等),開源意味著公開原始碼。開發者只要有電腦,就能編譯、修改並貢獻代碼,這是一種徹底的民主化。
然而,開源AI的定義要複雜得多,目前的「開源」大多僅指開放模型權重,即模型訓練後的參數。主要差異之處在於AI的核心壁壘不在於程式碼,而在於算力與數據。即便一家公司開源了模型權重,如果未公開訓練數據集和訓練過程,外部開發者很難真正「複製」或從底層「修改」該模型。因此,誰的模型成為基礎大模型,誰就能定義未來的API標準、工具鏈以及應用場景。
台灣的戰略:從「硬體軍火商」轉型「AI Factory」
根據英國Tortoise Media最新發表的Global AI Index調查顯示,台灣從2024年的第21名進步到2025年的第16名,雖然成績斐然,卻可以從這幾年細項中的排名找到我國AI發展的軟肋,其中包括高階AI人才的短缺、商業生態系韌性不足,以及技術開發能力待加強等。而這三項弱勢,都有機會透過開源AI作為突破口,包括「穩固Layer 1(基礎設施)、參與Layer 2(框架與軟體中介層)、善用Layer 3(開源資源)、發展Layer 4(垂直應用)」,其背後的戰略邏輯便是以「價值鏈的轉移」為中心。
L1是我們的「糧倉」,但利潤會被稀釋:雖然台灣現在靠台積電和伺服器廠賺得盆滿缽滿,但歷史經驗告訴我們,硬體最終會走向標準化,毛利率會下降。如果只做L1,我們永遠只是替Google或OpenAI打工的「軍火商」。
L2是「護城河」的建設:為什麼要滲透PyTorch Foundation?因為軟硬體協同設計是未來趨勢。如果未來的AI軟體標準不再原生支援台灣的ASIC晶片或Edge Device,台灣的硬體就可能變成難用的硬體。加入L2聯盟,是為了確保台灣硬體在未來的軟體生態系中不可或缺。 L3是「免費的槓桿」:美中科技巨頭花費數億美元訓練的Llama 3或Qwen等,一旦開源,對台灣來說就是接近零成本的研發基盤。我們不需要去造輪子(訓練基礎大模型),而是要拿別人的輪子來造車。
L4是「利潤的終點」:真正的超額利潤在於解決百工百業的痛點。台灣的策略應該是拿世界通用的L3模型,餵入台灣獨有的Domain Knowledge(如半導體製程、傳統製造業數據、健保資料等),訓練出不可替代的L4應用。
建構自主AI技術堆疊,在開源浪潮下可朝四個方向發展
建構自主AI技術堆疊,台灣在開源浪潮下可朝以下四個方向發展:
一、環境建構:打造「主權AI」與「算力公用設施」
台灣必須擁有一個基於繁體中文與台灣價值觀訓練的基礎模型,以防止文化與認知的偏誤。又台灣的算力集中在大型科技業者,政府應建立國家級的算力中心,以低廉或免費價格提供給學研界與新創,降低訓練與微調開源模型的門檻。
二、產業應用:製造業的「垂直整合」優勢
開源模型最大的貢獻在於可微調性,允許企業注入專有數據進行訓練,打造行業專屬大腦。台灣可利用世界級的製造數據,基於開源模型訓練專屬的「工業大腦」。或者,軟硬整合出海,販售預載特定行業AI模型的解決方案。
三、人才培育:從「程式設計師」轉向「AI架構師」
過去強調Coding的工程師,現在需要培育懂得Fine-tuning、RAG與Prompt Engineering的AI架構師。教育體系應鼓勵學生參與開源AI社群(如Hugging Face、GitHub等),學習如何拆解、修改並優化現有的開源模型。
四、國際接軌:加入標準組織與開源社群,卡位開源生態鏈
積極參與由Linux Foundation轄下的PyTorch Foundation,以掌握底層硬體優化標準,並爭取加入由IBM與Meta發起、包含Hugging Face及Linux Foundation等會員的AI Alliance,確保台灣在模型開源與治理規範上不至缺席。
根據MIT與Hugging Face 2025年的統計,在Hugging Face等開源平台上,過去一年中國模型約占全球下載量的17.1%,首次超過美國的15.8%。當中國正利用開源策略試圖突圍,對台灣而言,不應該僅僅自滿於提供底層的晶片與硬體設備,也不該只做最上層的消費者,而是應該利用開源模型結合台灣獨有的製造數據與硬體優勢,加工成為高附加價值的「產業AI解決方案」。這是一場通用與專用、閉源與開源以及LLM與SLM的競賽。台灣若能善用開源AI的槓桿,定能從「矽島」蛻變為真正的「人工智慧之島」。