本文將透過深入剖析和實戰演練,讓管理人員深入了解Nutanix叢集環境中的重要運作元件,包含PC和CVM運作規模的規劃以及Memory Overcommit機制,讓企業和組織能夠輕鬆打造出高效能和最佳化的Nutanix叢集。
在最新發布的Nutanix版本中,AOS和Prism Central(PC)的版本將會對齊,例如AOS 7.3和PC 7.3。至於AHV Hypervisor的部分,則會在次要版本對齊,例如AHV 10.3,讓企業和組織對於版本的選擇,可以快速且立即地判斷版本資訊。
在Nutanix AHV 10.3版本中推出「Automatic Cluster Selection」特色功能,有更多的功能性增強,進一步提升VM部署的智慧化與彈性。事實上,Automatic Cluster Selection特色功能,在AOS 6.8版本時便已經推出,但是在最新發布的Nutanix AHV 10.3版本中則增強許多特色功能。
那麼Automatic Cluster Selection特色功能的用途為何?簡單來說,它是Nutanix AHV虛擬化平台中的一項,針對VM虛擬主機部署的增強機制。當管理人員在Prism Central主控台中部署VM虛擬主機時,系統會根據多項資源條件進行判斷,自動選擇最適合運作該台VM虛擬主機的Nutanix叢集進行部署作業,如此一來,不僅簡化整體操作流程,也降低人為判斷而導致選擇錯誤的風險,如圖1所示。
 圖1 整合Automatic Cluster Selection機制的PC主控台情境判斷示意圖。 (圖片來源:AHV 10.3 - Automatic Cluster Selection for VM Placement | AHV Administration Guide)
圖1 整合Automatic Cluster Selection機制的PC主控台情境判斷示意圖。 (圖片來源:AHV 10.3 - Automatic Cluster Selection for VM Placement | AHV Administration Guide)
值得注意的是,Automatic Cluster Selection自動選擇機制僅僅是在VM虛擬主機一開始部署時,自動選擇適合的Nutanix叢集進行部署,一旦VM虛擬主機部署完成並開始運作後,叢集資源的負載平衡作業就會交由Acropolis Dynamic Scheduling(ADS)來負責。
最佳建議作法介紹
接著,介紹幾項最佳建議作法。
Memory Overcommit
在虛擬化基礎架構中,相信大家對於「Memory Overcommit」機制應該要非常熟悉才對,如圖2所示。簡單來說,在AHV虛擬化平台中,透過內建的Memory Overcommit機制,可以讓AHV虛擬化平台中運作的VM虛擬主機數量呈現線性增加。舉例來說,在Nutanix叢集中,其中一台叢集節點主機具備128GB實體記憶體,然而卻能夠運作10台甚至更多台,組態設定16GB vMemory的VM虛擬主機,這便是透過Memory Overcommit機制,達到虛擬化架構VM集縮比的功能之一。
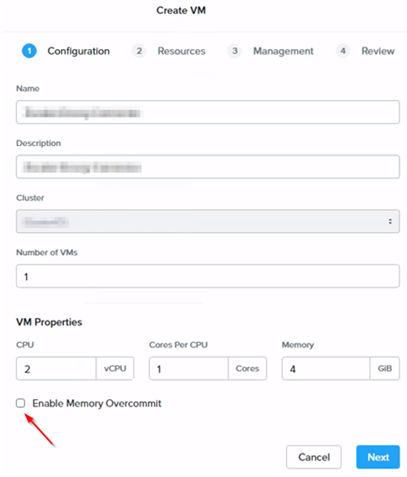 圖2 部署VM虛擬主機時啟用Memory Overcommit機制。
圖2 部署VM虛擬主機時啟用Memory Overcommit機制。
但是,每項特色功能和機制都有其適用情境和注意事項,譬如在Nutanix官方的最佳建議作法中,Memory Overcommit機制便非常適合使用於測試或研發環境,但對於企業和組織的正式營運環境,卻不建議使用,原因在於Memory Overcommit機制雖然可以達成超用記憶體資源,進而運作更多的VM虛擬主機和其他工作負載,然而卻可能導致VM虛擬主機效能下降,影響營運環境的反應速度,造成使用者體驗不佳的情況。
因此,在預設情況下,Nutanix官方並不建議啟用AHV虛擬化平台中的Memory Overcommit機制。那麼管理人員可能會感到困惑,在不啟用Memory Overcommit機制的情況下,AHV虛擬化平台又是如何運作數量龐大的VM虛擬主機呢?答案是透過Ballooning和Swapping機制。
首先,在Nutanix虛擬化架構中的VM虛擬主機,必須確保已經安裝VirtIO驅動程式,系統便會透過VirtIO驅動程式整合Ballooning機制,將VM虛擬主機中未使用到的記憶體空間歸還給AHV虛擬化平台,以便提供給其他需要的VM虛擬主機進行使用。
舉例來說,管理人員組態設定3台配置20GB虛擬記憶體的VM虛擬主機,但是AHV虛擬化平台卻僅僅使用了40GB記憶體空間,那麼這是如何辦到的呢?簡單來說,Ballooning機制會將VM虛擬主機中虛擬記憶體的真實使用情況,回報給底層的AHV虛擬化平台,然後AHV虛擬化平台便可以針對VM虛擬主機中未使用到的記憶體空間進行回收作業,再將回收後的記憶體資源提供給其他VM虛擬主機使用,達成動態配置記憶體資源的效果,如圖3所示。
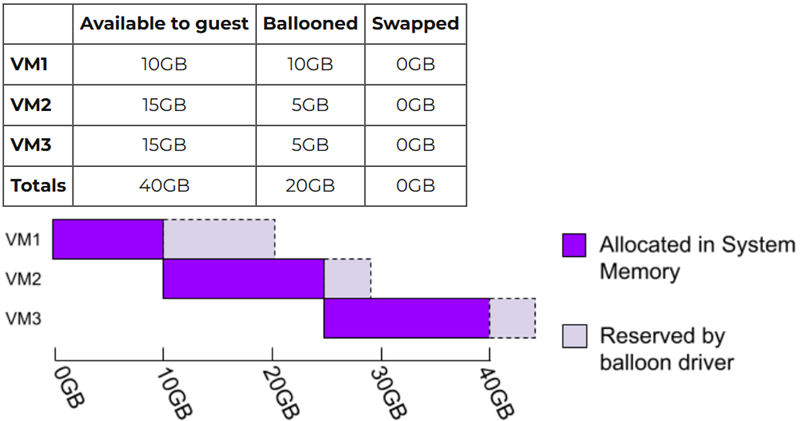 圖3 AHV虛擬化架構中Ballooning運作機制示意圖。 (圖片來源:AHV Internals: Memory Overcommit | Nutanix / tech center)
圖3 AHV虛擬化架構中Ballooning運作機制示意圖。 (圖片來源:AHV Internals: Memory Overcommit | Nutanix / tech center)
當然,倘若VM虛擬主機需要使用到更多記憶體資源時,在VM虛擬主機中透過VirtIO整合的Ballooning機制,便會通知底層AHV虛擬化平台,在不影響VM虛擬主機正常運作的情況下,將可用的記憶體空間慢慢進行收回的動作,以便增加可用的記憶體資源。
然而,在工作負載眾多、記憶體資源爭奪強烈的環境中,有可能Ballooning機制會來不及調度記憶體空間,並且眾多VM虛擬主機使用的記憶體空間加總後,超過AHV虛擬化平台所擁有的總記憶體空間,那又該怎麼辦?此時,就需要使用到Swapping機制了!
當眾多VM虛擬主機因為同時間工作負載提升,總共使用的記憶體空間超過AHV虛擬化平台的實體記憶體空間時,系統將會採用「Least Recently Used(LRU)」演算法機制,將不足的記憶體空間,透過Host Swap的方式來滿足VM虛擬主機超用的記憶體需求。然而,應特別注意的是,因為採用Host Swap的方式,所給予VM虛擬主機記憶體資源,與使用實體記憶體空間在運算效能上有非常大的差異,如圖4所示。
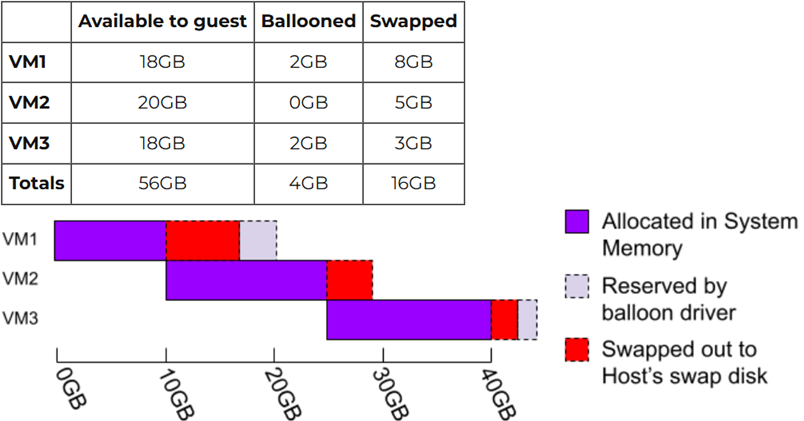 圖4 AHV虛擬化架構中Ballooning+Swapping運作機制示意圖。 (圖片來源:AHV Internals: Memory Overcommit | Nutanix / tech center)
圖4 AHV虛擬化架構中Ballooning+Swapping運作機制示意圖。 (圖片來源:AHV Internals: Memory Overcommit | Nutanix / tech center)
因此,如果發現Host Swap的情況經常發生時,首先應該考慮為叢集節點主機擴充實體記憶體空間,若無法擴充實體記憶體空間,則建議的過渡方式為採用VM虛擬主機內的Swap機制,因為相較之下Guest Swap會比Host Swap來得有效率。
舉例來說,組態設定VM虛擬主機配置20GB虛擬記憶體,但是卻會使用到Host Swap機制時,不如考慮調整VM虛擬主機的組態設定,將其配置為10GB虛擬記憶體,並且搭配VM虛擬主機內作業系統的Swap機制,透過Guest Swap機制中10GB Swap Disk來滿足過渡需求。
ADS + Memory Overcommit
實務上,在Nutanix虛擬化架構中,預設情況下便會啟用Acropolis Dynamic Scheduler(ADS)負載平衡機制,那麼當ADS負載平衡搭配Memory Overcommit機制時,又如何因應各式各樣的工作負載情境。舉例來說,在AHV虛擬化平台,具備40GB記憶體空間的運作環境中,已經組態設定3台配置10GB虛擬記憶體的VM虛擬主機,並且需要再啟動1台配置15GB虛擬記憶體的VM虛擬主機時,系統將會發生什麼情況呢?
AHV虛擬化平台將會進行記憶體可用空間估算作業,假設3台配置10GB vMemory的VM虛擬主機,已經使用記憶體資源池30GB的記憶體空間,當需要再啟動1台配置15GB vMemory的VM虛擬主機時,系統會先透過剛才提到的Ballooning和Swapping機制,嘗試回收尚未被VM虛擬主機占用的記憶體空間,假設系統順利收回5GB記憶體空間,此時記憶體資源池降低為使用25GB記憶體空間,接著透過ADS負載平台機制中的Initial Placement初始化配置機制,來啟動配置15GB vMemory的VM虛擬主機,如圖5所示。
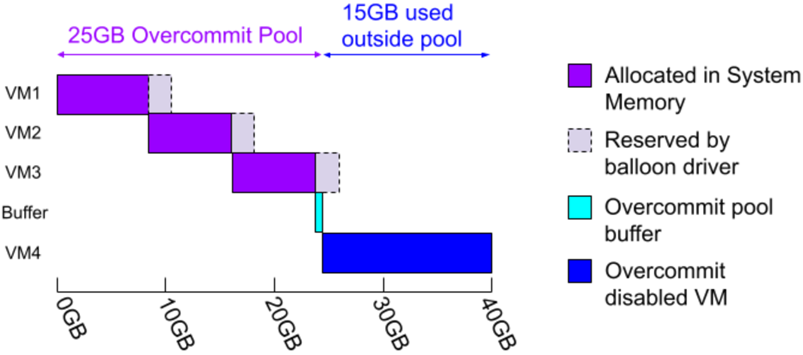 圖5 實務上ADS搭配Memory Overcommit運作機制示意圖。 (圖片來源:AHV Internals: Memory Overcommit | Nutanix / tech center)
圖5 實務上ADS搭配Memory Overcommit運作機制示意圖。 (圖片來源:AHV Internals: Memory Overcommit | Nutanix / tech center)
記憶體空間集縮比
預設情況下,每台VM虛擬主機,系統都會確保至少有25%的記憶體空間,來自於AHV虛擬化平台的實體記憶體空間,這表示在部署VM虛擬主機,啟用Memory Overcommit機制時,系統透過Ballooning + Swapping機制時,最多可以預留VM虛擬主機75%的虛擬記憶體空間。
當然,預留25%和75%記憶體空間為理想情況,然而在實際運作情況下,組態設定4台配置10GB vMemory的VM虛擬主機環境中,每台VM虛擬主機最大化縮小至使用25%的記憶體空間,所以總共使用AHV虛擬化平台中,記憶體資源池內10GB記憶體空間。
此時,便可以再額外啟動3台配置10GB vMemory的VM虛擬主機,因為VM虛擬主機剛啟動時,客體作業系統需要使用全部的記憶體空間,但是開機完成經過一段時間後,待客體作業系統內的服務和應用程式啟動完畢,使用的記憶體空間便會逐漸下降,此時系統便可以透過Ballooning + Swapping機制,開始回收VM虛擬主機未占用的記憶體空間,以便提供給更多的VM虛擬主機使用。
如圖6所示,透過範例圖表可知,當AHV虛擬化平台配置40GB實體記憶體時,在每台VM虛擬主機配置10GB vMemory的情況下,最理想的情況可以達到「3.25倍」的集縮比,也就是能夠運作最多13台配置10GB vMemory的VM虛擬主機。
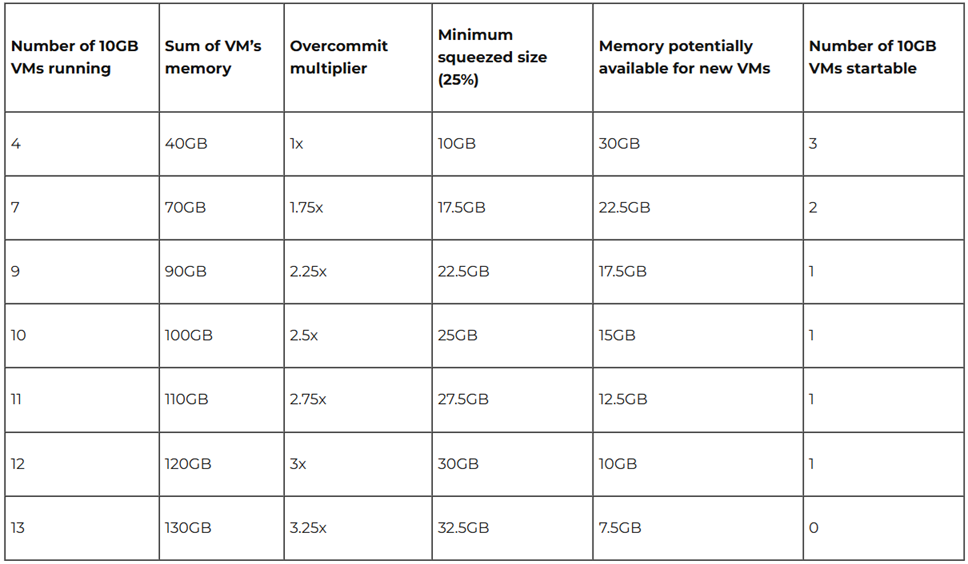 圖6 Memory Overcommit Ratio範例圖表。 (圖片來源:AHV Internals: Memory Overcommit | Nutanix / tech center)
圖6 Memory Overcommit Ratio範例圖表。 (圖片來源:AHV Internals: Memory Overcommit | Nutanix / tech center)
值得注意的是,範例表格中的估算,為假設Nutanix叢集未啟用High Availability(HA)高可用性機制,若啟用HA高可用性機制,系統為了保留更多系統資源以便因應故障事件,因此Memory Overcommit集縮比例將會下降至「1.33倍」。
線上遷移時間
在AHV虛擬化平台版本升級過程中,正常情況下,系統會讓AHV節點主機進入維護模式,當升級程序執行完畢,AHV節點主機必須重新啟動以便套用生效,然而,在此之前必須先將其上運作的VM虛擬主機,透過ADS Live Migration機制,將VM虛擬主機線上遷移至其他AHV節點主機繼續運作。
如果已經啟用Guaranteed HA功能,那麼每一台VM虛擬主機要線上遷移的目地端AHV節點主機已經確認完畢,系統會直接將VM虛擬主機線上遷移過去。倘若未啟用Guaranteed HA功能,便會透過ADS負載平衡機制,先識別每一台VM虛擬主機適合運作的AHV節點主機,再進行線上遷移作業。
在線上遷移VM虛擬主機時,過程中牽涉到記憶體空間複製的動作,並且需要遷移所有的實體記憶體空間。然而,啟用Memory Overcommit機制的VM虛擬主機,因為使用的記憶體空間並非全部都是實體記憶體空間,所以會導致遷移時間較久的情況發生。
簡單來說,「未啟用」Memory Overcommit機制的VM虛擬主機,因為都是使用實體記憶體空間,所以相較之下能夠在較短的時間內遷移完畢,而「啟用」Memory Overcommit機制的VM虛擬主機,則因為要將Swapping虛擬記憶體空間回寫至實體記憶體空間中,導致遷移時間較長並會影響運作效能,這也是ADS負載平衡機制在計算遷移成本時,啟用Memory Overcommit機制的VM虛擬主機會是較高遷移成本的主要原因,如圖7所示。
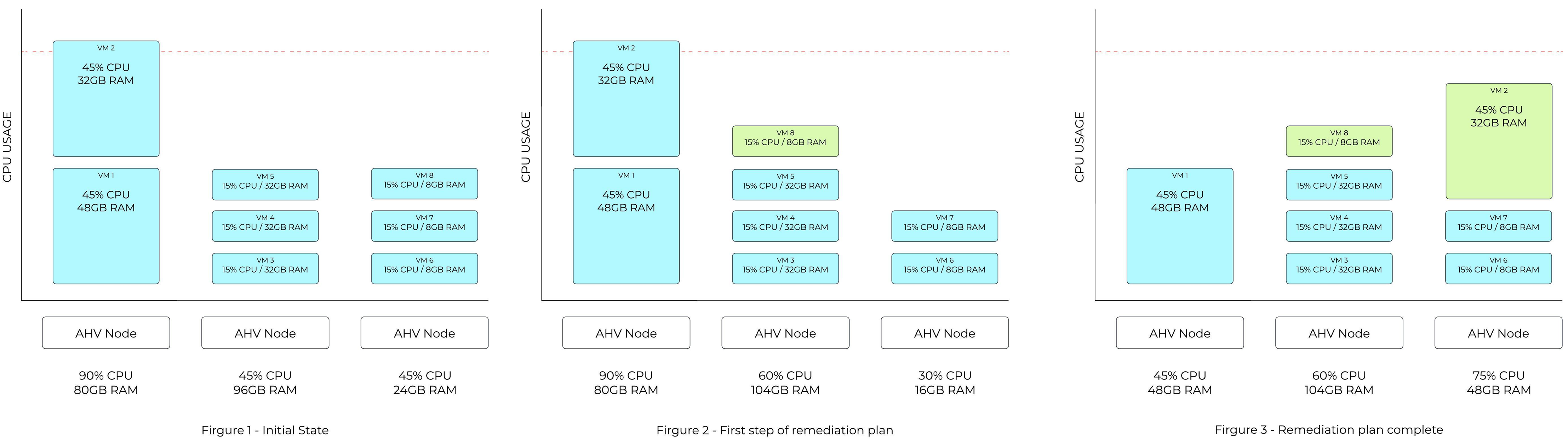 圖7 ADS負載平衡機制線上遷移VM虛擬主機示意圖。 (圖片來源:Acropolis Dynamic Schedulre(ADS)| The Nutanix Cloud Bible)
圖7 ADS負載平衡機制線上遷移VM虛擬主機示意圖。 (圖片來源:Acropolis Dynamic Schedulre(ADS)| The Nutanix Cloud Bible)
AHV記憶體資源開銷估算
事實上,企業可以在導入之前,針對日後預計啟用的特色功能和VM虛擬主機數量,估算AHV虛擬化平台的運算資源。下列舉例雖然不是絕對值,也可能因為日後版本的增強而不同,但管理人員可以使用下列基準進行估算:
‧AHV節點主機,每台主機至少需要3.5GB記憶體空間,外加系統總記憶體的2.2%資源開銷。
‧日後預計在PC主控台中啟用Flow Virtual Networking特色功能時,每台主機需2GB記憶體空間開銷。倘若需要啟用Flow MicroSegmentation特色功能時,每台主機需4GB記憶體空間開銷。
‧當AHV節點主機安裝GPU時,將會產生系統總記憶體的1.5%資源開銷。
根據上述的資源開銷估算原則,若一台配備256GB實體記憶體空間的AHV節點主機,預計啟用Flow Virtual Networking和Flow MicroSegmentation特色功能時,記憶體空間的開銷為15GB(3.5 + 256 × 0.022 + 2 + 4),表示還剩餘241G記憶體空間,可以用於運作CVM主機和其他VM虛擬主機等等工作負載。
此外,VM虛擬主機也會因為配置不同,而有額外的記憶體資源開銷,一台標準的VM虛擬主機,在配置一個VirtIO網路卡並且沒有配置vGPU的情況下,基本記憶體資源開銷為50MB。
同時,隨著vCPU數量和vMemory的組態設定不同,VM虛擬主機的記憶體開銷也會隨之增加。舉例來說,每增加1個vCPU處理器時,便會增加1MB的記憶體資源開銷,而每增加1GB vMemory時,也會增加7MB的記憶體資源開銷。
因此,一台配置8 vCPU及8GB vMemory的VM虛擬主機,將會產生額外的114MB記憶體資源開銷,如圖8所示。
 圖8 VM虛擬主機額外記憶體資源開銷範例圖表。 (圖片來源:CPU and Memory Oversubscription | Nutanix AHV Best Practices)
圖8 VM虛擬主機額外記憶體資源開銷範例圖表。 (圖片來源:CPU and Memory Oversubscription | Nutanix AHV Best Practices)
vCPU和pCPU集縮比
在實務應用上,雖然VM虛擬主機的vCPU運算資源,通常不是最先遭遇效能瓶頸的資源,然而失衡的vCPU和pCPU集縮比例,除了造成AHV節點主機額外的記憶體資源開銷外,也容易影響VM虛擬主機的運算效能。
例如,AHV節點主機的x86實體伺服器共配置2顆CPU處理器,每顆CPU處理器具備24個運算核心,那麼這台的AHV節點主機便具備48 pCPU,可能會有管理人員不解,開啟Hyper-Threading(HT)功能後,處理器核心增加一倍不是應該用96 pCPU來計算?
這個問題見仁見智,主要原因在於,透過HT功能進而成長的核心數,並非真正的運算單位,而是採用軟體機制搭配邏輯方式增加核心數,並且僅在特定情況下才能夠提升運算能力,所以開啟HT功能的2 pCPU,並非真正能達到2倍的核心運算速度,在支援SMP多執行緒的情況下,最多僅能達到1.2~1.4倍的核心運算能力。
並且,從虛擬化平台在CPU資源調度時也可以得知,若需要指派2個運算核心時,CPU調度機制肯定會優先指派給開啟HT機制中倘未使用的核心數,而非指派給已經使用1個開啟HT的核心資源,這也就是為什麼開啟HT功能的核心數,嚴格來說稱不上是真正的實體運算核心單位的主要原因之一。
那麼vCPU和pCPU多少的集縮比例才是最佳?這個問題的解答很難一概而論,主要原因在於工作負載情況非常複雜,但是卻有通用原則,當然管理人員最後還是必須依照實際情況進行調整。Nutanix官方的最佳建議作法中,針對Tier 1層級的VM虛擬主機,也就是關鍵營運服務和延遲敏感的應用程式,建議採用的vCPU和pCPU集縮比例為1:1或2:1,而針對Tier 2層級的VM虛擬主機,則建議採用的vCPU和pCPU集縮比例為2:1或4:1,如圖9所示。
 圖9 針對Tier 1/Tier 2的vCPU和pCPU集縮比例建議值。 (圖片來源:CPU and Memory Oversubscription | Nutanix AHV Best Practices)
圖9 針對Tier 1/Tier 2的vCPU和pCPU集縮比例建議值。 (圖片來源:CPU and Memory Oversubscription | Nutanix AHV Best Practices)
CVM運作規模最佳化
在Nutanix超融合運作環境中,HCI超融合節點主機,每台HCI主機皆會啟動Controller VM(CVM)主機,並且預設分配8 vCPU和32GB vMemory虛擬硬體資源,透過PCI Passthrough方式直接存取本地磁碟裝置,以便提供分散式儲存服務,如圖10所示。
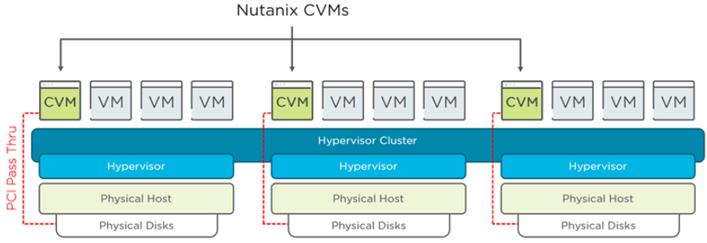 圖10 HCI超融合節點主機運作架構示意圖。 (圖片來源:Nutanix CVM Considerations)
圖10 HCI超融合節點主機運作架構示意圖。 (圖片來源:Nutanix CVM Considerations)
原則上,CVM主機只會在需要時才占用CPU運算資源,其中為CVM配置的vCPU數量,僅表示最大可使用量而非固定使用量,同時叢集規劃時需要留意維護或失效時的資源容錯情況,尤其針對SQL Server、Exchange Server等等企業組織的關鍵應用服務。
從AOS 5.11版本開始,AHV叢集節點主機支援「純運算節點」(Computer Node)。簡單來說,Computer Node主機上,不會運作CVM主機以因應運算為主的應用,例如大型Oracle等等專屬應用情境,但是採用純運算節點時,有嚴格的部署與擴充節點上的限制,如圖11所示。
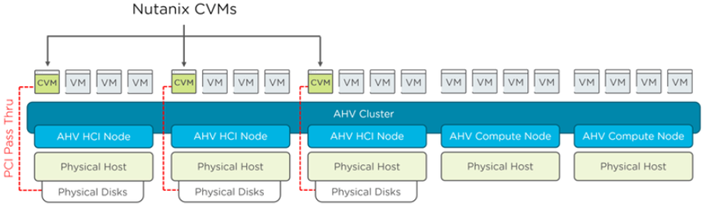 圖11 HCI超融合節點主機搭配純運算節點主機運作架構示意圖。 (圖片來源:Nutanix CVM Considerations)
圖11 HCI超融合節點主機搭配純運算節點主機運作架構示意圖。 (圖片來源:Nutanix CVM Considerations)
同時,因為純運算節點中沒有CVM主機能夠協助處理分散式儲存機制,所以也無法享有資料本地性的嚴重缺點。值得注意的是,純運算節點支援運作在AHV虛擬化平台,並且不支援運作Exchange Server工作負載。
確認採用HCI或純運算節點主機類型後,接著需要確認屆時Nutanix叢集中要運作哪些類型的工作負載為主要考量點,舉例來說,若是ROBO/Edge小型環境,只要為CVM配置6 vCPU和20GB vMemory虛擬資源即可,如圖12所示,倘若需要搭配Redundancy Factor 3的資料容錯設定,儲存裝置採用All-NVMe時,那麼CVM就必須提升至64GB vMemory才行。詳細資訊可參考「AOS 7.0 - Controller VM (CVM) Specifications」文件內容。
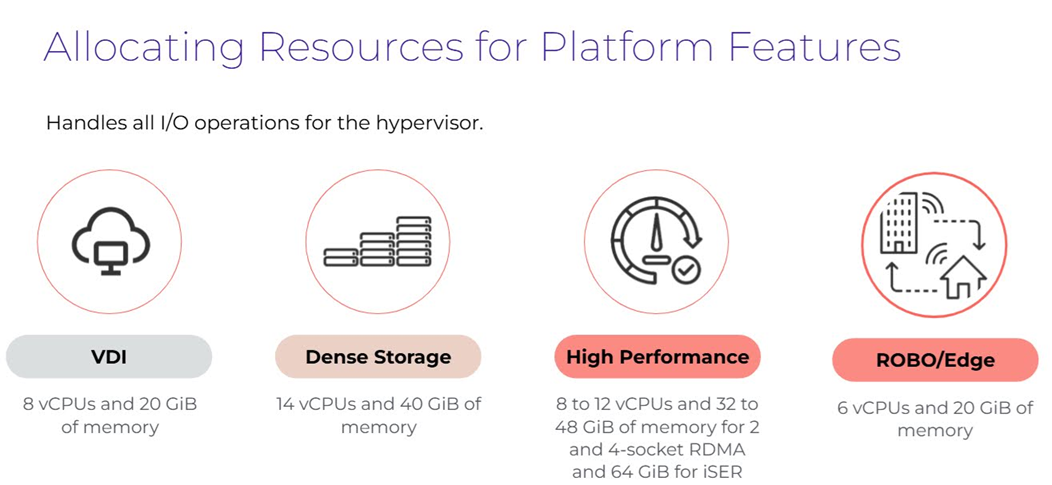 圖12 依照應用情境決定CVM運作規模大小示意圖。 (圖片來源:Peak Performance - Optimizing VMs | Nutanix University)
圖12 依照應用情境決定CVM運作規模大小示意圖。 (圖片來源:Peak Performance - Optimizing VMs | Nutanix University)
在Nutanix運作環境中,Controller VM(CVM)扮演資料管理中樞,協調使用者I/O、資料放置與metadata管理,確保資料完整性與可用性,同時透過垃圾回收、壓縮、重複資料刪除與糾刪碼技術最佳化儲存效率,並支援快照與複製等保護機制。
CVM的效能關鍵在於分配到的邏輯核心數量,這會依照部署類型、儲存容量、快照頻率與功能啟用情況而有所不同。在AOS安裝時,便會根據這些條件自動配置最低邏輯核心「計算方式:物理核心 × 執行緒數量」,並將CVM的邏輯核心對應至同一個NUMA節點的獨立實體核心以避免資源競爭,剩餘核心則留給其他運作的VM虛擬主機使用。舉例來說,採用Intel Xeon Gold 5317S處理器(12 Cores),開啟Hyper-Threading(HT)技術的情況下,便具備24顆邏輯核心,其中上限12 Cores分配給CVM,其餘12 Cores則留給其他運作的VM虛擬主機使用,如圖13所示。
 圖13 CVM邏輯核心對應至同一NUMA節點獨立運算核心分配示意圖。 (圖片來源:AOS 7.0 - Controller VM(CVM) Specifications)
圖13 CVM邏輯核心對應至同一NUMA節點獨立運算核心分配示意圖。 (圖片來源:AOS 7.0 - Controller VM(CVM) Specifications)
那麼管理人員在部署 Nutanix叢集,為CVM配置比較小的vMemory Size時,後續能不能線上調整運作規模大小?答案是可以的!管理人員可以在登入Prism Element(PE)管理介面中,調整CVM Memory Size大小,如圖14所示,詳細資訊可參考「Prism 7.0 - Increasing the Controller VM Memory Size」文件內容。
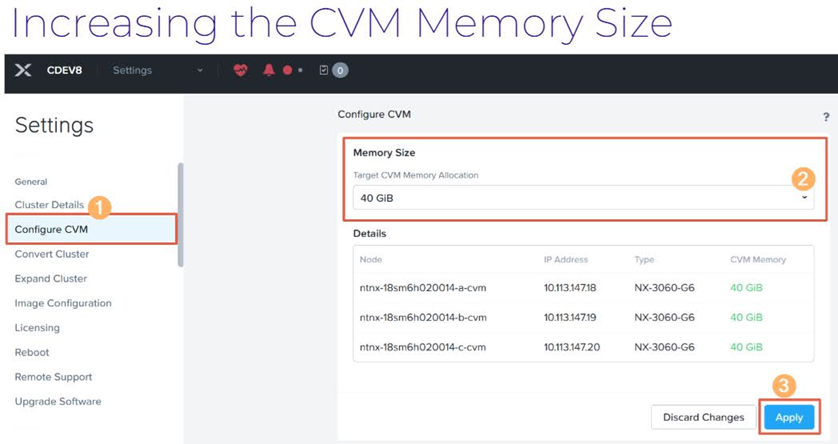 圖14 登入PE管理介面線上調整CVM vMemory Size大小。 (圖片來源:Peak Performance - Optimizing VMs | Nutanix University)
圖14 登入PE管理介面線上調整CVM vMemory Size大小。 (圖片來源:Peak Performance - Optimizing VMs | Nutanix University)
PC主控台運作規模最佳化
在Nutanix基礎架構中,Prism Central(PC)主控台角色的重要性不言而喻,因此良好的PC Size規模大小的規劃,將會影響後續的日常維護作業,本文將說明基礎的Sizing Prism Central(PC)。
簡單來說,在Prism Central(PC)主控台運作架構中,分為「單台」和「三台」PC VMs的運作架構,即便一開始部署的是單台PC VM,也可以在之後需求增加時,水平擴充成三台PC VMs的架構,如圖15所示。
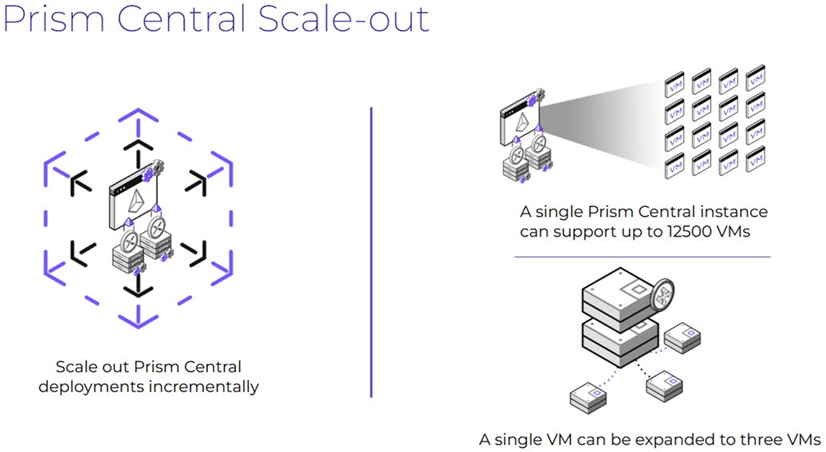 圖15 PC主控台分別支援單台和三台的運作架構示意圖。 (圖片來源:Peak Performance - Optimizing VMs | Nutanix University)
圖15 PC主控台分別支援單台和三台的運作架構示意圖。 (圖片來源:Peak Performance - Optimizing VMs | Nutanix University)
那麼PC有哪些運作規模可以選擇呢?分別支援X-Small、Small、Large、X-Large等四種運作規模,其中X-Small(4 vCPU, 18GB vMemory, 100GB vDisk)是從AOS 6.8或後續版本才新增加的運作規模,可以管理5 Clusters, 50 Hosts, 500 VMs大小的叢集環境,如圖16所示。
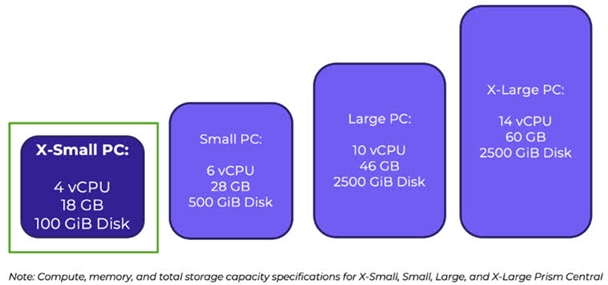 圖16 PC主控台支援X-Small、Small、Large、X-Large等四種運作規模。 (圖片來源:Introducing X-Small Prism Central: A Low Footprint Option for Smaller Environments | Nutanix / tech center)
圖16 PC主控台支援X-Small、Small、Large、X-Large等四種運作規模。 (圖片來源:Introducing X-Small Prism Central: A Low Footprint Option for Smaller Environments | Nutanix / tech center)
那麼每種PC Size能夠承載多大規模的叢集環境?舉例來說,Small規模能夠承載10 Clusters, 200 Hosts, 2500 VMs的叢集環境,詳細資訊可以參考「Nutanix Configuration Maximums | Nutanix Support & Insights」文件內容,如圖17所示。
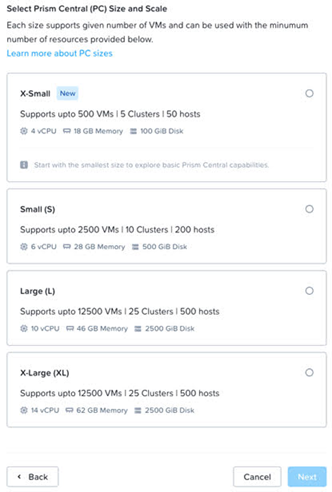 圖17 不同PC主控台規模支援不同大小的Nutanix叢集運作環境。 (圖片來源:Introducing X-Small Prism Central: A Low Footprint Option for Smaller Environments | Nutanix / tech center)
圖17 不同PC主控台規模支援不同大小的Nutanix叢集運作環境。 (圖片來源:Introducing X-Small Prism Central: A Low Footprint Option for Smaller Environments | Nutanix / tech center)
結語
相信管理人員深入了解Nutanix叢集環境中的重要運作元件,包含PC和CVM運作規模的規劃以及Memory Overcommit的機制後,就能夠為企業和組織打造出高效能和最佳化的Nutanix叢集。
<本文作者:王偉任,Microsoft MVP及VMware vExpert。早期主要研究Linux/FreeBSD各項整合應用,目前則專注於Microsoft及VMware虛擬化技術及混合雲運作架構,部落格weithenn.org。>