在上期文章已介紹了如何從無到有地部署一個VMware vSphere 6.7的虛擬化基礎運作環境,這回將繼續在這個基礎上完成一個具備虛擬機器熱備援能力的架構,以便在發生ESXi主機單點失敗時,關鍵的虛擬機器能夠在最短的時間內全自動化地在其他可用的ESXi主機中恢復運作。
想要讓關鍵的IT應用服務提供絕佳的運作品質,從伺服器主機的電源、網路、硬碟、I/O介面,一直到作業系統層面,樣樣都需要有備援的能力,才能夠全面預防可能的單點故障問題,而導致重要服務停擺。此外,在備援的方式中無論是硬體還是軟體層面,還可以再區分為熱備援與冷備援。
例如,在常見的磁碟陣列(RAID)規劃中,為了避免單一硬碟故障造成系統損毀,都會選擇使用RAID 1、RAID 5、RAID 6、RAID 10等等的架構,但這樣還不夠,最好還得設定至少一顆硬碟屬於Hot Spare功能,而這顆硬碟由於平常不會使用到,因此看似有點浪費,但它正屬於熱備援的用途,在上述任一RAID架構中,一旦發生某顆硬碟故障,就能夠自動遞補上去,而不需要人工介入,這便是屬於熱備援的機制。
至於冷備援呢?簡單來說,就是在磁碟陣列架構中,少了Hot Spare功能硬碟的準備,因此在發生像是RAID 5中的任一顆硬碟故障時,必須自行手動替換硬碟,而過程中由於可能還會需要等待漫長的採購時間,可以說緩不濟急的風險相當大。不過,雖然熱備援是維持IT正常營運的重要環節,但可別忘了,冷備援、資料備份的準備也同樣是相當重要的,因為只是因應的災害情境不同而已。
回到vSphere虛擬化架構的系統層面,要如何為虛擬機器建立一個具備熱備援機制的運作架構,以因應ESXi主機發生單點失敗的容錯問題呢?
其實做法並不難,因為它就如同絕大多數的系統備援架構設計一樣,不外乎是需要主機間共享的網路儲存設備,來建立一個能夠主機之間相互備援的叢集(Cluster)環境,只是在最新的vSphere 6.7版本中該如何完成這項任務呢?接下來,就跟著本文的實戰步驟親自動手完成這項全新的學習!
管理網路的準備
在啟用vSphere虛擬機器的熱備援功能之前,必須優先避免兩項經常會犯的錯誤,也就是說,若貿然啟用,便會發現在叢集(Cluster)熱備援架構下的每一部ESXi主機摘要頁面內,如圖1所示出現了「此主機的vSphere HA活動訊號資料存放區數目為0,其少於必要數目:2」以及「此主機目前沒有管理網路重複」兩個警示訊息。上述這兩項警告訊息,儘管不會讓熱備援功能無法運作,但卻會造成日後永續運行目標上的隱憂。
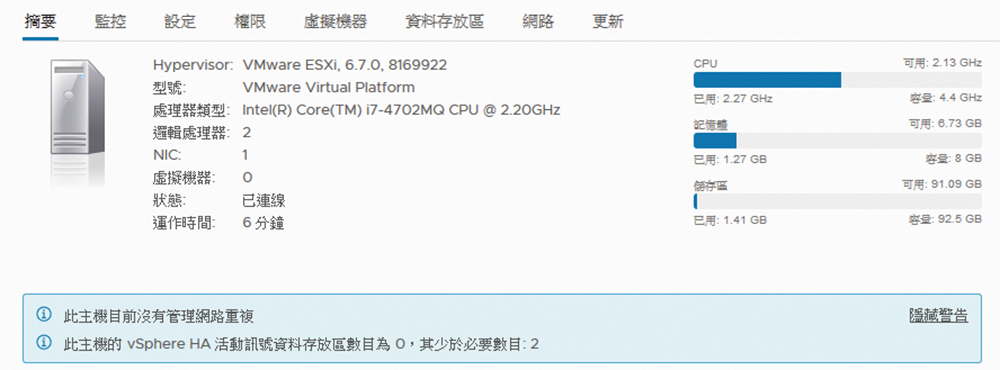 |
| ▲圖1 出現ESXi主機警告訊息。 |
首先,為了確保在vSphere HA的運作中,可以精準監視到叢集中每一部ESXi主機的活動狀態,以便在任一ESXi主機發生沒有網路回應時,可以迅速將其上運行中的虛擬機器,改由其他活動中的ESXi主機來啟動並且恢復正常運行,這時用以儲存活動訊號資料的存放區就相當重要。即便只要一個,也能夠讓熱備援的機制正常運行,但在同時提供兩組活動訊號資料存放區的架構下,肯定可以讓意外發生的可能性降至最低。關於此問題的預防方法,將留待後續有關「共享儲存設備的準備」和「iSCSI儲存區連接配置」的議題中再來詳解。