AI無疑具有龐大的潛力,但就目前科技發展的能力,AI尚處於比較初級的階段,仍是一門「技術」而非「科學」。既然AI還不是一門科學,這意味著AI研究者們必須有真正的興趣,靠興趣和好奇心去驅動自己前行,才能克服無數的失敗。
若從達特茅斯會議起算,AI已經走過65年歷程,尤其是近幾年深度學習興起後,AI迎來了前所未有的繁榮。不過,最近兩年AI熱潮似乎有點降溫,在理論突破和落地應用上都遇到了挑戰,外界不乏批評質疑的聲音,甚至連一些AI從業者也感到有點沮喪。 筆者身為一名AI研究者,有幸見證了這個領域的一些起伏;本文將全面回顧AI的發展,審視我們當下所處的歷史階段,以及探索AI的未來發展性。
AI的歷史階段:手工作坊
雖然有人把現今稱為第三波甚至是第四波AI浪潮,樂觀地認為AI時代已經到來,然筆者抱持著較謹慎的看法:AI無疑具有龐大的潛力,但就目前科技發展的能力,AI尚處於比較初級的階段,仍是一門「技術」而非「科學」,這正是全球AI共同面臨的難題。
這幾年深度學習的快速發展,大幅改變了AI產業的面貌,讓AI成為大眾日常生活中都能接觸到的技術,甚至還出現了一些有如科幻電影一般的AI應用案例。但實際上,技術發展需要長期積累,目前只是AI的初級階段,AI時代才剛開始。
如果將AI時代和電氣時代類比,今天我們的AI技術就好比是法拉第時代的電。法拉第透過發現電磁感應定律,並研製出人類第一台交流電發電機原型,這些先行者透過大量觀察和反覆實驗,手工做出了各種新產品,但他們只是拉開了電氣時代的序幕。電氣時代的突破性發展受益於電磁場理論的提出:馬克士威把實踐的經驗變成科學的理論,提出並證明了具有跨時代意義的馬克士威方程組。 如果人們對電磁的理解停留在法拉第的層次,電氣革命是不可能發生的。倘若颳風下雨打雷甚至連溫度變化都會導致斷電,電不可能變成一個普及性的產品及社會基礎設施,更不可能出現各式各樣的電氣、電子、通訊產品,徹底改變全人類的生活方式。
這也是AI目前面臨的問題,AI的應用局限於特定的場景、特定的資料。AI模型一旦走出實驗室,受到現實世界的干擾和挑戰就時常失效,穩健性不夠;每換一個場景,就需要配合場景重新訂製演算法,費時費力,難以規模化推廣,概括化應用的能力較為有限。這是因為當今的AI發展很大一部分是根據經驗法則,AI工程師就像當年的法拉第,能夠做出一些AI產品,但都是知其然,不知其所以然,還未能掌握其中的核心原理。
AI迄今未能成為一門科學的原因主要在於技術發展過於緩慢。回顧90年代至今的二十多年來,AI發展主要在於應用工程上的快速進步,核心技術和核心問題的突破相對有限且緩慢。許多看似近幾年興起的技術,實際上早已存在已久。
以自動駕駛為例,美國卡內基美隆大學的研究人員進行的Alvinn計畫,在80年代末已經開始用神經網路來實現自動駕駛,1995年成功自東向西穿越美國,歷時7天,行駛近3,000英里(圖1)。在下棋方面,1992年IBM研究人員開發的TD-Gammon,和AlphaZero相似,能夠自我學習和強化,其能力甚至可與雙陸棋大師匹敵。
 圖1 1995年穿越美國專案計畫開始之前的團隊合照。
圖1 1995年穿越美國專案計畫開始之前的團隊合照。
不過,由於資料和運算能力的限制,這些研究只是點狀發生,沒有形成規模,自然也沒有引起大眾的廣泛討論。今天由於商業的普及、運算能力的增強、資料的方便分析、應用門檻的降低,AI開始觸手可及。
但核心思想並沒有根本性的變化。目前的做法都是試圖用有限樣本來實現函數近似,進而描述這個世界,有一個Input,再有一個Output,將AI的學習過程想像成一個函數的近似過程,包括整個演算法及訓練過程,如梯度下降、梯度回傳等。
同樣地,核心問題也沒有得到有效解決。90年代學界關注與神經網路、深度學習密切相關的一些問題,至今仍然沒有得到解決。比如,非凸函數的優化問題,它得到的解很可能是局部最優解,並非全域最優,訓練時可能造成無法收斂,或因資料有限帶來應用廣泛性不足的問題。
深度學習:大繁榮後遭遇發展瓶頸
毋庸諱言,以深度學習為代表的AI研究這幾年取得大幅進步,比如在複雜網路的訓練方面,產生了兩個相當成功的網路結構:CNN和Transformer。基於深度學習,AI研究者在語音、語義、視覺等各個領域都發展快速,解決了諸多現實難題,為社會帶來許多價值。
不過,回過頭來看深度學習的發展,AI的發展中其實帶有相當高程度的幸運成分。
首先是隨機梯度下降(SGD),大幅度地推動了深度學習的發展。隨機梯度下降其實是一個很簡單的方法,具有較大局限性,在優化裡面屬於收斂較慢的方法,但它偏偏在深度網路中表現很好,而且還是出奇得好。為什麼會這麼好?至今研究者都沒有完美的答案。 類似這樣難以理解的好運氣還包括殘差網路、知識蒸餾、Batch Normalization、Warmup、Label Smoothing、Gradient Clip、Layer Scaling……,尤其是有些還具有超強的應用能力,能用在多個場景中。
再者,在機器學習裡,研究者一直在警惕過度擬合(Overfitting)的問題。當參數特別多時,一條曲線能夠把所有的點都擬合得特別好,它很有可能是有問題的,但在深度學習裡面這似乎不再成為一個問題。雖然有很多研究者對此進行了探討,但目前還有沒有明確答案。更加令人驚訝的是,即使給資料一個隨機的標籤,它也可以完美擬合(請見圖2中最右邊的random labels紅色曲線),最後得出擬合誤差為0。如果按照標準理論來說,這意味著這個模型沒有任何偏差(Bias),能幫忙解釋任何結果。但,任何東西都能解釋的模型,真的可靠嗎?
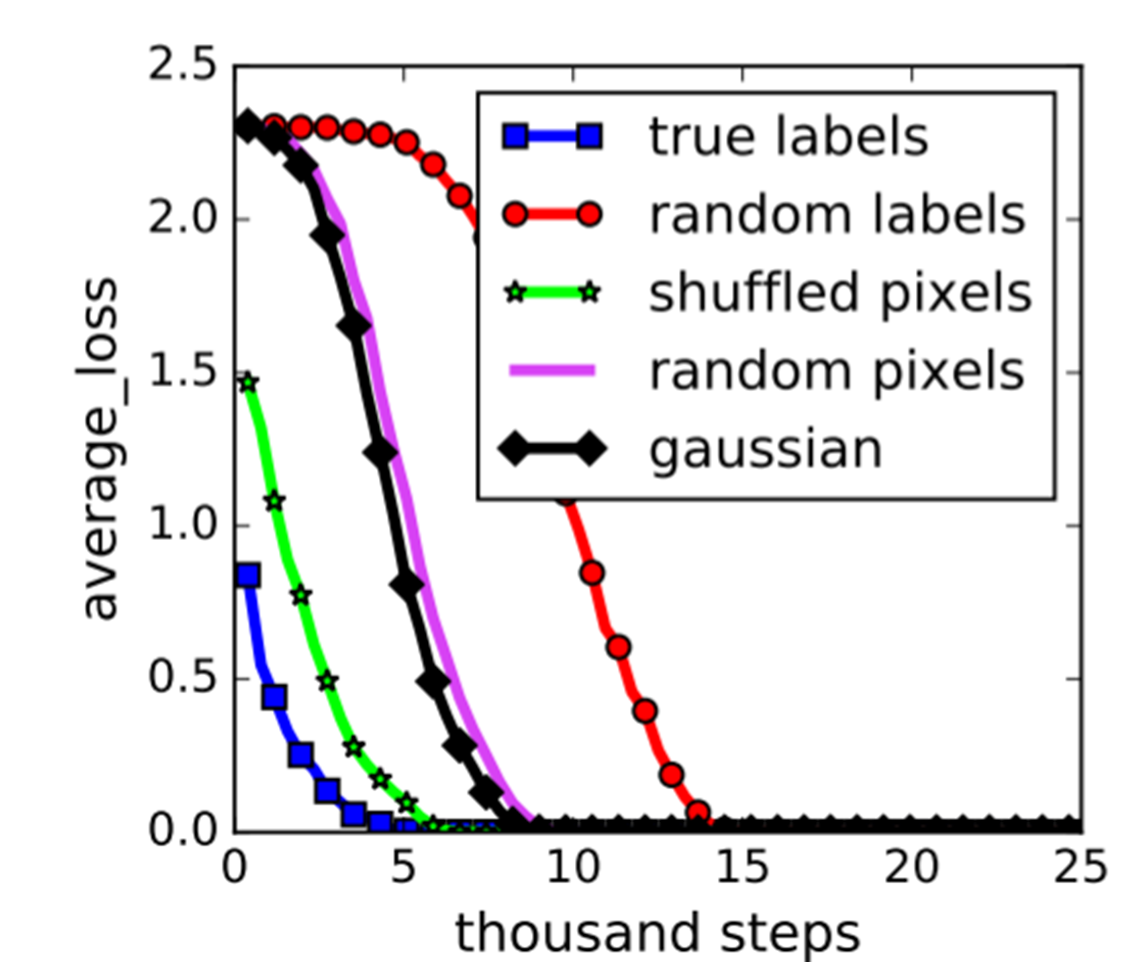 圖2 想了解深度學習必須廣義地重新思考。 (Understanding deep learning requires rethinking generalization. ICLR, 2017.)
圖2 想了解深度學習必須廣義地重新思考。 (Understanding deep learning requires rethinking generalization. ICLR, 2017.)
機器學習有幾波發展浪潮,在上世紀80年代到90年代,首先是基於規則(Rule based)。從90年代到2000年代,以神經網路為主,大家發現神經網路可以做一些不錯的事情,但是它有許多基礎的問題沒回答。所以2000年代以後,有一批人嘗試去解決這些基礎問題,最有名的叫SVM(Support Vector Machine),一群數學背景出身的研究者嘗試理解機器學習的過程,學習最基礎的數學問題,如何更好實現函數的近似,如何保證快速收斂,如何保證它的應用廣泛性?
當時的研究者非常強調理解,認為好的結果應該是來自於對研究的深刻理解。研究者會非常在乎有沒有好的理論基礎,因為要對演算法做好的分析,需要先對泛函分析、優化理論有深刻的理解,接著還要再做概括化理論等等這幾項都得非常好了,才可能在機器學習領域有發言權,否則很有可能連文章都看不懂。如果研究者自己要做一個大規模、分散式的實驗系統,還需要有工程的豐富經驗,否則根本做不了,那時候沒有太多現成的研究成果,而是純理論居多,多數工程實現需要靠研究者自己去進行。
但在深度學習時代,有研究者做出了非常好的框架,幫助其他的研究者降低了門檻,促進了AI產業的快速發展。如今只需要一個好想法就能做深度學習的實際操作,只要寫幾十行、甚至十幾行程式就能跑起來,亦有成千上萬人投入各式各樣的新專案實驗,驗證各種新想法,也經常能產出令人驚豔的結果。
然當今的研究者需要意識到,時至今日深度學習已遇到了很大的瓶頸。前文提及的,曾經幫助深度學習成功的好運氣、無法理解的黑盒效應,今天已成為它進一步發展的桎梏。
下一代AI的三個可能方向
AI的未來究竟在哪裡?下一代AI將是什麼?目前很難給出明確答案,然筆者認為,至少有三個方向值得重點探索和突破。
第一個方向是尋求對深度學習的根本理解,破除目前的黑盒狀態,只有這樣AI才有可能成為一門科學。具體來說,應該包括對以下關鍵問題的突破:
‧對基於DNN函數空間的更全面刻畫
‧對SGD(或更廣義的一階優化演算法)的理解
‧重新考慮概括化理論的基礎
第二個方向是知識和資料的有機融合。人類在做大量決定時,不僅使用資料,而且大量使用知識。如果我們的AI能夠把知識結構有機融入,成為重要組成部分,AI勢必有突破性的發展。研究者已經開始在做知識圖譜等工作,但需要進一步解決知識和資料的有機結合,探索出可用的框架。之前曾有些創新性的嘗試,例如Markov Logic,就是把邏輯和基礎理論結合起來,形成了一些有趣的結構。
第三個重要方向是自監督學習和小樣本學習。雖然筆者將此一發展方向列在第三,但卻是目前值得重點推進的方向,它可以彌補AI和人類智慧之間的差距。
現今時常聽說AI在一些能力上可以超越人類,例如語音辨識、圖像辨識等等,舉例來說,日前阿里巴巴達摩院的深度語言模型體系AliceMind在視覺問答上的得分首次超過人類,但這並不意味著AI比人類更智慧。在這一點上,Google在2019年發布的論文《On the Measure of Intelligence》非常有洞察力,其核心觀點正是真正的智慧不僅要具有高超的技能,更重要的是其能否快速學習、快速適應或者快速通用。
按照這個觀點,目前AI是遠不如人類的,雖然它可能在一些方面的精確度超越人類,但可用範圍非常有限。根本原因在於:人類只需要很小的學習成本就能快速達到結果,聰明的人更是如此——這也是筆者認為目前AI和人類的主要區別之一。
用一個很簡單的事實,就能證明AI不如人類智慧。以翻譯為例,現在好的翻譯模型至少要上億級的資料。如果一本書大概是十幾萬字,AI大概要讀上萬本書才能做到精準的翻譯。我們很難想像,一個人需要讀上萬本書才能學好一門語言。
另外一個有意思的對比,則是神經網路結構和人腦。目前AI非常強調深度,神經網路經常幾十層甚至上百層,但我們看人類,以視覺為例,視覺神經網路總共就四層,非常高效率。而且人腦還非常低功耗,只有20瓦左右,但今天GPU基本都是數百瓦,差距甚大。著名的語言模型GPT-3跑一次,碳排放相當於一架747飛機從美國東海岸到西海岸往返三次。再看資訊編碼,人腦是以時間序列來編,AI是用張量和向量來表達。
也許有人認為,AI發展不必一定得要向人腦智慧的方向發展。此一觀點不無道理,但在AI遇到瓶頸,也找不到其他參照物時,參考人腦智慧可能會給研究者們帶來一些啟發。例如,拿人腦智慧來做對比,今天的深度神經網路是不是最合理的方向?今天的編碼方式是不是最合理的?這些都是當今AI發展的基礎,但它們是好的基礎嗎?
以GPT-3為代表的大模型,可能也是深度學習的一個突破方向,能夠在一定程度上實現自學習。大模型的概念就像是記住了所有它能看到的東西,每當碰到一個新場景時,就不需要太多新資料。然而,目前仍不知道這是否就是最好的解決辦法。同樣以前文提及的翻譯為例,大模型現在都是百億、千億參數規模起步,沒有一個人類的大腦中會帶著這麼多資料。
AI的機會:AI for Science
儘管當今的AI發展還未解決上述提及的三個難題,亦尚未成為科學,然而,AI仍然擁有它的價值與機會。技術本身就擁有巨大價值,像網際網路的出現就徹底重塑了人類的工作和生活。AI作為一門技術,當下一個巨大的機會就是幫助解決科學重點難題(AI for Science)。AlphaFold已經提供一個很好的示範,AI協助解決了生物學裡困擾半個世紀的蛋白質折疊難題。
AlphaFold是一個很好的例子,它的示範意義在於,開發AlphaFold的DeepMind選擇了一些已有足夠的基礎和資料積累、有可能突破的難題,然後組建一個頂尖的團隊,下決心去攻克。在自然科學領域,有著很多重要的開發性問題,AI還有更大的機會,可以去發掘新材料、發現晶體結構,甚至去證明或發現定理;AI可以顛覆傳統的研究方法,甚至改寫歷史。以量子力學最核心的薛丁格方程式為例,現在已有物理學家透過資料複現,用AI可以自動推理出薛丁格方程式,甚至還發現了另外一個寫法。這正是一件非常了不起、有可能改變物理學甚至人類未來的事情。
同樣舉例來說,阿里巴巴達摩院正在推進的AI EARTH計畫,是將AI引入氣象領域。天氣預報已有上百年歷史,是一個非常重大和複雜的科學問題,需要超級電腦才能完成複雜計算,不僅消耗大量資源而且尚未能做到非常準確。阿里巴巴達摩院正嘗試以AI解決這個問題,試圖讓天氣預報變得既高效又準確。
AI研究者:多一點興趣少一點功利
AI的當下局面,是對包括筆者在內,所有AI研究者的考驗。不管是AI的基礎理論突破,還是嘗試用AI去解決科學問題,都不是一蹴而就的事情,需要研究者們既聰明又堅定。但更關鍵的是興趣驅動,而不是利益驅動,不能急功近利。近幾年深度學習的繁榮,使得不少人才和資金湧入AI領域,快速推動AI產業發展,但也催生了一些不切實際的期待。像DeepMind做了AlphaGo之後,一些人跟進複製,但對於核心基礎創新進步來說意義相對有限。
既然AI還不是一門科學,AI研究者要去探索沒人做過的事情時,就很有可能失敗。這意味著AI研究者們必須有真正的興趣,靠興趣和好奇心去驅動自己前行,才能克服無數的失敗。我們也許看到了DeepMind在AlphaGo和AlphaFold兩個計畫上的成功,但很可能還有更多失敗的、無人聽聞的計畫。
所有AI研究者亦不必妄自菲薄,承認AI還比較初級並非否定從業者的努力,而是提醒人們需要更堅定地長期努力,不必急於一時。電氣時代如果沒有法拉第這些先行者,沒有一個又一個的點狀發現,不可能總結出理論,讓人類邁入電氣時代。
同樣,AI發展有賴以重大創新為憧憬,一天天努力,不斷嘗試新想法,然後才會有一些小突破。當能夠將這些點狀的突破連接起來,總結出理論時,AI才會產生重大突破,最終成為一門科學。
我們已經半隻腳踏入AI時代的大門,這註定是一個比電氣時代更加輝煌、激動人心的時代,但這一切的前提,都有賴於所有研究者堅定不移的努力。
<本文作者:金榕現為阿里巴巴達摩院副院長、原密西根州立大學終身教授。>