DRBD(Distributed Replicated Block Device)技術的設計概念是,採用即時同步兩端主機間區塊裝置(Block Device)資料內容的資料保全解決方案,簡言之,可以將DRBD技術理解為兩端主機中硬碟的鏡像同步技術(RAID-1)。
由於DRBD技術的資料同步技術是透過乙太網路進行交換,而非儲存設備控制器,所以稱之為網路鏡像同步技術(Network RAID-1),將更為貼切。
DRBD運作原理說明
在DRBD運作架構圖中,可以看到兩台主機透過DRBD技術所建構的資料保全解決方案,每一台主機包含Linux核心(Kernel)、檔案系統(File System)、緩衝區快取(Buffer Cache)、磁碟讀寫調度器(Disk Scheduler)、磁碟驅動程序(Disk Driver)、實體網路卡及TCP/IP協定。
其中,透過箭頭方向可以非常清楚的了解到DRBD技術是如何透過網路傳輸來同步兩台主機之間區塊裝置(硬碟)內的資料。
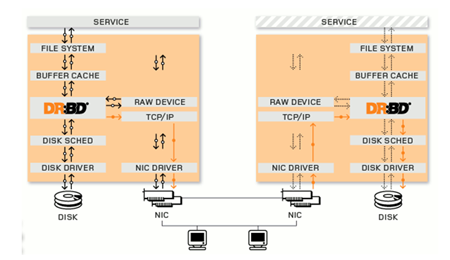 |
| ▲DRBD技術運作流程圖。(圖片來源:DRBD官網「What is DRBD」) |
叢集主機修改DRBD設定檔
安裝好相關套件之後,首先修改DRBD設定檔(/etc/drbd.conf)。此次實作採用的CentOS為32位元版本,因此設定檔中指定的heartbeat執行檔資料夾,其路徑為「/usr/lib/heartbeat」。
如果採用的是64位元版本的CentOS,那麼heartbeat執行檔資料夾的路徑將為「/usr/lib64/heartbeat」。
請注意,若DRBD設定檔內容中heartbeat執行檔資料夾路徑指定錯誤,則會因為叢集服務找不到相對應的執行檔,而造成叢集運作失效的狀況發生,下列修改的DRBD設定檔內容,在叢集主機Node1、Node2上都是一樣的。
DRBD設定檔修改完成後,請調整DRBD相關執行檔案的權限,以便後續建立DRBD資源時,指令能夠順利執行,而不致發生錯誤。
但如果省略此調整DRBD檔案權限的步驟,後續操作過程將會出現錯誤,此一調整檔案權限的動作,在叢集主機Node1、Node2都必須進行。
檔案權限調整完畢,接著使用modprobe指令來載入DRBD模組至作業系統中,並配合lsmod指令檢查模組是否載入完成。
待確認載入DRBD模組的動作已經完成,則必須執行dd指令將一些資料寫入到sdb硬碟內,否則後續執行drbdadm指令建立DRBD資源時會發生錯誤訊息,並且無法進行後續的操作步驟。
執行指令「drbdadm create-md」來建立DRBD資源。由於本例在DRBD設定檔中指定其資源名稱為ha,所以此處指令參數便輸入「ha」。下列執行指令來建立DRBD資源的動作,在叢集主機Node1、Node2上都必須執行才可以。
當Node1和Node2叢集主機都完成建立DRBD資源之後,便可以準備啟動DRBD服務。啟動DRBD服務時,先於Node1主機上啟動DRBD服務。此時,DRBD服務會進入60秒讀秒倒數等待(等待DRBD設定檔中所設定的另一台叢集主機),這時候再切換至Node2主機啟動DRBD服務。
如果兩台節點主機設定正確無誤,便皆可順利啟動DRBD服務。完成啟動DRBD服務後,記得設定DRBD服務於開機時自動啟動。
啟動DRBD服務之後,可以分別至Node1、Node2主機查看目前DRBD的運作狀態。若上述動作未能同時在兩台節點主機啟動服務,而是Node1主機啟動DRBD服務但Node2未啟動服務,則Node1主機在讀秒倒數完畢(timeout)時會發現其DRBD狀態為Secondary/Unknown,必須要等到Node2主機啟動DRBD服務後,狀態才會轉變為Secondary/Secondary。其中,ds欄位狀態資訊為Inconsistent,表示兩台叢集主機區塊裝置(/dev/drbd0)資料尚未進行同步。
初始化Node1叢集主機的sdb硬碟資料(僅Node1設定)
當確定Node1和Node2主機都可以互相偵測到對方主機存在(Secondary/Secondary)後,便可以執行drbdadm指令並配合primary參數,將Node1主機提升為Primary Node(屆時的Active Node),並啟動兩台叢集主機開始同步sdb硬碟資料(也就是/dev/drbd0)。
當執行同步資料的動作開始後,可以透過指令「watch -n 1 service drbd status」來即時查看DRBD運作狀態,了解兩台主機同步硬碟資料的百分比及進度。但須注意,此一執行drbdadm指令的操作動作僅在Node1主機上執行即可,Node2主機不必執行。也就是說,Node2主機的區塊資料及同步的來源為Node1主機。
當兩台叢集主機同步作業完成後,此時再度查看DRBD狀態,可以發現兩台主機的ds欄位狀態資訊,已經由原本的Inconsistent轉變為UpToDate,此狀態資訊即表示兩台叢集主機之間的區塊裝置,其資料已經同步完成兩台叢集主機擁有相同且最新的資料。
此時,在Node1主機上所看到DRBD狀態,可以得知目前Node1主機為Primary Node(也就是Active Node),而從Node2主機看到的狀態則是Secondary Node(也就是Standby Node)。
格式化sdb磁碟資料(僅Node1設定)
在Node1和Node2兩台主機之間完成資料同步作業後,也就是「/dev/drbd0」已經完成初始化,接著便可以使用mkfs.ext3指令來格式化「/dev/drbd0」區塊裝置。
待格式化動作完成後,在根目錄(/)下建立storage資料夾,並將「/dev/drbd0」裝置掛載至剛才建立的「/storage」資料夾,然後在掛載後使用df指令來確認系統是否掛載成功。
請注意,mkfs.ext3格式化指令僅於Node1主機執行即可,在Node2主機上不需要執行,因為兩台叢集主機區塊裝置已經同步完成,因此在一台主機上執行格化即可。
啟動iSCSi Target服務並測試資料寫入
作業系統完成掛載「/dev/drbd0」裝置之後,便可以啟動iSCSI Target服務,並於啟動服務完成後,檢查系統是否已經正確開啟相關的服務Port 3260,並且記得設定系統開機後自動啟動iSCSI Target服務。
接著,使用dd指令來建立指定大小9GB的檔案於「/storage」資料夾內,此檔案也就是屆時iSCSI Initiator(VMware vSphere Hypervisor)所要掛載的共用儲存空間Datastore。
或許,讀者會疑惑為何不直接使用「/storage」這個掛載點來擔任共用儲存空間就好了?因為此次實作採用的是軟體式的iSCSI Target,若直接使用該分割區擔任共用儲存空間,則當iSCSI Initiator等到掛載該儲存空間時,將會發生掛載失敗的現象。請注意,僅須在Node1主機上啟動iSCSI Target服務及dd指令,Node2主機方面則不需執行。
接著,建立iSCSI Target儲存資源的iSCSI認證名稱(iSCSI Qualifier Name,IQN),以及指定使用剛才建立的9GB大小作為其儲存空間。最後,設定ACL存取限制清單只允許10.10.25.x網段的主機才可以掛載這個iSCSI Target所分享的共用儲存資源。當然,也指定允許單一IP位址或網域名稱。
其中,iSCSI認證名稱為iSCSI Initiator與iSCSI Target,拿來作為互相識別之用,即屆時iSCSI Initiator前端設備發起存取儲存資源的要求時,iSCSI Target便能依照相關設定回應其存取要求。
而IQN名稱的命名格式為「iqn + 日期 + 反向網域名稱 + 主機名稱」。此次實作的IQN名稱為「iqn.2011-03.org.weithenn:iscsi.storage」。這個啟動建立iSCSI Target儲存資源的指令,僅於Node1主機上執行即可。
在確定iSCSI Target(tgtd)服務可以將「/storage/iscsi」檔案順利掛載為儲存資源後,便可以準備設定高可用性服務Heartbeat部分。
但在設定以前,必須先將Node1主機中iSCSI Target服務停止,並把「/dev/drbd0」區塊裝置進行卸載的動作,且將Node1主機先行降級為Secondary Node,以避免設定高可用性服務過程中受到影響。此動作僅於Node1主機執行即可,Node2主機上毋須執行。
Heartbeat技術運作原理
高可用性的容錯機制「錯誤後轉移(Failover)」通常有三種方式,分別為「動態DNS」、「IP位址接管」以及「MAC位址接管」。其中,「動態DNS」為透過更新DNS設定的方式將網域名稱所對應的IP位址指向備援的節點主機,以達到容錯機制;「MAC位址接管」則為當主要節點主機發生問題時,備援節點主機將本身的MAC位址修改為原先的ARP快取所記載的主要節點主機MAC位址,以達到容錯機制。
此次高可用性服務實作所採用的容錯技術為第二種「IP位址接管」,亦即在叢集主機中Active Node將會產生一組虛擬叢集IP位址(Cluster IP Address)來提供服務,當Client端送出存取服務要求時,擁有虛擬叢集IP的Primary Node(Active Node)便會回應Client端的回應(如運作圖中上半部所示),而當Primary Node出現問題時,運作於其上的Heartbeat服務便會自動將服務切換至Secondary Node(Standby Node)。
此時,它便會擁有虛擬叢集IP位址,同時修改ARP Cache內該虛擬叢集IP位址所對應的MAC位址,進而順暢無誤地接手後續Client端相關服務(如運作圖中下半部所示)
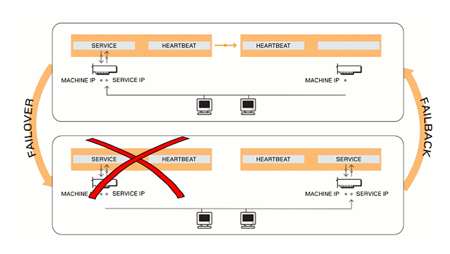 |
| ▲Heartbeat技術運作流程圖。 (圖片來源:DRBD官網「What is HA」) |
若是希望具備「錯誤後回復(Failback)」機制,也就是當Primary Node出現問題時將服務自動轉移給Secondary Node,等到Primary Node排除錯誤並修復完成後,重新回到叢集網路,可以自動地將主動權再度搶回的機制。此次採用的Heartbeat高可用性套件也以做到。
但是這樣的錯誤後回復機制,到底好不好,其實見人見智。以筆者過去的經驗來說,便不建議如此設定,原因在於這樣的錯誤後回復機制有可能會造成「叢集節點抖動」。
例如,當Primary Node伺服器所處的電力迴路不穩定時,便可能造成這樣的狀況,當電力迴路供電不穩定時,Heartbeat將服務自動切換給Secondary Node進行服務接手的動作,待電力恢復穩定後,Primary Node又將主動權搶回,並且當電力再度不穩定時,又再次將服務切換給Secondary Node接手。
雖然切換叢集主機節點之間所耗費的時間並不長,但若造成高頻率的叢集節點抖動切換,對於使用者來說,仍會感覺到服務不順暢。
因此,筆者建議不要設定錯誤後回復機制,而是設定當錯誤後轉移的狀況發生時,系統自動切換服務並且通知管理者,待管理者了解叢集主機切換的原因並排除之後,再評估是否要讓Primary Node搶回主控權。
設定Heartbeat通訊設定檔
在此次實作的Heartbeat通訊設定檔(/etc/ha.d/ha.cf)內容中,設定每2秒鐘叢集主機便會透過Heartbeat線路(bond1)使用ICMP協定中的Ping功能來互相偵測對方是否仍然存活。
當超過5秒鐘仍然無法偵測到對方主機存活時,則會將警告訊息寫入指定的紀錄檔中(/var/log/ha-log)。若超過15秒鐘後仍然無法偵測對方主機存活,則判定為對方主機失效,系統會觸發錯誤後轉移機制(Failover),Secondary Node將準備接手相關服務及儲存資源。
當發生叢集節點主機無法偵測對方主機是否存活時,會先執行Ping指定的IP位址,例如此次實作中採用的Gateway IP位址(10.10.25.245)。
這樣的機制是為了防止叢集主機之間的Heartbeat線路發生中斷時,讓兩台節點主機誤以為對方主機失效而爭相要接手為Active Node,進而造成裂腦(Split-Brain)的情況發生。設定檔中最後一行「auto_failback off」,則是設定不啟用錯誤後回復機制(Failback)。
Node1及Node2主機在通訊設定檔內容中的不同處,僅為ucast所指定的IP位址,其餘都相同。並且要注意的是,Node1主機指定的bond0、bond1 IP位址為Node2主機的IP位址,而非自已主機上的bond0、bond1 IP位址,因為這裡的IP位址為用來偵測對方主機是否存活之用。
● 叢集主機Node1設定
ucast bond0 IP位址:10.10.25.138
ucast bond1 IP位址:192.168.1.2
● 叢集主機Node2設定
ucast bond0 IP位址:10.10.25.137
ucast bond1 IP位址:192.168.1.1
設定Heartbeat資源設定檔
接下來設定Heartbeat資源設定檔(/etc/ha.d/haresources),此資源設定檔內容在Node1及Node2主機中皆一模一樣。此一資源設定檔內容表示,Heartbeat服務預設將使用Node1主機擔任Primary Node角色。此設定檔內容可以分為五個區段來看,其意義如下:
1. 指定Primary Node的FQDN:node1.weithenn.org
2. 指定虛擬叢集IP位址(Cluster IP):10.10.25.136
3. 指定叢集資源名稱(Cluster Resource Name):drbddisk::ha
4. 指定叢集裝置(Cluster Device)、掛載點(Mount Point)、檔案系統格式(File System Type):Filesystem::/dev/drbd0::/storage::ext3
5. 指定高可用性服務名稱(Heartbeat Service):iscsi-target
而Heartbeat資源設定檔內容如下所示:
設定Heartbeat驗證設定檔
此Heartbeat驗證設定檔(/etc/ha.d/authkeys)為叢集主機節點(Cluster Node)之間的驗證密碼檔案,也就是叢集主機節點都必須具備此一驗證密碼檔,才會被認為是身處於同一個叢集中的節點。
此次實作採用sha1編碼方式並配合urandom指令,將一堆亂數寫入Heartbeat驗證設定檔內當作叢集驗證密碼。
最後,記得將此驗證設定檔權限設定為600(只有root能讀寫),否則屆時Heartbeat服務將因為此驗證設定檔安全性不足而啟動失敗。
此驗證設定檔內容在Node1及Node2主機中都是一樣的。可以在Node1主機執行完成後,利用scp指令將此驗證設定檔複製到Node2主機中,以便保持密碼檔案及權限設定一致。
設定Heartbeat監控服務設定檔
因為預設的Heartbeat服務設定檔內並沒有提供iSCSI Target服務使用的範例設定檔,因此只好自行編寫此監控服務設定檔(/etc/ha.d/resource.d/iscsi-target)。
此監控服務設定檔的作用在於,當Primary Node發生問題而Secondary Node欲接手相關服務時,Heartbeat服務便是依據此監控服務設定檔內容決定要在Secondary Node啟動什麼服務,進而接手哪個虛擬叢集IP位址、掛載哪些叢集資源及裝置。
設定好此監控服務設定檔後,給予755的權限,以便Heartbeat服務能夠執行該啟動服務檔案。此監控服務設定檔內容於Node1及Node2主機中都一樣,可以在Node1主機執行完成後,利用scp指令將此驗證設定檔複製到Node2主機中,以便保持監控服務設定檔及權限設定一致。下列為監控服務設定檔內容:
由於單單啟動iSCSI Target服務並不會將相關設定載入,例如設定IQN名稱、掛載「/storage/iscsi」、設定ACL存取清單等等。
因此為了配合上面的Heartbeat監控服務設定檔,在Secondary Node接手服務後能夠自動掛載iSCSI Target儲存資源,須要將相關掛載iSCSI Target的動作撰寫為Script(/usr/local/sbin/tgtd.sh)來自動化執行。
此掛載iSCSI Target資源設定檔內容於Node1及Node2主機中皆相同,可以在Node1主機上執行完成後,利用scp指令將此設定檔複製到Node2主機。當然,也別忘了將檔案權限設定為755之後再進行傳送的動作。此處所建立的Script檔案內容如下:
新增Heartbeat為系統服務
接下來,將Heartbeat服務新增至系統服務中,除了日後便於管理之外,也將於系統開機時自動啟動Heartbeat服務。
請注意,Heartbeat的服務必須要比DRBD的服務晚啟動才行,否則系統在啟動的過程當中會因為DRBD的服務尚未啟動(「/dev/drbd0」尚未掛載),因而造成Heartbeat服務啟動失敗,系統將因此而產生錯誤。
該項新增Heartbeat為系統服務的動作在Node1及Node2主機都必須執行,新增為系統服務後,記得在Node1和Node2主機上啟動Heartbeat服務。
開機自動掛載iSCSI Target資源(僅Node1設定)
因為iSCSI Target的儲存設定在預設情況下重新開機後,相關設定會消失不見,所以必須把iSCSI Target儲存資源的的設定檔(/usr/local/sbin/tgtd_boot.sh)寫在「/etc/rc.local」內,以便系統開機時自動掛載iSCSI Target儲存資源。
但是,此Script檔案與先前所撰寫的「/usr/local/sbin/tgtd.sh」執行檔內容有些不同,差異在於必須延遲60秒左右後再執行設定掛載iSCSI Target儲存資源的動作。
請注意,此一開機用的執行檔僅在Node1主機上設定就可以了,Node2主機上不需要設定。該執行檔的詳細內容如下所示:
待續
在本文中已經設定好iSCSI Target的儲存資料屆時會透過網路鏡像同步技術(Network RAID-1),也就是資料保全解決方案DRBD,即時地將儲存資料進行同步以達到資料保全的目的,並設定高可用性容錯機制「錯誤後轉移(Failover)」中的IP位址接管技術,套用於iSCSI高可用性服務上,且設定當叢集主機需要硬體檢休或因為歲休而需要關機,能夠在開機時自動掛載iSCSI Target相關資源,並自動運作起來。
至此,iSCSI Target的設定已經完成並且正常運作,在下篇文章中將實作iSCSI Initiator主機如何存取iSCSI Target所分享的儲存資源,並且在iSCSI高可用性服務上線之前進行相關的災難演練測試,以便當災難真的發生時不致手忙腳亂。
此外,也可以藉著災難演練建立企業的相關災難回復SOP,同時當遇到特殊情況須要將兩台叢集主機都關機時(例如更換機房),叢集主機應如何正確關機及開機,以確定叢集服務運作無誤,其標準作業流程在下篇文章中也將詳細討論細節。