儘管邊緣AI能夠帶來諸多優勢,例如能對資料進行即時處理、減少延遲、能降低對外部伺服器發送機敏資料的需求、更有效地利用網路頻寬以及延長邊緣設備的壽命。但就實務上來看,多元件的整合與無縫協作卻是邊緣AI目前面臨的極大挑戰之一,特別是如何管理異質的硬體與軟體環境。
隨著行動運算與物聯網(IoT)快速地擴展,如今全球已有超過百億台的物聯網設備在邊緣網路相互連接,這些在邊緣產生的大量資料,若是要一一回傳到雲端資料中心才能取得回應,不只緩不濟急,網路延遲與高頻寬帶來的成本也是亟需應對的課題。邊緣AI的發展將有助於解決這些挑戰,將人工智慧帶到邊緣端,藉由人工智慧與邊緣裝置的結合,來實現更為即時的資料處理與回應,並且成為企業數位轉型中,邁向自主營運不可或缺的關鍵。
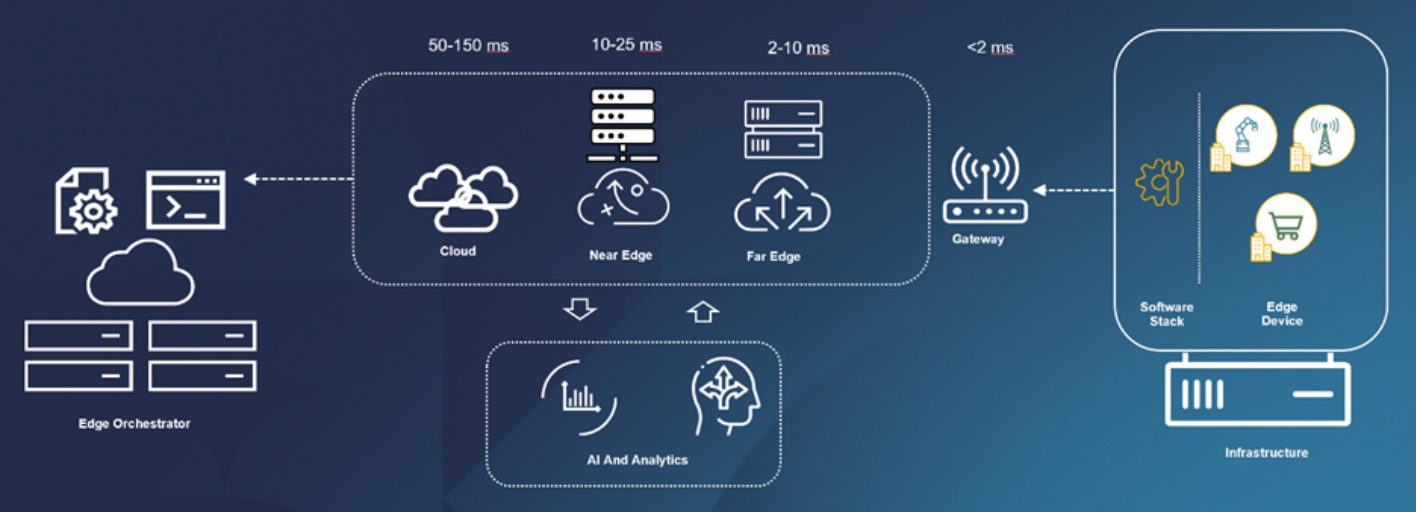 典型的邊緣運算架構示意圖。(來源:Dell官網)
典型的邊緣運算架構示意圖。(來源:Dell官網)
儘管邊緣AI能夠帶來諸多的優勢,例如能對資料進行即時處理、減少延遲、能降低對外部伺服器發送機敏資料的需求、更有效地利用網路頻寬,甚至因為不需要與雲端持續地通訊,反而更能延長邊緣設備的壽命,並帶來節能的成效。但就實務上來看,多元件的整合與無縫協作卻是邊緣AI目前面臨的極大挑戰,特別是如何管理異質的硬體與軟體環境。
對此,Dell也推出邊際運作軟體平台Dell NativeEdge,可協助企業集中部署和管理跨地理位置的邊緣基礎架構和應用程式。透過自動化與零接觸的佈建,企業得以大幅簡化邊緣作業,還可以跨混合環境實現應用程式的協調(Orchestration),企業不僅可以使用Blueprint去部署與管理邊緣應用程式,不只是NativeEdge Endpoints(戴爾專用邊緣設備,包含Dell Edge閘道器、直立式OptiPlex以及PowerEdge伺服器),還可以透過vSphere虛擬化和Kubernetes叢集到其他戴爾和非戴爾基礎架構的多雲。
此外,Dell也引進了虛擬信任平台模組(vTPM)和支援UEFI安全啟動功能(UEFI Secure Boot capabilities)。其中,vTPM是TPM的虛擬化版本,TPM是以硬體為基礎的安全功能,可提供加密功能和安全儲存。vTPM可讓在NativeEdge端點上執行的VM使用TPM功能,例如加密VM磁碟、驗證VM完整性以及證明VM身分。而UEFI安全啟動功能可確保只有授權且受信任的軟體才能在NativeEdge端點上啟動,從而防止未經授權或惡意軟體損害邊緣裝置。
補足OT管理與維運
台灣戴爾科技集團技術副總經理梁匯華指出,過往IT與OT彼此之間的分野非常明確,但是如果要讓邊緣AI能夠落地實現,IT與OT其實是密不可分的,重點即在於,OT如何運用IT的能量去優化過去做不到的事情,舉例而言,戴爾專用邊緣設備為什麼要支援多種OT的通訊協定,目的就是為了要能管控這些邊緣裝置,例如產線機台或冷鏈冰箱,以確保OT的環境能夠永遠運行。過去,OT出現故障,需要人員到現場修繕,現在則可以利用IT的架構去補足,例如可以準備好兩台裝置,當其中一台故障時,另一台就能馬上接手繼續調控。雖然OT也能做到,但因為都是專有的設備與架構,相對就要付出較高昂的成本代價,現在透過軟體定義的方式,很輕鬆就能實現。
「許多企業都忽略了OT的管理與維運,但這點非常重要。IT能夠協助OT的地方就是讓OT永遠處於最佳化,這是兩者之間最完美的協作。」他以特斯拉(Tesla)為例進行說明,特斯拉電動車與他牌電動車最大的不同在於,特斯拉具備了很高程度的軟體定義,許多新功能只要透過空中下載(OTA)更新就完成了,但是傳統車廠設計的電動車現今還有許多OT的包袱無法抛開,很多架構設定都是專有的設定,這也是差異所在。
詳述邊緣架構分類
根據Market Research Future預估,全球邊緣AI硬體市場將從2023年的26.86億美元成長到2023年的159.88億美元,年複合成長率達21.92%。
Dell在官方部落格中提到了AI時代下的邊緣運算架構,從中也能一窺邊緣AI硬體發展的不同面向,舉例而言,感測器或物聯網裝置主要負責從各處來源收集和產生資料,充當資料處理的第一站;具有較強運算能力、儲存和網路功能的邊緣伺服器或邊緣節點,則能負責運行邊緣應用程式並在本地處理資料;另外,邊緣閘道器則是充當中介的角色,能聚合和過濾來自多個設備的資料,執行初始預處理,並確保與其他元件的安全通訊。
 台灣戴爾科技集團技術副總經理梁匯華指出,過往IT與OT彼此之間的分野非常明確,但是如果要讓邊緣AI能夠落地實現,如何運用IT的能量去優化OT是一大關鍵。
台灣戴爾科技集團技術副總經理梁匯華指出,過往IT與OT彼此之間的分野非常明確,但是如果要讓邊緣AI能夠落地實現,如何運用IT的能量去優化OT是一大關鍵。
雖然邊緣運算強調的是靠近資料的位置進行處理,但通常也會連接到集中式的雲端或資料中心來執行某些任務,在這裡,Dell也依據所處的位置區分為遠邊緣(Far Edge)與近邊緣(Near Edge)。而邊緣AI則是在邊緣部署人工智慧演算法和模型,進行本地推論和決策。
梁匯華指出,邊緣AI設備依據邊緣所有的位置,其所需的運算能力會有所差異,理論上位置越遠端,環境就越艱難,運算力需求也越小,因此,大多數的使用情境均是以執行推論為主。如果企業想要進行生成式AI相關的模型訓練或微調,通常就會回到資料中心或是雲端完成。簡單來說,初階或終端的使用者想要運生成式AI,那麼AI PC本身具備的40 TOPS(Trillion Operations Per Second)運算效能即可滿足,若是打算進行更進階的AI開發或是較大模型推論,AI開發者可選擇AI工作站,如果需要GPU來進行相關的運算,那麼就得選擇伺服器來實現。
資料由各部門管控回歸專業
「然而,企業在導入任何解決方案之前,首要還是得先有明確的AI業務戰略目標」,他提到,AI全生命週期有五部曲,第一步即是確認到底AI在企業中擔任何種角色,以及打算在哪些層面應用。其次是準備訓練AI的資料,訓練資料的數量和品質,會決定了AI演算法規模的上限。接下來的第三、第四以及第五個步驟才會是模型的預訓練、微調以及推論。「從第三到第五個步驟會是一個循環,即便企業已經在邊緣進行推論,所有的回饋還是會再回來進行增強學習(Reinforcement Learning),增強學習後的資料又會進行微調或是重新訓練模型。」
梁匯華指出,過去有不少企業把所有資料都集中到一個平台中,當有不同的處理流程需要使用到資料的時候,就從資料中台來取得。但缺點是企業很難確保各部門的資料會百分之百到中台,因為有些業務資料的機敏性較高,或是即便全部的資料都到中台,也可能存在很多Garbage Data,因此現在也有一種作法是採取Data Mesh(資料網格)架構,讓企業內部每一個部門都擁有自己的Data Fabric,資料由各個部門自己管控,好處是可以回歸專業,因為最懂該部門資料的人就位於部門之中,如此一來,每個部門都可以做好核心優勢的產品,發揮資料價值。