微軟推出的Foundry Local讓只有CPU中央處理器的Windows Server 2025主機也能運作中小型的AI語言模型。本文將深入剖析Foundry Local的運作架構,並透過實作的方式講解如何下載及運作AI模型,以及說明在整合Open WebUI之後為何能夠讓管理人員與AI模型的互動更加地友善與便利。
在企業和組織的營運日常中,IT管理人員最常遭遇到的挑戰之一,就是如何在兼顧執行效能,以及安全與符合法規的前提之下導入新技術。
AI大型語言模型的推論能力,在這一兩年來已經成為非常熱門的話題,然而絕大多數的解決方案大都需要仰賴雲端環境,對於需要嚴格保護資料的企業和組織來說,卻往往是難以跨越的障礙,尤其在金融、醫療或政府單位,這些機敏資料很難直接送到雲端環境去跑AI模型推論。
此外,AI大型語言模型雖然功能全面且強大,但是對於IT預算本來就不多的中小型企業組織來說,要導入時可能沒有那麼多IT預算來支撐,不導入的話又無法將現有的工作流程透過AI模型進行簡化和加速,其他具備生產力的好主意也無法以AI模型進行推論或實作。因此,微軟推出的AI Foundry Local便正好能夠滿足中小型企業和組織的需求,並且即便運作Foundry Local的主機不具備GPU圖形處理器,只有單純的CPU中央處理器,雖然不能運作AI大型語言模型,但也能運作中小型的AI語言模型,相信也能滿足IT預算不足的中小型企業的需求。
Foundry Local運作架構簡介
如圖1所示,Foundry Local的運作架構主要在於希望把雲端環境的AI模型便利性,也能夠在企業和組織的地端資料中心內使用。運作核心的組成包含幾個部分,首先最外層是Foundry Local服務,這是一個相容於OpenAI的REST API,讓開發人員能採用熟悉的方式呼叫AI模型,確保應用程式無須大改動,就能整合AI能力。
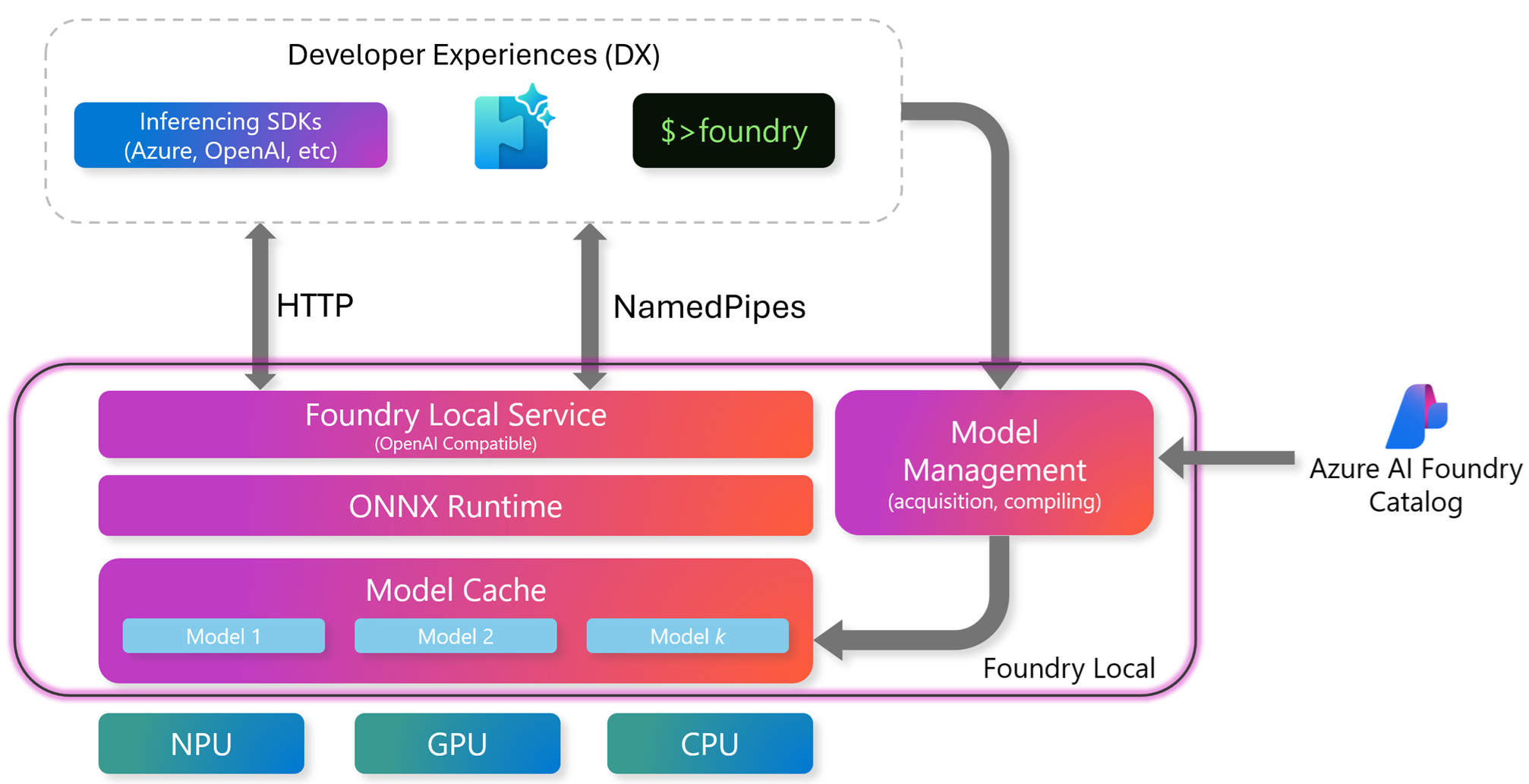 圖1 Foundry Local運作架構示意圖。 (圖片來源:Foundry Local架構 - Foundry Local | Microsoft Learn)
圖1 Foundry Local運作架構示意圖。 (圖片來源:Foundry Local架構 - Foundry Local | Microsoft Learn)
其次是ONNX Runtime,這是AI推論的核心引擎,支援硬體伺服器採用CPU、GPU、NPU等等多種硬體,並且微軟與NVIDIA、AMD、Intel、Qualcomm等等供應商合作,確保能夠達到跨平台一致性的目標,讓企業組織能夠依照現有運作環境,選擇最合適的硬體伺服器,而不必受限於單一供應商。
事實上,微軟還為Foundry Local提供Olive編譯工具,能把Hugging Face等來源的AI模型轉換為ONNX格式並進行優化,讓AI推論的執行效能更佳。另一個值得注意的設計是硬體抽象層,透過「執行提供者」(Execution Provider)的概念,讓同一個AI模型可以在不同的硬體伺服器上執行,並且不需要額外修改程式碼。舉例來說,在Windows伺服器上使用Intel NPU或Qualcomm NPU時,只要安裝相對應的驅動程式,就能直接享有硬體加速運作AI模型的效益。
在AI模型管理方面,Foundry Local提供AI模型快取機制,讓管理人員能夠輕鬆將AI模型進行下載,並且快取儲存在本機SSD固態硬碟當中,避免每次執行AI模型時就要先下載的麻煩和無謂的等待時間。
下載後的AI模型若不常使用的話,也可以透過CLI指令隨時查詢、移除、更新快取等等,確保系統維持在最佳狀態。
除了AI推論引擎與模型管理外,Foundry Local也提供完整的工具鏈,管理人員只要透過CLI工具,即可快速下載執行或卸載用不到的AI模型,而在開發人員方面,則能夠透過相容於OpenAI的SDK進行整合,同時微軟也在Visual Studio Code中提供AI相關工具,讓開發人員可以在IDE內直接管理AI模型,並且視覺化推論的結果,使得企業組織的管理人員能夠透過這些工具讓AI模型的開發測試和維護作業更透明並且更容易追蹤。
簡單來說,Foundry Local能夠提供給企業和組織許多面向的價值,舉例來說,在法規檢查方面,由於機敏資料可以在本地端的AI模型中直接推論和分析,所以不必擔心外洩風險。在資源管控方面,AI模型可以即時分析CPU、記憶體或硬碟使用率,協助預測潛在的硬體資源瓶頸。
在災難復原演練方面,即使網路發生中斷,AI模型仍然能夠在本地端繼續執行,確保系統維持一定的智慧化能力。至於例行性的安全性更新和檢查作業,AI模型也能協助分析系統更新狀態,提供更精準的日常維護建議。
開始實戰Foundry Local on WS2025
接下來,就來動手實作Foundry Local on WS2025。
建立Azure VM雲端虛擬主機
由於中小型企業或組織在IT預算不多的情況下,可能沒有多餘的測試主機讓IT管理人員能夠建立測試環境。此時,也能利用建立Azure免費帳戶的方式,部署Azure VM雲端虛擬主機的方式,達到快速建構和測試AI Foundry Local在Windows Server 2025運作的目的。
在作業系統版本方面,選擇採用Windows Server 2025 Standard或Datacenter版本即可,在硬體資源需求方面,原則上最低需求只要8GB記憶體和3GB可用磁碟空間,但實際上會建議具備16GB記憶體和15GB可用磁碟空間比較保險。
可能已經有IT管理人員接著發出疑問,要跑AI模型一定需要GPU對吧?事實上,在Foundry Local的運作環境中若擁有硬體GPU或NPU,確實能夠讓屆時的AI模型運作更快反應更順暢,倘若只有單獨的CPU時,那麼Foundry Local也能跑AI模型,只是執行效能或反應可能不是令人滿意,但IT管理人員仍然能夠達到測試的目的。
本文實作環境,便在Azure雲端環境中建立一台僅具備CPU硬體運算資源,而沒有GPU硬體的雲端VM虛擬主機,並採用Windows Server 2025 Datacenter雲端作業系統版本(圖2)。
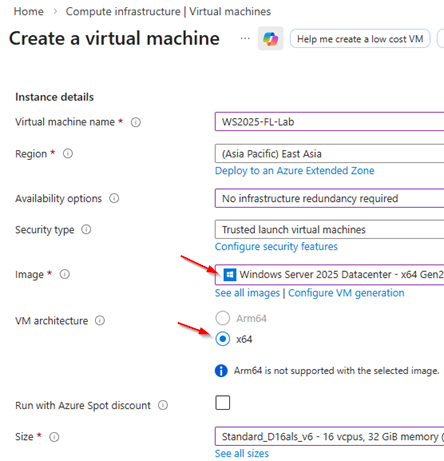 圖2 建立僅具備CPU硬體運算資源的雲端VM虛擬主機。
圖2 建立僅具備CPU硬體運算資源的雲端VM虛擬主機。
安裝Foundry Local
由於本文實作環境為單純的CPU硬體運算資源的VM虛擬主機,已經滿足安裝Foundry Local運作環境條件,若是配置GPU或NPU運算資源時,須先處理好GPU或NPU驅動程式的部分,舉例來說,如果使用Intel NPU硬體,先確保已經安裝Intel NPU驅動程式,以便在Foundry Local運作環境中啟用NPU加速機制。
順利登入Windows Server 2025主機後,只要開啟Terminal視窗,鍵入「winget install Microsoft.FoundryLocal」指令,並回答「Y」同意授權條款,系統便會自動找尋最新釋出的Foundry Local版本,再透過內建的Winget機制下載後執行安裝作業。待安裝作業完成後,鍵入「foundry --version」指令,確認目前安裝的Foundry Local版本,可以看到目前安裝的最新版本為0.8.119,如圖3所示。
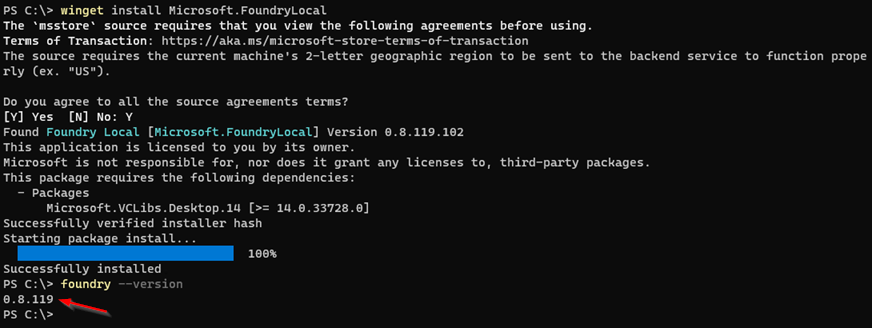 圖3 在Windows Server 2025主機上安裝Foundry Local。
圖3 在Windows Server 2025主機上安裝Foundry Local。
查詢運作狀態
在條列和載入AI模型之前,先確認Foundry Local的運作狀態,確保稍後能夠順利地下載並載入AI模型。
首先執行「foundry service status」指令,確認為綠燈執行狀態,並且顯示API Endpoints資訊,本文實作環境為「http://127.0.0.1:50276/openai/status」,接著執行「foundry service list」指令,檢查系統是否已經有載入任何AI模型,如圖4所示。
 圖4 檢查Foundry Local運作狀態。
圖4 檢查Foundry Local運作狀態。
此外,由於這台雲端VM虛擬主機僅配置CPU硬體運算資源,所以在Foundry Local服務狀態的第二行中,可以看到一則「CPUExecutionProvider」資訊,表示這台Foundry Local稍後載入AI模型時將會下載及執行適用於CPU硬體運算資源的AI模型,倘若配置的是NVIDIA CUDA GPU硬體運算資源,則會顯示「CUDAExecutionProvider」資訊。
預設情況下,除非IT管理人員進行額外設定,否則Windows Server 2025主機重新啟動後,Foundry Local服務並不會自動啟動,此時便可以透過「foundry service start」指令進行Foundry Local服務啟動作業,下列為Foundry Local服務相關指令與說明:
‧foundry service --help:顯示所有Foundry Local服務的相關指令參數與用途說明。
‧foundry service start:啟動Foundry Local服務。
‧foundry service stop:停止Foundry Local服務。
‧foundry service restart:重新啟動Foundry Local服務。
‧foundry service status:顯示Foundry Local服務目前的運作狀態。
‧foundry service list or ps:顯示目前已經載入Foundry Local服務的所有AI模型。
‧foundry service set:組態設定Foundry Local服務。
‧foundry service init:重新執行Windows的EPs自動註冊程序。
‧foundry service diag:顯示Foundry Local服務的日誌資訊。
運作AI模型
在開始下載並運作AI模型之前,管理人員可以先執行「foundry model list」指令,條列出目前Foundry Local服務支援的AI模型,以及運作這些AI模型的相關資訊,例如支援CPU或GPU硬體運算資源、AI模型大小等等資訊,如圖5所示,下列為每個欄位的意義說明:
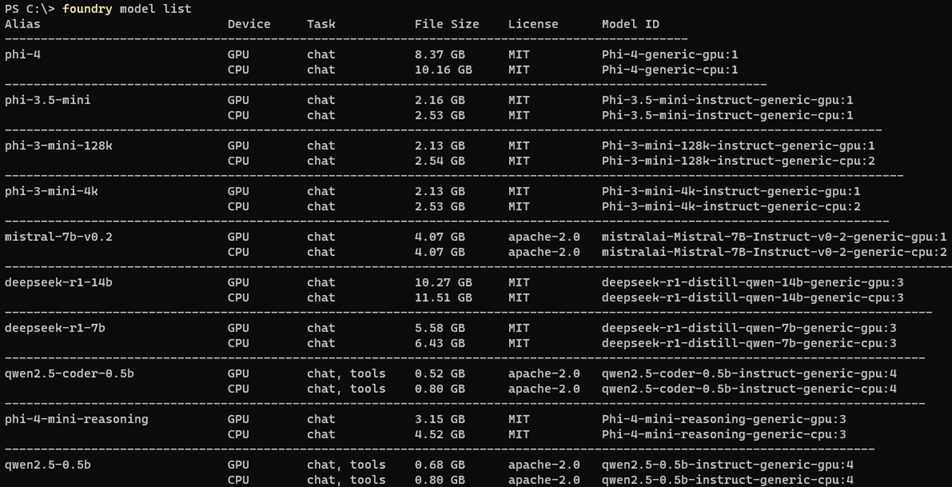 圖5 條列出所有可用的AI模型及相關資訊。
圖5 條列出所有可用的AI模型及相關資訊。
‧Alias:AI模型的別名或簡稱,方便主機使用者辨識與進行呼叫,例如phi-4就是其中一個AI模型的名稱。
‧Device:AI模型運作時所採用的硬體裝置,例如GPU為圖形處理器,或是CPU為中央處理器。GPU適用於高效能平行運算,能夠有效加速大型語言模型的推論效能,而CPU則是在一般小模型和資源有限情況下使用。
‧Task:AI模型的主要用途或工作任務類型,其中chat表示用於自然語言對話,tools表示模型支援額外功能的工具,例如生成程式碼或資料處理等等。此欄位能幫助管理人員快速判斷AI模型的適用情境。
‧File Size:AI模型的檔案大小,通常以GB為單位。檔案大小除了直接影響下載時間以及主機儲存空間之外,大型AI模型雖然功能更強大,但通常也需要更高的資源配置才行。
‧License:AI模型的授權方式,例如MIT或Apache-2.0,不同的授權方式決定模型使用者是否能夠自由修改、散布或是商業化。
‧Model ID:AI模型在系統內部的唯一識別碼,通常用於在系統中精確呼叫該模型,包含模型名稱、版本號碼與裝置類型,這是精準呼叫模型的關鍵,避免因為別名相似而造成混淆。
值得注意的是,有些管理人員對於Model ID欄位表示方式有誤解,舉例來說,「Phi-3-mini-4k-instruct-generic-cpu:2」表示這是該模型用於CPU裝置上的第2個版本,而不是代表運作這個模型需要的CPU核心數,這是最常見的誤解之一。
一般來說,運作AI模型時在模型名稱方面,只要鍵入模型的別名即可,系統會自動為現有的硬體選擇最佳模型。舉例來說,如果硬體配置Nvidia GPU時,Foundry Local會自動選擇最佳的GPU型號運作模型,倘若硬體配置支援NPU,Foundry Local同樣會自動選擇最適合用於NPU的AI模型,所以管理人員通常無須記住完整的模型ID,只要使用名稱較短的別名即可。
除非管理人員想要執行特定的AI模型,才會需要使用完整的模型ID。例如,在具備GPU的硬體裝置主機中,要運作用於CPU的phi-4模型時,便需要鍵入完整的Phi-4-generic-cpu模型ID才行。下列為Foundry Local模型相關指令與說明:
‧foundry model --help:顯示所有可用模型的相關指令及使用方式。
‧foundry model run :運作指定的AI模型,倘若本機尚未快取該模型,則自動下載後運作,管理人員便能開始與AI模型互動。
‧foundry model list:列出所有可用的AI模型,在第一次執行時,系統會自動下載適用於主機硬體的EP執行程式。
‧foundry model list --filter =:過濾後條列出指定的內容,例如依照Alias、Device、Task等等欄位中的關鍵字進行過濾。舉例來說,執行「foundry model list --filter device=CPU」指令,系統便會僅條列出適用於CPU的AI模型。
‧foundry model info :顯示指定模型的詳細資訊。
‧foundry model info --license:顯示模型的授權資訊。
‧foundry model download :下載指定模型至本機快取,但先不運行該模型。
‧foundry model load :將指定的AI模型載入服務中。
‧foundry model unload :從服務中將指定的AI模型卸載。
現在管理人員可以執行「foundry model run」指令,搭配AI模型的別名,例如phi-4-mini,讓系統自動執行下載並且載入AI模型的動作。
當系統載入指定的AI模型後,便會立即運作該AI模型,以本文實作環境來說,phi-4-mini屬於對話型語言模型,並且可以正確理解正體中文,如圖6所示。
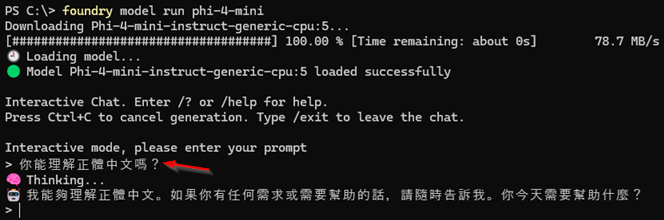 圖6 下載並載入指定的AI模型。
圖6 下載並載入指定的AI模型。
隨著時間不斷推移,Foundry Local支援的AI模型將會越來越多,此時善用過濾參數的用法,便能有效幫助管理人員快速找到要使用的AI模型,並且Foundry Local過濾參數支援多種使用方法。舉例來說,除了指定關鍵字的正向過濾方式之外,也支援使用「!」達到反向過濾的目的,例如執行「foundry model list --filter device=!GPU」指令,能夠過濾並顯示不包含支援GPU硬體裝置的AI模型。
另外,也支援使用「*」萬用字元的方式進行過濾,例如執行「foundry model list --filter alias=phi*」指令,表示過濾後僅顯示AI模型別名開頭為phi的AI模型,如圖7所示。值得注意的是,透過萬用字元方式進行過濾的方法,僅支援別名欄位,其他欄位並不支援。
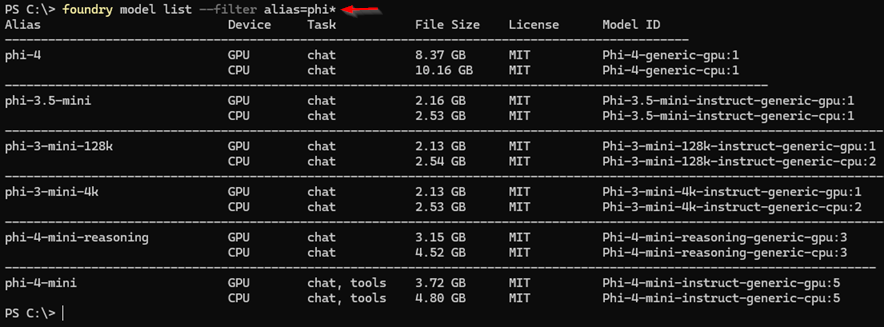 圖7 過濾並顯示別名為phi開頭的AI模型。
圖7 過濾並顯示別名為phi開頭的AI模型。
在微軟官方網站中,Foundry Local模型指令執行時常見的問題之一,就是執行「foundry model list」指令後,若得到「Exception: Request to local service failed. Uri: http://127.0.0.1:0/foundry/list」的錯誤訊息,這個因為Foundry Local服務綁定連接埠的問題,導致無法存取AI模型的情況,官方建議執行「foundry service restart」指令,重新啟動Foundry Local服務,便能有效解決Foundry Local服務綁定連接埠的問題。
管理AI模型快取空間
現在隨著管理人員測試各種AI模型,並且系統不斷自動下載及載入各種AI模型後,除了使用硬體運算資源之外,在儲存空間方面也會因為下載AI模型,而不斷地占用SSD固態硬碟空間。
原則上,當AI模型快取存在於主機時,那麼當主機需要運作該AI模型時,便可以減少下載及載入模型的時間,然而若是該模型不常被使用,甚至測試過後便不再使用的話,那麼便可以刪除該模型的快取空間,以便節省寶貴的SSD固態硬碟空間。
執行「foundry cache list」指令,便能夠條列主機目前已經下載並快取哪些AI模型,接著執行「foundry cache location」指令,即可查詢AI模型預設快取在本機的路徑,倘若執行「foundry cache remove 」指令,便能移除指定的AI模型快取,如圖8所示。下列為Foundry Local快取相關的指令與說明:
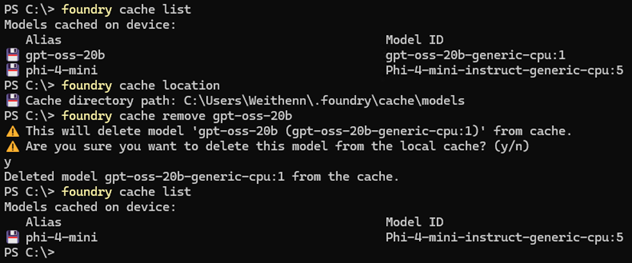 圖8 管理AI模型快取空間。
圖8 管理AI模型快取空間。
‧foundry cache --help:顯示所有可用的相關快取指令及使用方式。
‧foundry cache location:顯示主機目前使用快取路徑。
‧foundry cache list:條列出儲存在本機快取中的所有AI模型。
‧foundry cache cd :將快取路徑變更為其他指定路徑。
‧foundry cache remove :從本機主機快取中移除指定的AI模型。
安裝Open WebUI
此時,部分管理人員可能會覺得,雖然可以運作AI模型,但是在Terminal視窗中互動不太方便,舉例來說,當希望上傳一份檔案讓AI模型進行翻譯或分析,在Terminal視窗中互動不容易達成此需求。
所幸,Foundry Local可以輕鬆地與各種應用進行整合。現在即可將Foundry Local的AI模型,與開源社群最活躍專案之一的Open WebUI進行整合,讓管理人員可以輕鬆透過Open WebUI的友善操作介面,與底層Foundry Local的AI模型進行互動。
稍後會透過Python pip的方式來安裝Open WebUI。但是,在這之前必須先為Windows Server 2025運作環境安裝最新版本Visual C++ Redistributable (x64)才行,如圖9所示,否則稍後啟動Open WebUI服務時,將會遭遇Dyanmic Link Library(DLL)初始化載入的錯誤。安裝完成後便接著執行「winget install Python.Python.3.11」指令,透過winget機制下載及安裝Python。
 圖9 安裝Python之前,必須先安裝最新版本Visual C++ Redistributable(x64)。
圖9 安裝Python之前,必須先安裝最新版本Visual C++ Redistributable(x64)。
當Python安裝作業完成後,接著執行「python.exe -m pip --version」指令,確認目前系統內的Python Pip版本,在本文實作環境中為Pip 24.0版本並非最新版本。執行「python.exe -m pip install --upgrade pip」指令,將系統中Python Pip版本進行更新升級作業,更新版本後為最新的Python Pip 26.0版本,便可以執行「python.exe -m pip install open-webui」指令,透過Python Pip機制安裝Open WebUI軟體套件。
安裝作業完成後,便可執行「open-webui serve」指令,啟動Open WebUI服務。當看到顯示「INFO : Started server process」字樣後,表示Open WebUI服務已經順利啟動。預設情況下,Open WebUI服務會綁定使用連接埠(Port)8080,所以當管理人員啟動Open WebUI服務後,打開瀏覽器連結「http://localhost:8080」,便會看到Open WebUI初始化頁面,鍵入使用者帳號、Email、密碼後按下〔Create Admin Account〕鈕,建立Open WebUI的預設管理人員帳號,如圖10所示。
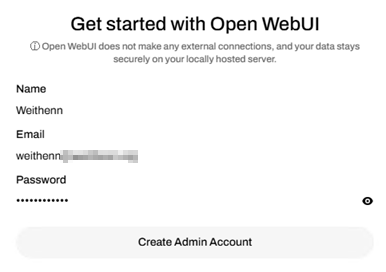 圖10 建立Open WebUI的預設管理人員帳號。
圖10 建立Open WebUI的預設管理人員帳號。
順利登入Open WebUI之後,可以看到畫面是大家熟悉的AI對話視窗,如圖11所示,然而當管理人員嘗試進行對話時,會在右上角出現「Model not selected」錯誤訊息,原因在於,雖然順利安裝完Open WebUI,但是還沒組態設定讓Open WebUI連接到Foundry Local的AI模型所導致。
 圖11 Open WebUI的AI對話視窗。
圖11 Open WebUI的AI對話視窗。
整合Foundry Local AI模型
現在只要組態設定Open WebUI,能夠連接Foundry Local AI模型後,屆時在Open WebUI介面中便可以選擇使用不同的AI模型進行對話。
首先執行「foundry service status」指令,確認Foundry Local服務正常運作中。另外,也可以複製Foundry Local的API Endpoints路徑後在瀏覽器網址列貼上,若有看到API Endpoints資訊(圖12),代表運作正確無誤,確保稍後Open WebUI能夠順利連接。
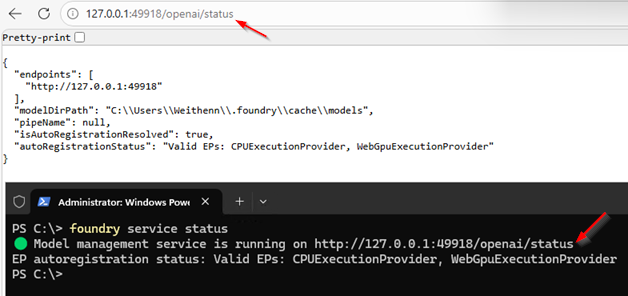 圖12 確認Foundry Local的API Endpoints正常運作中。
圖12 確認Foundry Local的API Endpoints正常運作中。
接著,切換回Open WebUI操作介面,點選右上方帳號圖示,再依序點選「Admin Panel > Settings > Connections」項目,在General區塊內將「Direct Connections」功能項目啟動,系統會顯示Connections settings updated資訊,如圖13所示,然後按下〔Save〕鈕,確認儲存組態設定。
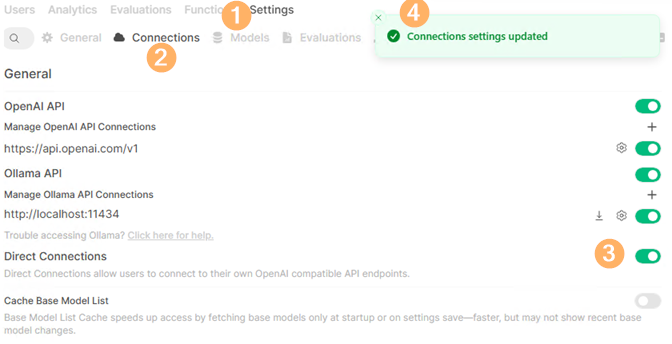 圖13 為Open WebUI啟動Direct Connections功能。
圖13 為Open WebUI啟動Direct Connections功能。
回到Open WebUI操作介面後,再次點選右上方帳號圖示,依序點選「Settings > Connections > Manage Direct Connections」項目,然後按下「+」號圖示。在彈出的Add Connection視窗中,於URL列貼上Foundry Local的API Endpoints路徑,例如「http://127.0.0.1:49918/v1」,接著在下方Auth下拉式選單中,由預設的Bearer調整為None,然後按下〔Save〕鈕儲存組態設定,如圖14所示。
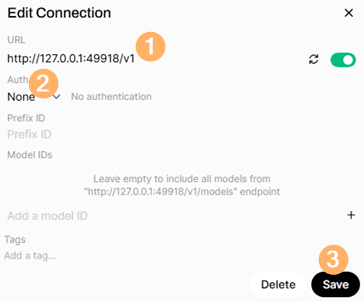 圖14 組態設定Open WebUI連接Foundry Local的API Endpoints路徑。
圖14 組態設定Open WebUI連接Foundry Local的API Endpoints路徑。
值得注意的是,由於本文是在本機進行測試研究,所以連接API Endpoints路徑時,Auth驗證方式才會採用None項目,以便簡化整體組態設定內容。實務上,務必啟用連接API Endpoints路徑Auth驗證機制,減少非預期發生的資安風險。
現在,回到Open WebUI操作介面後,點選左上方的Select a model,便會顯示Foundry Local中已經存在於Foundry Local Cache的AI模型,管理人員便可以在Open WebUI操作介面中選擇個人喜好的AI模型,進行AI模型對話以及後續的互動。
而同時選擇的AI模型,倘若是支援多模態功能,在Open WebUI操作介面中,也能夠輕鬆上傳檔案或透過語音進行交談,如圖15所示。
 圖15 順利整合Foundry Local的AI模型。
圖15 順利整合Foundry Local的AI模型。
<本文作者:王偉任,Microsoft MVP及VMware vExpert。早期主要研究Linux/FreeBSD各項整合應用,目前則專注於Microsoft及VMware虛擬化技術及混合雲運作架構,部落格weithenn.org。>