本文將逐一剖析最新發布vSphere 8 Update 2的各項亮眼特色功能,並說明舊版vCLS叢集服務缺點,該如何刪除舊版vCLS,以及實戰演練最新發布的vCLS撤退機制,讓企業組織的管理人員能夠更輕鬆管理vCLS叢集服務。
最初的vSphere 8版本在2022年10月發布,經過六個月後發布vSphere 8 Update 1版本,最新的vSphere 8 Update 2版本,則是在2023年VMware Explore大會中正式發布,如圖1所示。事實上,管理人員可以察覺,即便VMware每六個月便發布新版本,然而每一版更新並非僅是功能增強或臭蟲更新,反而包含許多新增特色功能。在本文中,將逐一剖析各項亮眼特色功能,並且實戰演練最新發布的vCLS撤退機制,讓企業和組織的管理人員能夠更輕鬆地管理vCLS叢集服務。
 圖1 隨著VMware Explore 2023大會發布的最新vSphere 8 U2版本。 (圖片來源:vSphere 8 U2 Now Available - VMware vSphere Blog)
圖1 隨著VMware Explore 2023大會發布的最新vSphere 8 U2版本。 (圖片來源:vSphere 8 U2 Now Available - VMware vSphere Blog)
vSphere 8 U2亮眼功能介紹
接著,分別詳細說明vSphere 8 U2所提供的諸多亮眼功能。
減少新版升級停機時間
在VMware運作架構中,許多特色功能或進階功能都圍繞在vCenter Server管理平台中。然而,只要是軟體產物便需要進行安全性更新、臭蟲修補、版本升級等等,一旦vCenter執行安全性更新、臭蟲修補、版本升級等工作任務時,便會處於離線狀態從而產生「停機時間」(Downtime)。
雖然vCenter管理平台產生停機時間時,對於上層的虛擬主機(VM)或容器等工作負載,並不會造成營運服務中斷或無法運作的情況,但此時因為vCenter處於離線狀態,而無法執行許多進階功能。
因此,在最新vSphere 8 U2版本中,將vSphere+雲端環境的vCenter更新機制,如圖2所示,下放到地端vCenter管理平台中,以便減少vCenter因為更新而造成的停機時間,那麼vSphere+雲端和原有地端環境更新機制有什麼不同之處呢?
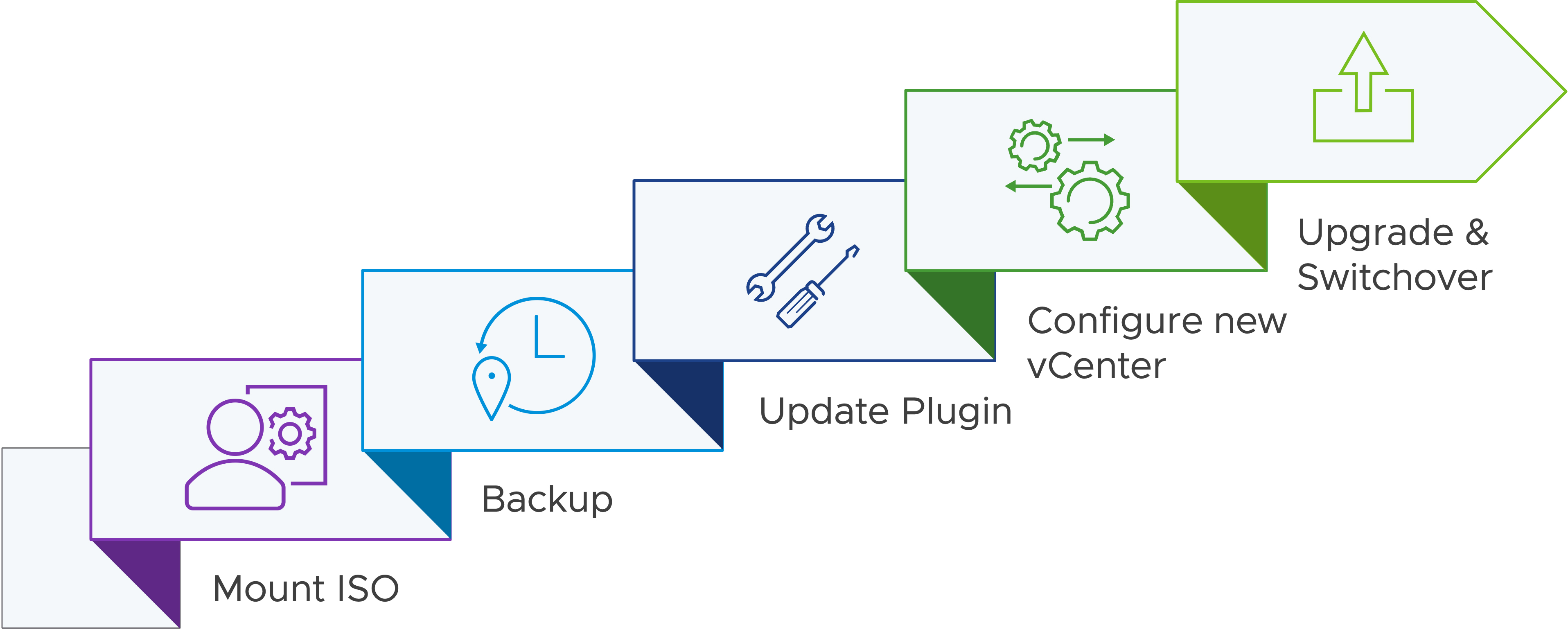 圖2 vSphere+雲端環境的vCenter更新機制流程示意圖。 (圖片來源:What's New in vSphere 8 U2? | Reduced Downtime Upgrade | VMware)
圖2 vSphere+雲端環境的vCenter更新機制流程示意圖。 (圖片來源:What's New in vSphere 8 U2? | Reduced Downtime Upgrade | VMware)
簡單來說,vSphere+更新機制的重點為「遷移」(Migration-Base),在更新動作執行時,先部署新的vCenter,並將原有vCenter的資料和組態設定配置,複製到新部署的vCenter當中,其實這樣的機制類似於地端vCenter跨大版本升級作業。
然而,這之間的主要差別在於,新舊vCenter資料和組態設定複製階段期間,原有vCenter的所有服務仍正常運作,管理人員仍能透過vCenter執行相關進階特色功能並管理虛擬化基礎架構,整個流程中唯一會發生vCenter停機的時間點,就是資料和組態設定複製階段完成後,原有vCenter停止服務,由新部署的vCenter接手並啟動服務,原則上通常在五分鐘之內完成,這與過往地端vCenter的停機時間相比大量減少許多。
新式更新機制共有如下五個步驟,並且管理人員也可以在實際更新期間,查看工作任務的執行進度,如圖3所示:
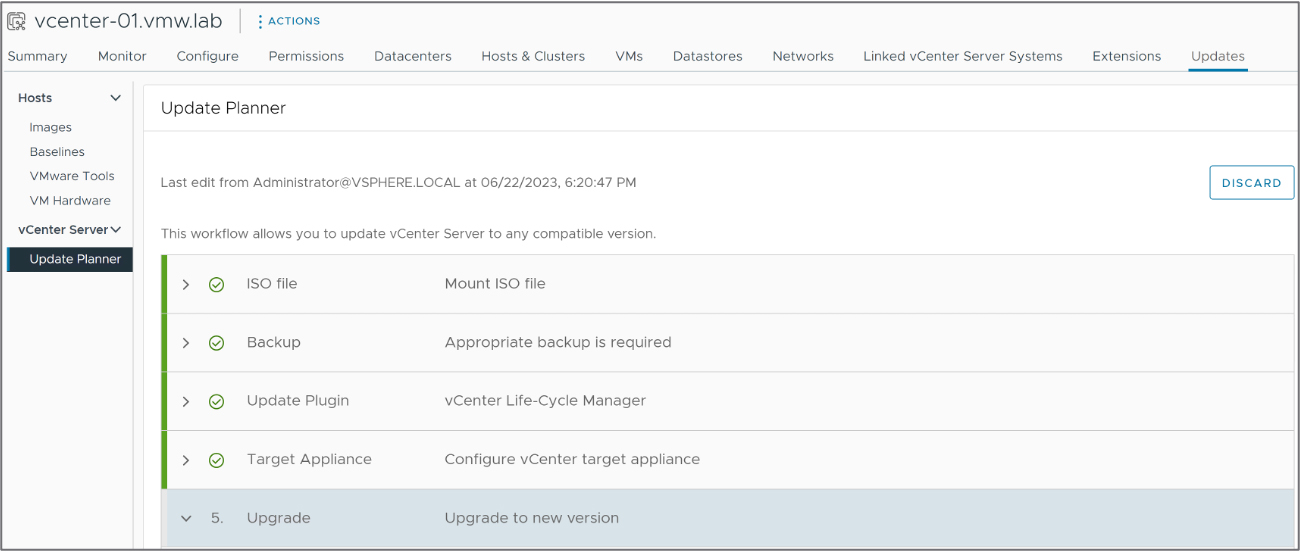 圖3 新式vCenter更新機制操作畫面示意圖。 (圖片來源:What's New in vSphere 8 U2? | Reduced Downtime Upgrade | VMware)
圖3 新式vCenter更新機制操作畫面示意圖。 (圖片來源:What's New in vSphere 8 U2? | Reduced Downtime Upgrade | VMware)
1. 掛載ISO映像檔:將準備部署新版本的vCenter ISO映像檔進行掛載。值得注意的是,這個ISO映像檔是完整的安裝ISO映像檔,而非安全性更新或修補臭蟲的ISO映像檔。
2. 檢查備份:系統將檢查和確認原有運作中的vCenter管理平台,是否已經執行備份工作任務。
3. 更新外掛程式:系統將在原有vCenter管理平台中更新vCenter生命週期服務,以便後續部署新的vCenter管理平台,這也是更新機制對於原有vCenter的唯一變更。
4. 組態設定新的vCenter:針對新部署的vCenter進行組態設定,包括虛擬主機名稱、臨時的root管理帳號密碼、臨時的vNetwork虛擬網路設定等等,可以選擇繼承原有vCenter組態設定,也可以選擇自行組態設定。預設情況下,新部署的vCenter將會繼承原有vCenter的root管理帳號密碼和網路身分驗證。
5. 升級與執行切換:一旦新部署的vCenter複製和組態設定完畢,並且兩台vCenter都保持正常運作狀態時,管理人員便能決定何時執行切換作業,原則上可以立即執行切換vCenter的工作任務,也可以排程設定一天後或一週後。值得注意的是,切換期間原有vCenter停止服務,新部署的vCenter接手並啟動服務,通常還是未產生五分鐘之內的停機時間。
可靠的網路組態設定復原機制
無論企業組織針對VMware虛擬化基礎架構部署多少高可用性機制,在面對意外的災難事件時,仍有可能需要最後一道防線「備份∕還原」。然而,執行備份作業時,通常也僅是針對當時的資料和組態設定進行備份,但是備份作業完成後,仍然會有其中工作任務執行,例如新增∕修改∕刪除虛擬主機、新增∕修改∕刪除vNetwork虛擬網路等等。
因此,雖然管理人員在遭遇意外災難事件後,選擇最接近的備份時間點進行還原後,仍然需要處理這些備份後至災難發生期間的組態設定值。舉例來說,備份作業完成後,新增∕修改∕刪除vNetwork虛擬網路,還原後則仍需要手動處理這些vNetwork的異動作業。
而最新vSphere 8 U2版本中,將「分散式鍵值儲存」(Distributed Key-Value Store)機制擴充,包含vSphere和NSX中的vDS分散式虛擬網路交換器組態設定。因此,當災難發生並執行還原作業後,在vSphere叢集中ESXi主機的最新vDS分散式虛擬網路交換器組態設定資訊,將會自動被推送到還原後的vCenter資料庫內,如圖4所示,所以便無須於還原作業後,手動更新vDS分散式虛擬網路交換器組態設定。
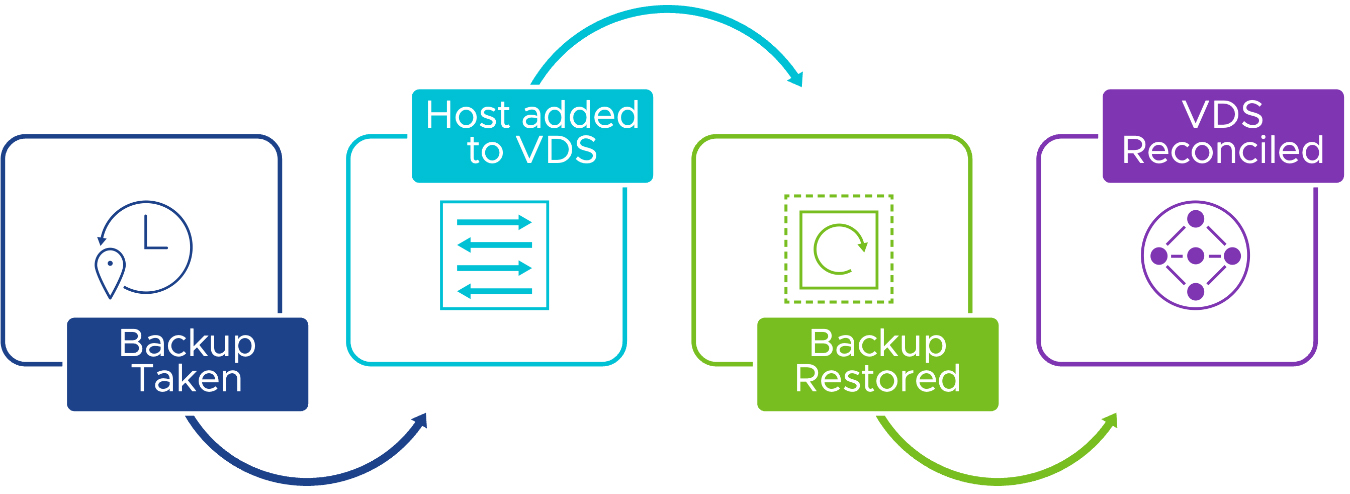 圖4 vCenter可靠網路組態設定復原機制運作流程示意圖。 (圖片來源:What's New in vSphere 8 U2? | Reliable Network Configuration Recovery | VMware)
圖4 vCenter可靠網路組態設定復原機制運作流程示意圖。 (圖片來源:What's New in vSphere 8 U2? | Reliable Network Configuration Recovery | VMware)
最佳化放置GPU工作負載
企業和組織為了因應這波AI浪潮,紛紛在虛擬化環境中部署vGPU環境,以便加快機器學習(ML)和大型語言模型(LLM)的訓練和調校。雖然在透過vGPU機制時,可以有效將2、4、8個vGPU圖形運算資源,分配給虛擬主機使用,甚至最新vSphere 8 U2版本,可以支援最大指派16個vGPU圖形運算資源給虛擬主機,以便最大化使用GPU資源並縮短AI模型的訓練和調校時間。
然而,和過往虛擬主機會碰到的資源碎片問題相同,環境中配置不同資源大小的vGPU虛擬主機時,這種情況便更容易發生,一旦發生資源碎片的問題時,便可能造成雖然整體vSphere叢集還有足夠的vGPU資源,但新部署的vGPU虛擬主機卻無法使用並順利啟動。
舉例來說,運作環境中有三台ESXi虛擬化平台,每台ESXi共有四個實體GPU圖形運算資源,並且每台ESXi虛擬化平台上,已經分別運作一台配置2 vGPU虛擬主機。此時,新的專案需要一台配置4 vGPU虛擬主機,雖然整體vSphere叢集仍有6 vGPU圖形運算資源,但是並沒有任何一台ESXi虛擬化平台擁有足夠運作一台4 vGPU虛擬主機的圖形運算資源,如圖5所示。此時,這台新增部署的4 vGPU虛擬主機,便會處於等待放置狀態且無法開機運作。
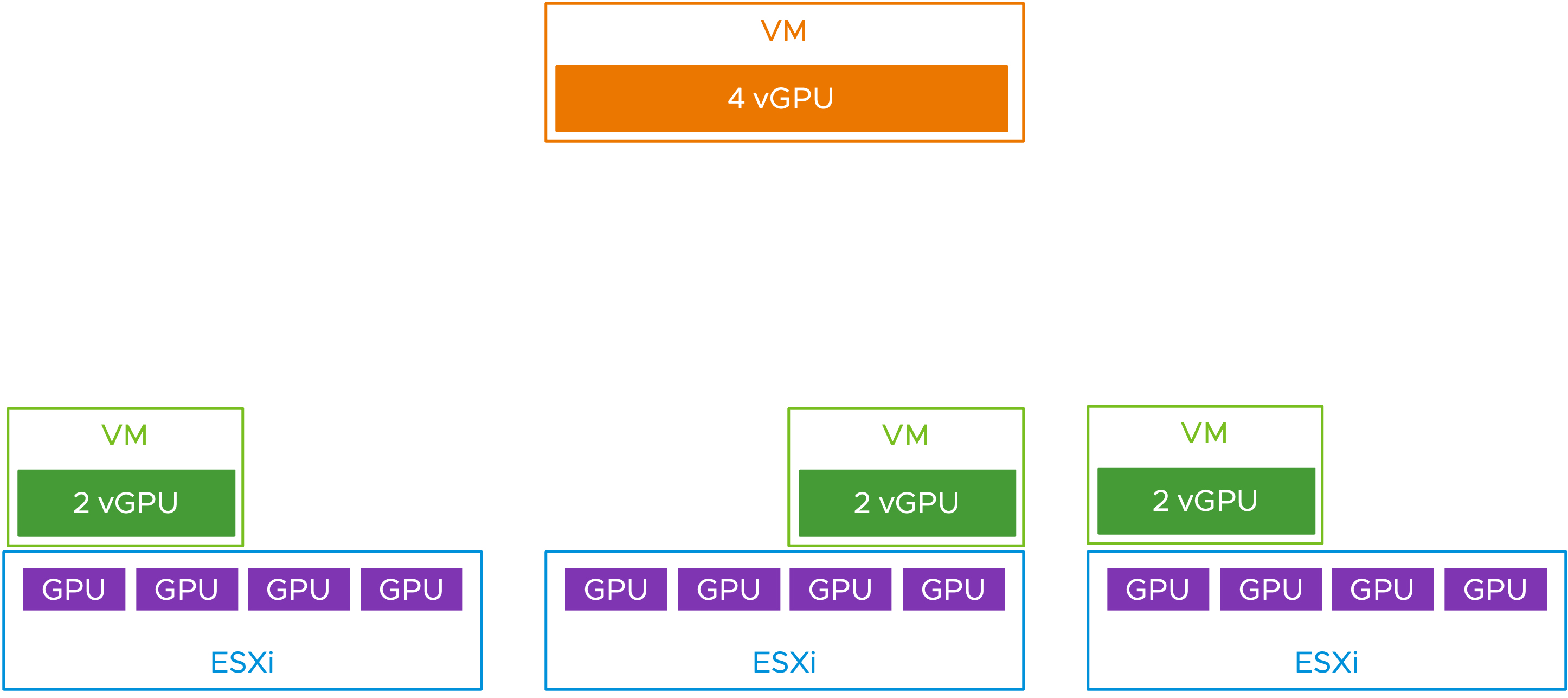 圖5 實體GPU圖形運算資源碎片問題示意圖。 (圖片來源:Improving VM Placement to Servers to Optimize Your GPU Usage in VMware vSphere 8 U2 | VMware)
圖5 實體GPU圖形運算資源碎片問題示意圖。 (圖片來源:Improving VM Placement to Servers to Optimize Your GPU Usage in VMware vSphere 8 U2 | VMware)
因此,在新版vSphere 8 U2版本中新增GPU最佳化放置機制,以便解決實體GPU圖形運算資源碎片問題。舉例來說,上述GPU資源碎片問題發生時,只需要組態設定vSphere叢集中新增「VgpuVmConsolidation = 1」進階功能參數,系統便會將vGPU資源大小相同的虛擬主機遷移到同一台ESXi虛擬化平台上,同時搭配「LBMaxVmotion = 1」進階功能參數,還可以避免ESXi虛擬化平台觸發執行多次vGPU虛擬主機vMotion遷移事件。更多最佳化放置vGPU圖形運算資源,進階功能參數的詳細資訊,請參考VMware KB88271、KB66813知識庫文章。
一旦將上述二項進階功能參數組態設定至vSphere叢集,系統便會遷移組態設定2 vGPU虛擬主機到同一台ESXi虛擬平台上,從而空出完整支援4 vGPU虛擬主機的資源,讓新增部署的4 vGPU虛擬主機能夠成功放置並順利開機運作,如圖6所示,以便充分利用vSphere叢集中的GPU圖形運算資源。
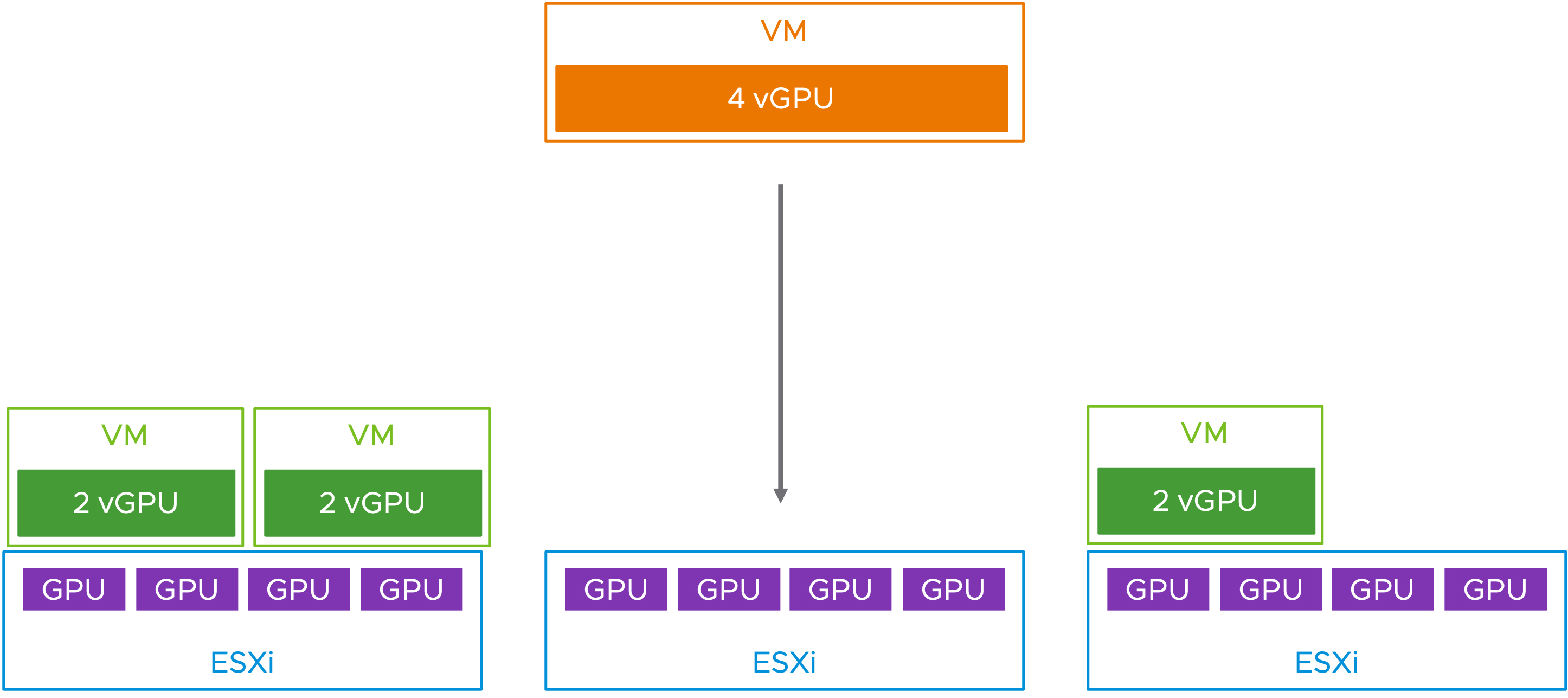 圖6 最佳化放置vGPU圖形運算資源示意圖。 (圖片來源:Improving VM Placement to Servers to Optimize Your GPU Usage in VMware vSphere 8 U2 | VMware)
圖6 最佳化放置vGPU圖形運算資源示意圖。 (圖片來源:Improving VM Placement to Servers to Optimize Your GPU Usage in VMware vSphere 8 U2 | VMware)
虛擬主機最新虛擬硬體版本v21
在每一版的虛擬主機虛擬硬體版本中,除了擴充原有支援限制外,也同步新增支援各種硬體,以便因應各種現代化工作負載。在最新vSphere 8 U2版本中,開始支援最新VM虛擬硬體版本v21,如圖7所示。
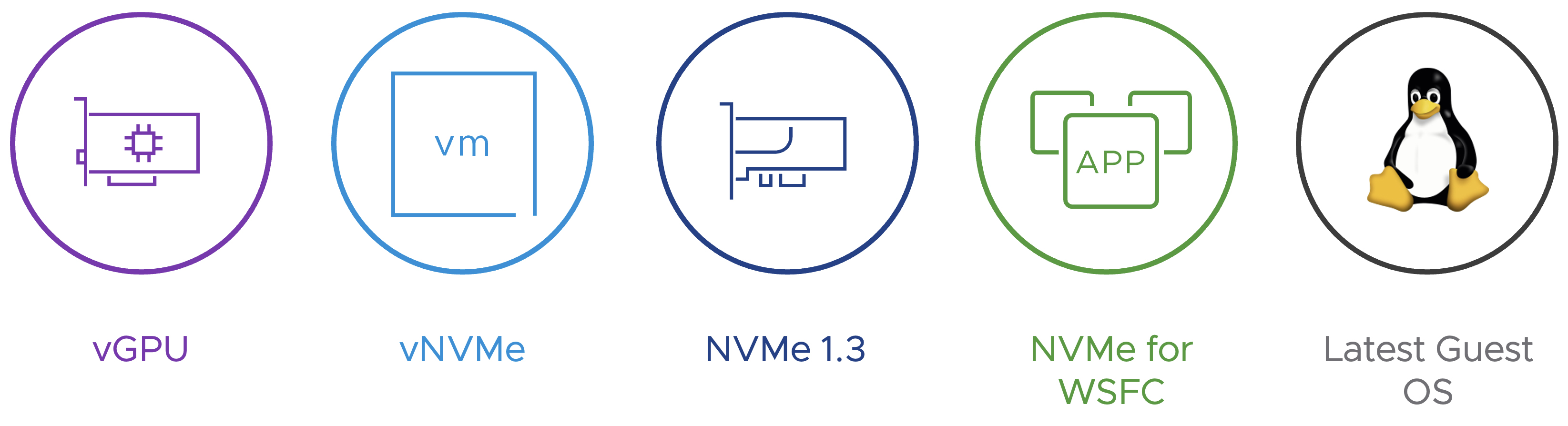 圖7 最新VM虛擬硬體版本v21增強或新增功能示意圖。 (圖片來源:What's New in vSphere 8 U2? | More Vroooom for your VM with Hardware Version 21 | VMware)
圖7 最新VM虛擬硬體版本v21增強或新增功能示意圖。 (圖片來源:What's New in vSphere 8 U2? | More Vroooom for your VM with Hardware Version 21 | VMware)
在最新VM虛擬硬體v21版本中,增強或新增支援虛擬主機虛擬硬體項目如下:
‧每台虛擬主機,支援組態設定最多使用16 vGPU圖形運算資源。
‧每台虛擬主機,支援組態設定最多4個vNVMe儲存控制器,每個vNVMe儲存控制器支援掛載64個vNVMe儲存裝置,總共支援掛載256個vNVMe儲存裝置。
‧針對Windows 11和Windows Server 2022客體作業系統,新增支援NVMe 1.3。
‧在WSFC容錯移轉叢集運作架構中,新增支援NVMe儲存裝置。
‧支援安裝最新的RHEL 10、Oracle Linux 10、Debian 13以及FreeBSD 15的客體作業系統。
VM服務正式支援Windows虛擬主機
在前一版vSphere 8 U1版本中,新增支援「VM服務」(VM Service)機制,並支援從內容庫部署自訂的Linux虛擬主機。
最新vSphere 8 U2版本中,VM服務正式支援Windows虛擬主機,如圖8所示。因此管理人員或開發人員可以透過kubectl指令部署Windows虛擬主機到命名空間,並且搭配標準的SysPrep格式的自定義檔案,客製化企業和組織需要的Windows虛擬主機運作環境。
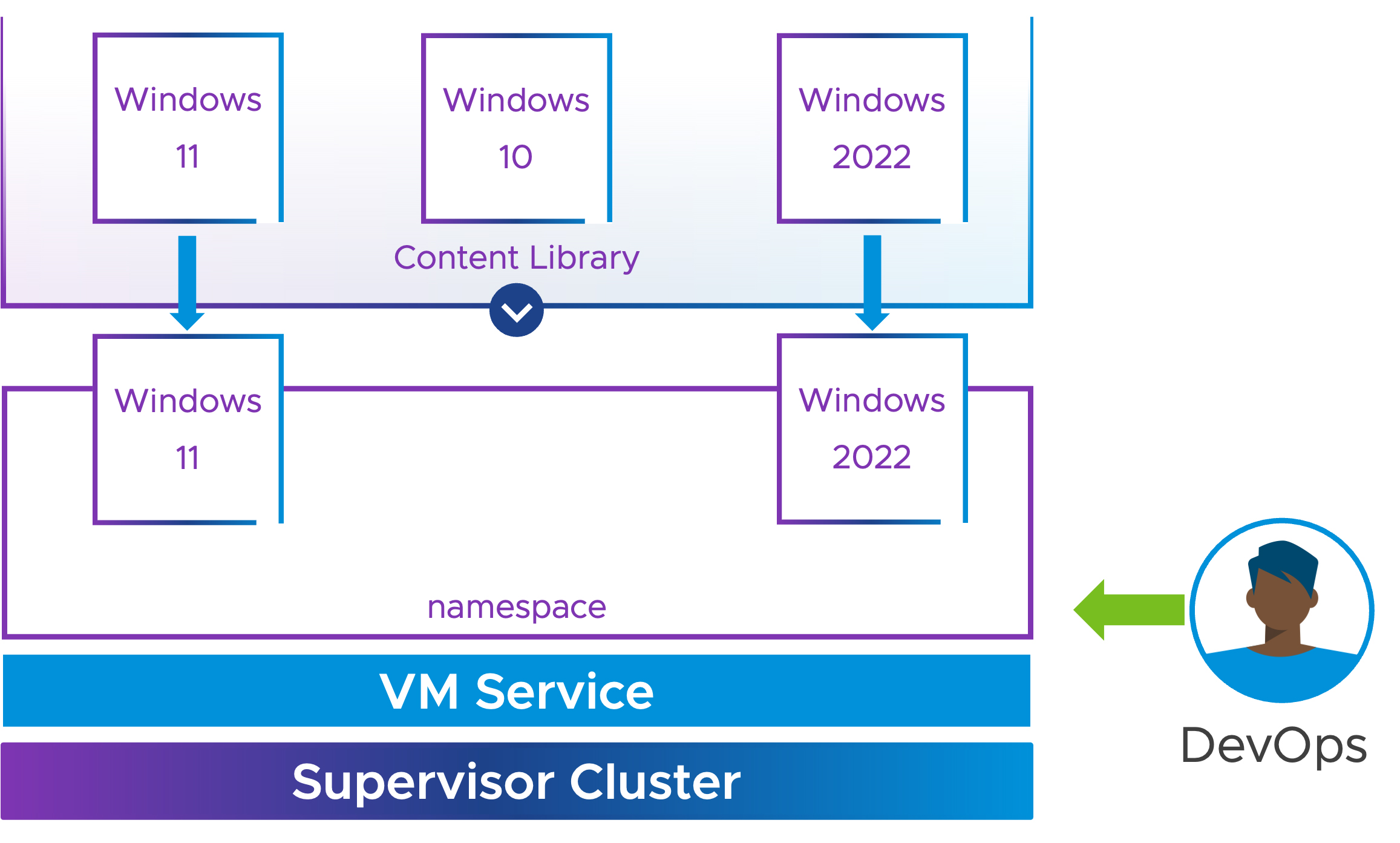 圖8 VM服務正式支援Windows虛擬主機運作示意圖。 (圖片來源:What's New in vSphere 8 U2? | Windows VM Support for VM Service | VMware)
圖8 VM服務正式支援Windows虛擬主機運作示意圖。 (圖片來源:What's New in vSphere 8 U2? | Windows VM Support for VM Service | VMware)
NSX ALB負載平衡機制成為主流 事實上,VMware官方宣布從NSX-T Data Center 3.2.0版本開始,過往的NSX-T LB(Load Balancer)負載平衡機制將被棄用,並且在後續的新版本將其完全從內建清單中刪除。
所以,從NSX 4.x版本開始,或vSphere with Tanzu中的Supervisor Cluster運作環境,都建議使用NSX ALB(Advanced Load Balancer)負載平衡機制,取代過往且已經棄用的NSX-T LB負載平衡機制,如圖9所示,以便更容易整合及維護管理vSphere vDS分散式虛擬網路交換器和網路堆疊。
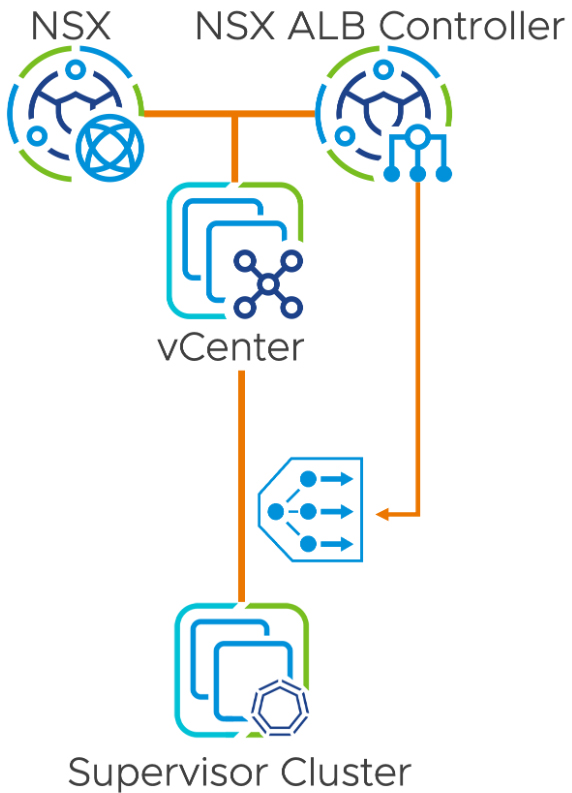 圖9 NSX ALB(Advanced Load Balancer)負載平衡機制運作示意圖。 (圖片來源:What's New in vSphere 8 U2? | Expanding NSX Advanced Load Balancer Support | VMware)
圖9 NSX ALB(Advanced Load Balancer)負載平衡機制運作示意圖。 (圖片來源:What's New in vSphere 8 U2? | Expanding NSX Advanced Load Balancer Support | VMware)
實戰演練vCLS叢集服務撤退模式
在過去vSphere 7 U1版本中,VMware官方正式發布vCLS(vSphere Clustering Services)特色功能,為原本的vSphere叢集服務新增建立「分佈式控制平面」(Distributed Control Plane)的第一個版本,以便將vSphere叢集服務和vCenter進行脫勾,如圖10所示。
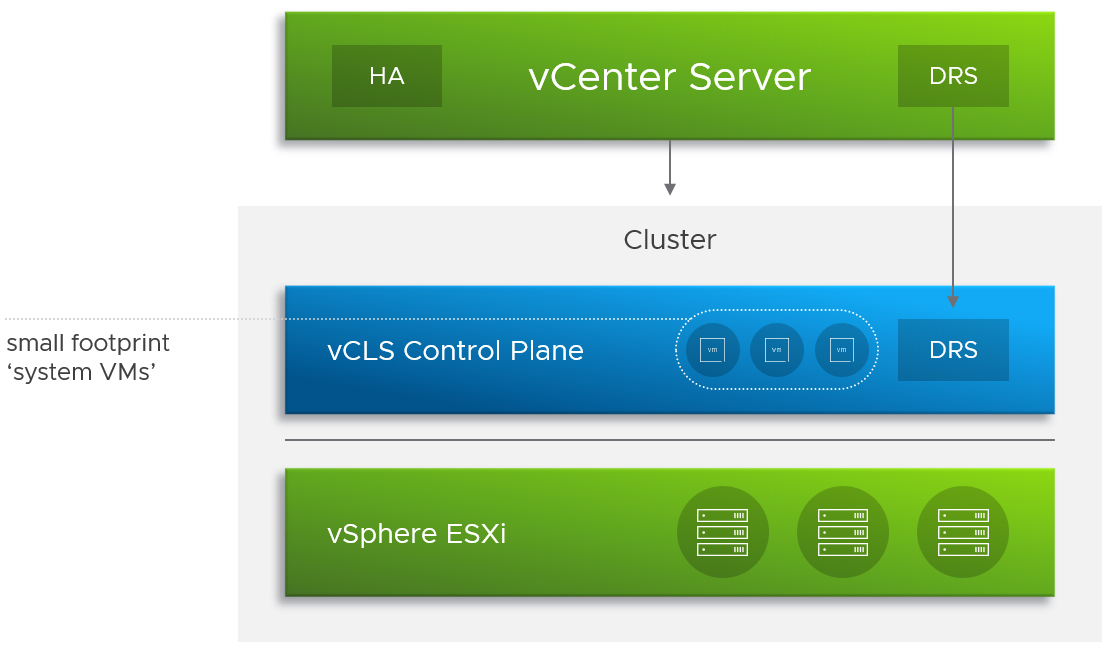 圖10 vCLS叢集服務運作架構示意圖。 (圖片來源:vSphere 7 U1 – vSphere Clustering Service(vCLS)– VMware vSphere Blog)
圖10 vCLS叢集服務運作架構示意圖。 (圖片來源:vSphere 7 U1 – vSphere Clustering Service(vCLS)– VMware vSphere Blog)
在vSphere基礎架構中,一旦vCenter管理平台發生災難事件時,上層運作的虛擬主機和容器等工作負載,雖然不會受到任何影響並持續正式運作,但是管理人員也將因為vCenter的損壞,而無法對虛擬主機和容器等工作負載進行任何的管理任務。
然而,在vCenter管理平台尚未恢復期間,雖然vSphere HA(High Availability)高可用性仍然能夠正常運作,但是vSphere vMotion線上遷移機制或自動化遷移機制的vSphere DRS(Distributed Resource Scheduler)等等其他機制,都將因為vCenter故障而無法運作。
這就是為什麼VMware官方推出vCLS叢集服務,讓vSphere叢集服務與vCenter脫勾,一旦vCLS叢集服務部署完成並正確運作後,當vCenter發生災難事件時,因為vCLS叢集服務會在vSphere叢集中建立一至三台的vCLS虛擬主機,所以即便有部分vCLS虛擬主機受到影響,仍然能夠在vCenter尚未恢復時,讓自動化遷移vSphere DRS等進階功能繼續運作,詳細資訊可參考VMware KB80472知識庫文章。
接下來,將實戰演練舊版vSphere 7 U3手動執行「vCLS撤退模式」(vCLS Retreat Mode),以及在最新vSphere 8 U2版本中新增圖形介面輕鬆操作vCLS撤退模式特色功能。
舊版vCLS叢集服務缺點
原則上,vCLS叢集服務會讓原有vSphere叢集服務更穩定,並且與自動化遷移機制vSphere DRS互相協作配合。然而,有時可能因為某些因素或臭蟲,導致自動化遷移機制vSphere DRS無法正常運作。舉例來說,即便管理人員啟用vSphere DRS,但可能發現vSphere DRS並沒有正常運作,不會自動化將虛擬主機遷移至其他工作負載低的ESXi虛擬化平台。
此外,也因為自動化遷移機制vSphere DRS無法正常運作,所以當災難事件發生觸發vSphere HA時,也將因為vSphere DRS最佳工作負載放置機制失效,雖然vSphere HA能夠順利把受影響的虛擬主機,重新在其他存活的ESXi虛擬化平台上開機,但是可能會產生工作負載放置極度不平均的狀態,詳細資訊請參考VMware KB91891、KB79892知識庫文章。
如何刪除舊版vCLS
由於在舊版vCLS叢集服務運作環境中,預設所有的vCLS虛擬主機是由「vSphere叢集服務」(vSphere Cluster Service)所管理,因此當嘗試干預vCLS虛擬主機時,系統會跳出警告資訊,說明無須管理人員介入,而是由vSphere叢集服務自動管理vCLS虛擬主機,如圖11所示。
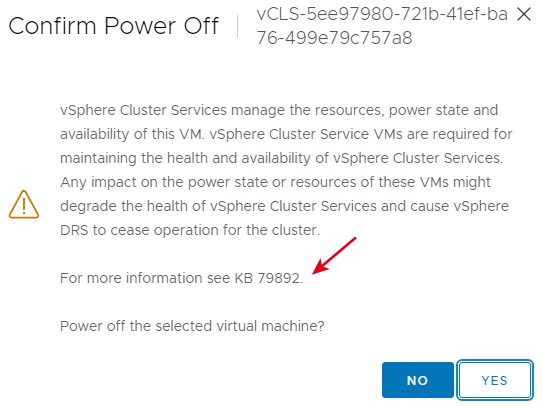 圖11 舊版的vCLS叢集服務,管理人員無法管理vCLS虛擬主機。
圖11 舊版的vCLS叢集服務,管理人員無法管理vCLS虛擬主機。
然而,一旦發生vCLS叢集服務在運作上有臭蟲的情況發生,此時由於無法介入管理vCLS虛擬主機,所以便會無法徹底執行,將vCLS虛擬主機刪除後重新部署的動作,以便嘗試修復vCLS叢集服務臭蟲的情況。
此時,可以嘗試手動組態設定vCenter管理平台,將所有納管的vSphere Cluster都進入「撤退模式」(Retreat Mode),達到刪除所有vSphere Cluster內的vCLS虛擬主機的目的,然後再重新部署vSphere Cluster內的vCLS虛擬主機。

在刪除vCLS虛擬主機之前,先確認目前vCLS虛擬主機的情況,依序點選「VMs and Templates > vCLS > VMs」項目,即可看到目前vSphere Cluster內vCLS虛擬主機資訊,如圖12所示。
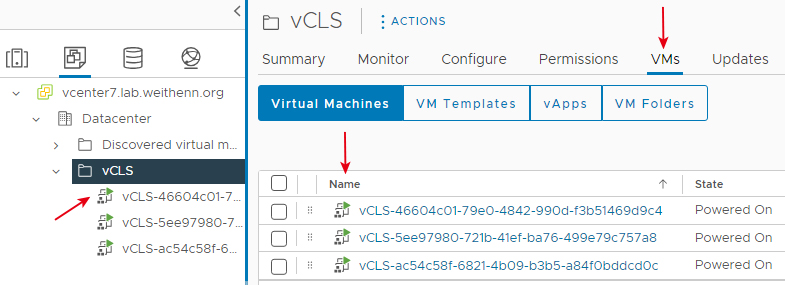 圖12 目前vSphere Cluster內的vCLS虛擬主機資訊。
圖12 目前vSphere Cluster內的vCLS虛擬主機資訊。
在vCenter管理介面中,點選希望刪除vCLS虛擬主機的vSphere Cluster後,查看URL內中間關鍵字「domain-c + <數字>」,舉例來說,本文實作環境為「domain-c8」,如圖13所示。值得注意的是,這個數值必須正確,假設稍後組態設定撤退模式時填錯數值,將會造成vpxd服務啟動失敗。
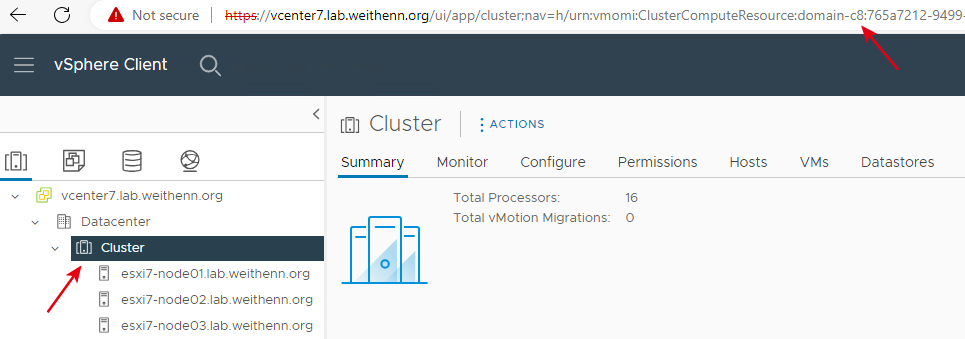 圖13 確認要刪除vCLS虛擬主機所在的vSphere Cluster。
圖13 確認要刪除vCLS虛擬主機所在的vSphere Cluster。
複製完成後,依序點選「vCenter > Configure > Settings > Advanced settings > Edit Settings」項目,在彈出的組態設定視窗中,移至視窗最底部,在Name欄位中填入「config.vcls.clusters.domain-c8.enabled」,並在Value欄位填入「False」,然後按下〔Add〕按鈕新增組態設定,最後按下〔Save〕按鈕套用生效。
原則上,在30秒之內系統便會自動執行刪除作業,可以在vCenter管理介面中,看到系統自動執行「Initiate guest OS shutdown」和「Delete virtual machine」的刪除工作任務,完成後可以看到在vSphere Cluster內,所有的vCLS虛擬主機已經刪除完畢,如圖14所示。
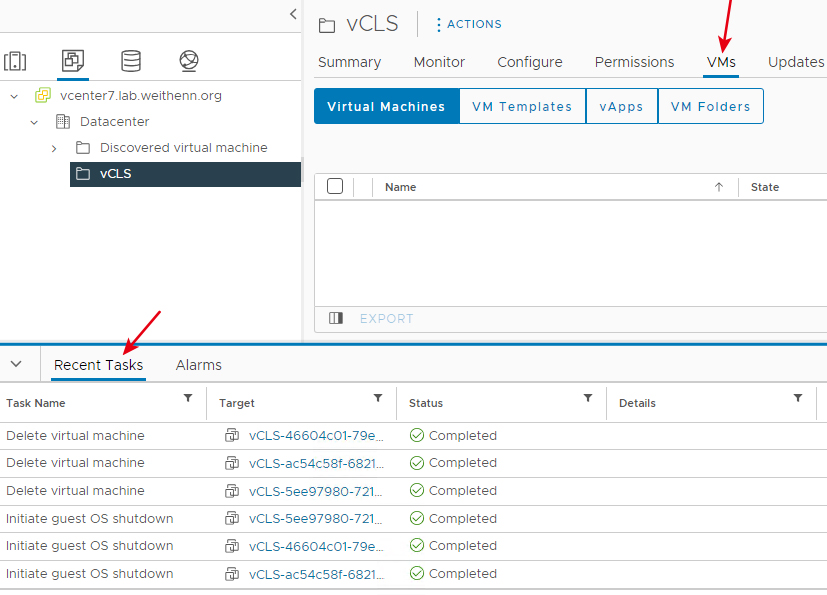 圖14 系統自動刪除vSphere Cluster內所有vCLS虛擬主機。
圖14 系統自動刪除vSphere Cluster內所有vCLS虛擬主機。
接著,便可以回到剛才的組態設定視窗,點選Name頁籤中的過濾關鍵字圖示,輸入「vcls」關鍵字後,即可找到剛才新增的組態設定值,將剛才新增的組態設定值中Value欄位,由原本的False修改為「True」後,如圖15所示,按下〔Save〕按鈕套用生效。
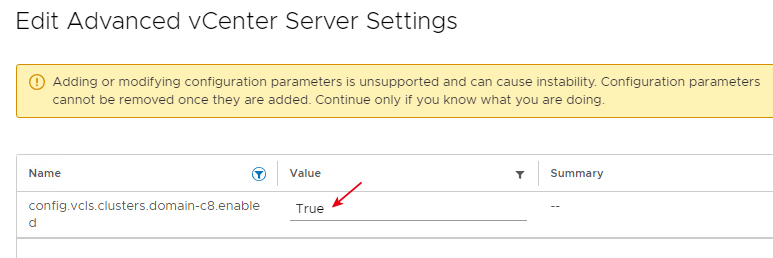 圖15 修改Value組態設定值重新部署vCLS虛擬主機。
圖15 修改Value組態設定值重新部署vCLS虛擬主機。
同樣地,在30秒之內系統便會自動執行重新部署作業,可以在vCenter管理介面中,看到系統自動執行「Deploy OVF template > Reconfigure virtual machine > Initialize powering on > Power On virtual machine」等工作任務,重新部署vSphere Cluster內所有vCLS虛擬主機,如圖16所示。
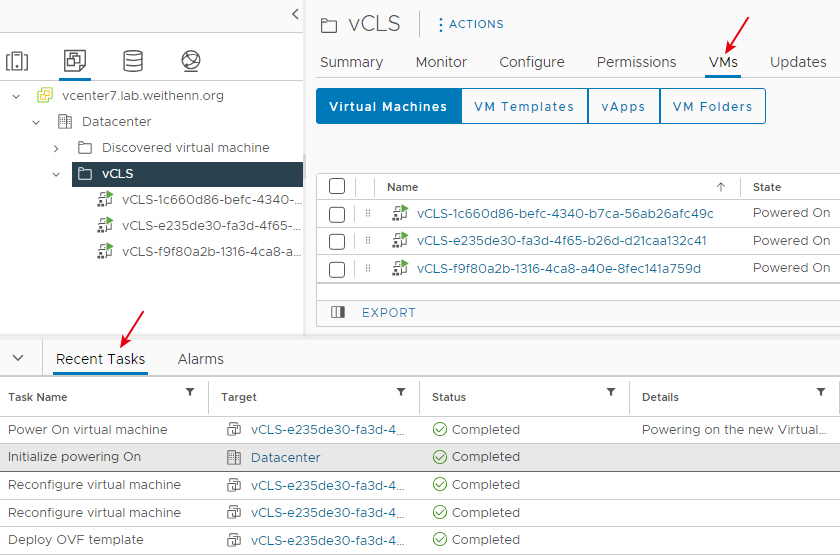 圖16 系統自動重新部署vSphere Cluster內所有vCLS虛擬主機。
圖16 系統自動重新部署vSphere Cluster內所有vCLS虛擬主機。
新版直接支援vCLS撤退模式
原則上,只要是採用vSphere 8.0 U2之前的版本,即便是前一版的vSphere 8.0 U1,都只能使用上述方法組態設定,刪除和重新部署vCLS虛擬主機。而在最新vSphere 8.0 U2版本中,如圖17所示,直接支援組態設定vSphere Cluster進入撤退模式。
 圖17 最新的vSphere 8 U2版本,直接支援vSphere Cluster撤退模式。
圖17 最新的vSphere 8 U2版本,直接支援vSphere Cluster撤退模式。
新版重新部署vCLS虛擬主機
在最新vSphere 8.0 U2版本中,當同樣出現vCLS虛擬主機運作異常或臭蟲的情況時,可以透過vCenter管理介面,直接為所屬的vSphere Cluster組態設定vCLS撤退模式。
同樣地,在刪除vCLS虛擬主機之前,確認目前vCLS虛擬主機的情況,依序點選「VMs and Templates > vCLS > VMs」項目,即可看到目前vSphere Cluster內vCLS虛擬主機資訊,如圖18所示。
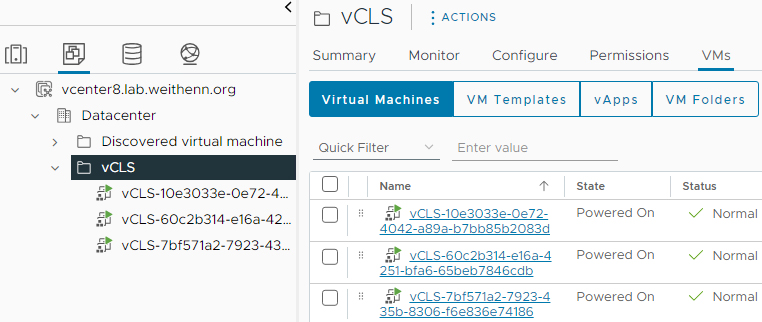 圖18 目前vSphere 8 U2 Cluster內vCLS虛擬主機資訊。
圖18 目前vSphere 8 U2 Cluster內vCLS虛擬主機資訊。
在vCenter管理介面中,依序點選「Cluster > Configure > vSphere Cluster Services > General > vCLS Mode > Edit vCLS Mode」項目,在彈出視窗中可以看到,預設情況下系統採用「System Managed」系統管理模式。
當管理人員希望刪除vCLS虛擬主機時,選擇至「Retreat Mode」撤退模式,系統將出現警告訊息再次提醒管理人員應該在vCLS機制運作異常時才組態設定採用撤退模式,確認後按下〔OK〕按鈕套用生效,如圖19所示。
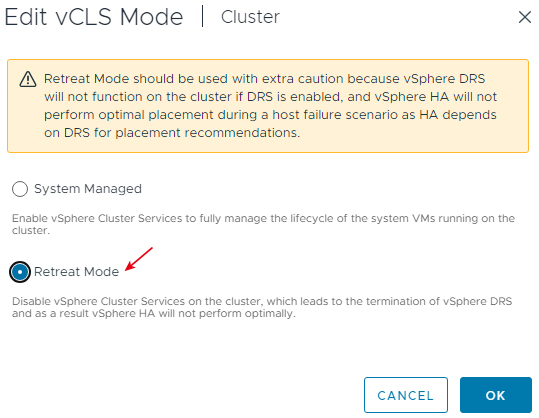 圖19 選擇Retreat Mode撤退模式準備刪除vCLS虛擬主機。
圖19 選擇Retreat Mode撤退模式準備刪除vCLS虛擬主機。
組態設定套用生效後,系統立即執行自動刪除作業,可以在vCenter管理介面中看到系統自動執行「Reconfigure cluster」、「Initiate guest OS shutdown」以及「Delete virtual machine」的刪除工作任務,完成後可以在vSphere Cluster內看到所有vCLS虛擬主機已經刪除完畢,如圖20所示。
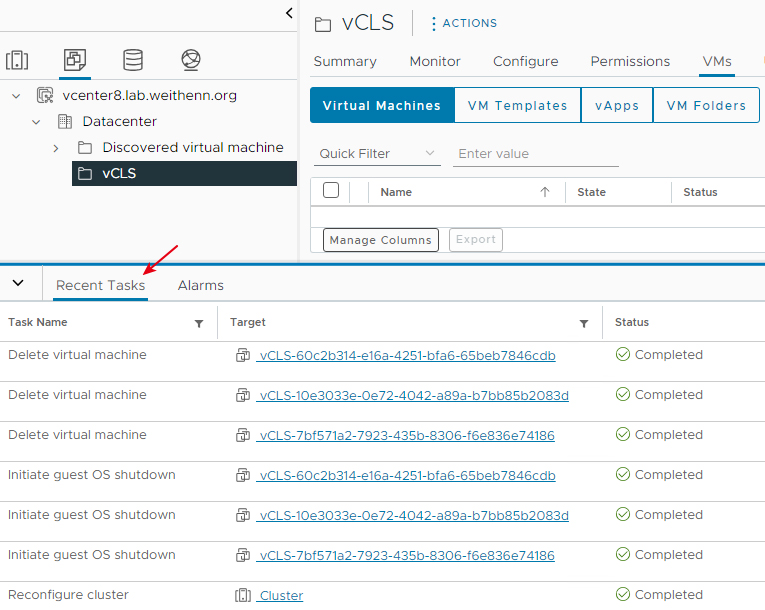 圖20 系統自動刪除vSphere Cluster內所有vCLS虛擬主機。
圖20 系統自動刪除vSphere Cluster內所有vCLS虛擬主機。
回到剛才vCLS模式組態設定視窗,改為選擇「System Managed」系統管理模式後,按下〔OK〕按鈕套用生效。
同樣地,系統立即自動執行重新部署作業,可以在vCenter管理介面中,看到系統自動執行「Reconfigure cluster > Deploy OVF template > Reconfigure virtual machine > Initialize powering on > Power On virtual machine」等工作任務,重新部署vSphere Cluster內所有vCLS虛擬主機,如圖21所示。
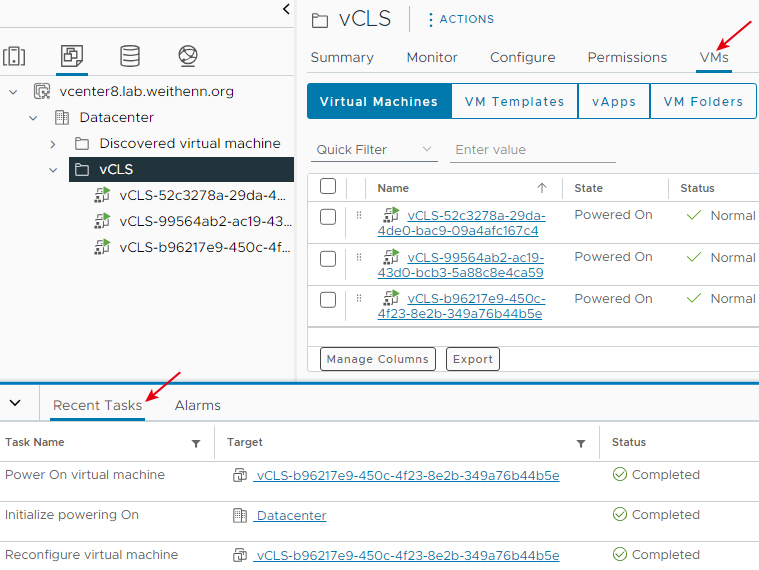 圖21 系統自動重新部署vSphere Cluster內所有vCLS虛擬主機。
圖21 系統自動重新部署vSphere Cluster內所有vCLS虛擬主機。
結語
透過本文的深入剖析和實作演練後,除了理解最新vSphere 8 U2版本的亮眼技術之外,也實作演練舊版vSphere 7,以及新版vSphere 8 U2的vCLS虛擬主機管理作業,讓企業和組織的vSphere叢集能夠更穩定,不受vCenter故障所影響。
<本文作者:王偉任,Microsoft MVP及VMware vExpert。早期主要研究Linux/FreeBSD各項整合應用,目前則專注於Microsoft及VMware虛擬化技術及混合雲運作架構,部落格weithenn.org。>