路由協定可以分成內部路由協定和外部路由協定兩大類型,而對內部路由協定而言,所採用的路由演算法有三種類型:Distance Vector、Link State以及混合前面兩種的方法。本文將介紹內部路由協定最常使用的距離向量路由演算法,也就是Distance Vector路由演算法。
在眾多的路由運算法中,Distance Vector這種路由演算法是用方向與所必須經過的設備數目(Hops)來決定網路路徑,方向就是Vector的含意,而所必須經過的網路設備數目指的就是Distance,是相當重要的路由協定演算法。讀者經常聽到的RIPv1、RIPv2、IGRP以及EIGRP等路由協定都是採用這類型的路由演算法,由此可知其重要性。 文章的後半部,會談到Distance Vector路由演算法可能帶來哪些缺點,以及這些問題的解決方案。
路由協定在自治系統的分類
路由協定有很多分類的方式,其中一種分類方式是根據自治系統的運作範圍來做區分。自治系統就是指Autonomous System,簡稱為AS。一個自治系統指的是所有處於同樣管理網域(Administrative Domain)下所有網路的集合,而一個管理網域指的是主機、路由器與內部連接網路的集合,而這個集合是歸屬於相同的管理下運作的。
某些路由協定是運作在同一個自治系統之中,而有些路由協定則運作在不同的自治系統之間。若以運作於自治系統的內部與外部來區分路由協定,可以分成內部路由協定(Interior Gateway Protocol)與外部路由協定(Exterior Gateway Protocol)。內部路由協定簡稱為IGP,外部路由協定則簡稱為EGP。屬於內部路由協定的路由協定包含RIPv1、RIPv2、IGRP、EIGRP和OSPF,而屬於外部路由協定的路由協定則有BGP。這一篇文章將著重在於內部路由協定的部分。
Distance Vector路由演算法運作方式
對於內部路由協定而言,其所採用的路由演算法大致分為以下三種:
1. Distance Vector
2. Link State
3. Balanced Hybrid
簡單來說,Distance Vector是用方向與所必須經過的設備數目來決定路徑,並會在鄰近的路由器設備之間將這些路徑資料互相分享,而Link State則是使用最短路徑演算法(Shortest Path First)。
Distance Vector路由演算法與Link State路由演算法最大的不同就是,Link State演算法只會傳遞少部分更新的路由資料,而且會把這樣的更新資料傳遞到各個路由器設備內,而Distance Vector路由演算法則會傳遞整份的資料,而且只會傳遞給鄰近的路由器設備而已。
不過,即使路由資料沒有任何的改變,Distance Vector也會將整份路由資料發送出來,而這裡所謂的整份路由資料,指的就是發送端路由器設備中Routing Table的完整資料,當鄰近的路由器設備收到這整份路由資料後,會開始比較已知的路由路徑,並把有更新過的資料同步至本地端路由器設備中,因為這種方式都會假設接收到的資料一定是比自己還要新的資料,所以這種方式通常也被稱為「謠言路由方式」(Routing by rumor)。
就是因為這樣類似「以訛傳訛」的運作方式,所以會產生很多問題,而這些問題和解決方案會在下面為各位讀者一一介紹。
基本上,Distance Vector路由演算法也是Classful路由演算法之一。RIPv1、RIPv2、IGRP和EIGRP等路由協定都是採用這類型的路由演算法,不過EIGRP也有部分Link State路由演算法的特徵。而由於Distance Vector路由演算法會根據必須經過的設備數目(Hops)來衡量路徑的好壞,因此對那些直接連接的Router設備而言,其Hops Count的值為0。
之後,隨著Distance Vector路由演算法開始運作,Router設備會開始根據鄰近Router設備所提供的路由資料,來尋找那些並不是直接連接的最佳路徑,因為鄰近Router設備所提供的路由資料中,對於自己這台Router設備而言,有些並不是直接連接的,所以可以從這些資料中學習到其他網路部分的路徑情況,以下這個圖就是一個簡單的例子:
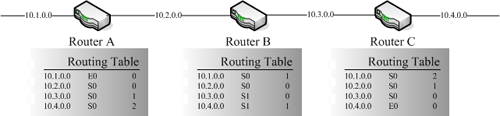 |
| ▲連接Router設備的網路架構圖。 |
假設Router A的左邊為E0介面,右邊為S0介面,Router B的左邊為S0介面,右邊為S1介面,Router C的左邊為S0介面,右邊為E0介面。
由上圖中可以發現,每一台Router設備對於旁邊直接連接的網段,在Routing Table中的值為0,因為毋須經過任何網路設備就可以到達這些網段,所以Hops Count為0。
隨後,這些Router設備會把自身的Routing Table與其他鄰近的Router設備分享,所以Router B可以從Router C所送來的資料中學習到透過Router C到達10.4.0.0的網段,因此在Router B的Routing Table中,10.4.0.0的值為1,因為必須透過一台設備才能到達。
接著,Router B會把Routing Table丟給Router A。此時,Router A就會發現,因為Router B要到達10.4.0.0必須經過一台網路設備,所以從Router A到10.4.0.0必須經過兩台網路設備,也因為還要多經過Router B,在Router A設備中的Routing Table裡,10.4.0.0的值將為2。
最後,針對10.4.0.0這筆資料,會記錄下10.4.0.0, S0, 2,代表「可以從這台設備的S0介面出去,經過兩台網路設備之後,可以到達10.4.0.0的網路區段。」 讀者應該可以發現這Distance Vector的精髓,為什麼要稱為Distance Vector。從剛剛的Routing Table中可以發現,其資料會記錄S0和2這兩種資料,其中S0代表要從哪個「方向」出去,而2則是記錄下「距離」,因此多筆這樣的資料就會形成一個距離向量的資料集合。(更多精采文章詳見網管人第55期)