在上篇和中篇內容中,已經設定好將iSCSI Target的儲存資料透過網路鏡像同步技術,即時地將儲存資料進行同步,並設定高可用性容錯機制中的IP位址接管技術,套用於屆時的iSCSI高可用性服務上。
本文將實作iSCSI Initiator主機如何存取iSCSI Target所分享的儲存資源,並且在iSCSI高可用性服務上線之前進行相關的災難演練測試,以便災難真的發生時不致手忙腳亂。
藉著災難演練,建立企業的相關災難回復標準作業流程(SOP),同時當遇到特殊情況須要將兩台叢集主機都關機(例如更換機房)的情況時,叢集主機應如何正確關機及開機,以確定叢集服務運作無誤。
iSCSI Initiator主機設定
以下從啟動iSCSI Initiator服務、新增iSCSI Target儲存資源IP位址、設定VMware ESX掛載iSCSI Target儲存資源三方面,來進行iSCSI Initiator主機的相關設定。
啟動iSCSI Initiator服務
此次啟動iSCSI Initiator服務實作中採用的軟體式iSCSI Initiator為VMware vSphere Hypervisor中的iSCSI Software Adapter。
在VMware vSphere Hypervisor主機中,除了預設的Service Console之外,由於須要存取iSCSI Target,所以必須建立VMkernel Port,以用來存取iSCSI Target儲存資源的IP Storage網路(若採用VMware ESXi版本則不需要再建立VMkernel Port)。
待完成建立VMkernel Port後,便可以接著啟動VMware vSphere Hypervisor上的iSCSI Initiator服務。啟動iSCSI Initiator方式如下:
STEP 1:執行VMware vSphere Hypervisor控制台軟體「VMware vSphere Client」。
STEP 2:登入VMware vSphere Hypervisor之後,先點選切換至〔Configuration〕標籤頁,然後點選Hardware項目清單中的「Storage Adapters」項目。
STEP 3:在右邊Storage Adapters視窗中點選iSCSI Software Adapter內的「vmhba33」介面卡。接著點選「Properties」,以便查看iSCSI Software Adapter設定內容(圖1)。
STEP 4:在彈出的iSCSI Initiator(vmhba33)介面卡設定內容中,切換至〔General〕標籤頁內,然後按下〔Configure〕按鈕。
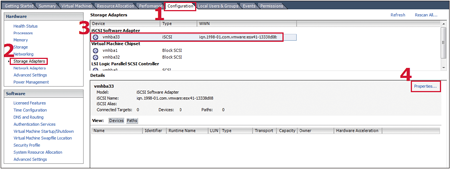 |
| ▲圖1 選擇iSCSI Software Adapter介面卡準備啟動iSCSI Initiator服務。 |
STEP 5:在彈出的「General Properties」設定內容的視窗當中,勾選「Status」區塊內的「Enabled」項目,然後按下〔OK〕,就可以輕鬆啟動iSCSI Initiator的服務(圖2)。
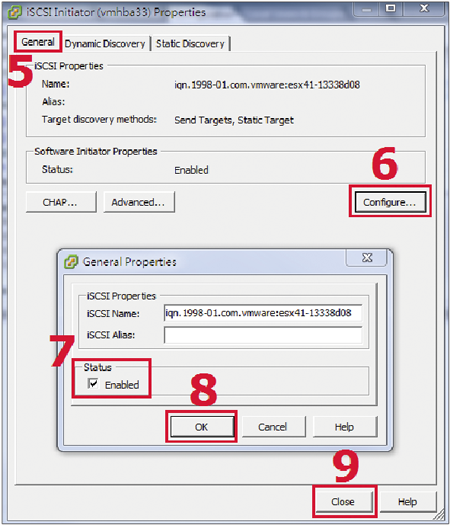 |
| ▲圖2 啟動iSCSI Initiator服務。 |
新增iSCSI Target儲存資源IP位址
成功啟動VMware vSphere Hypervisor主機上的iSCSI Initiator服務後,接著指定iSCSI Target儲存資源的IP位址,設定方式如下:
STEP 1:執行VMware vSphere Hypervisor控制台軟體「VMware vSphere Client」。
STEP 2:登入VMware vSphere Hypervisor後,先切換到〔Configuration〕標籤頁,接著點選「Hardware」項目清單中的「Storage Adapters」項目。
STEP 3:在右邊「Storage Adapters」視窗中點選iSCSI Software Adapter內的「vmhba33」介面卡,然後點選「Properties」以便查看iSCSI Software Adapter設定內容。
STEP 4:在彈出的iSCSI Initiator(vmhba33)介面卡設定內容之中,切換至〔Dynamic Discovery〕標籤頁內,接著按下〔Add〕按鈕來新增iSCSI Target儲存資源的IP位址。
STEP 5:接著,在跳出Target Server設定視窗之後,輸入iSCSI Target IP位址「10.10.25.135」,然後按一下〔OK〕按鈕,就可以完成新增iSCSi Target儲存資源的動作(圖3)。
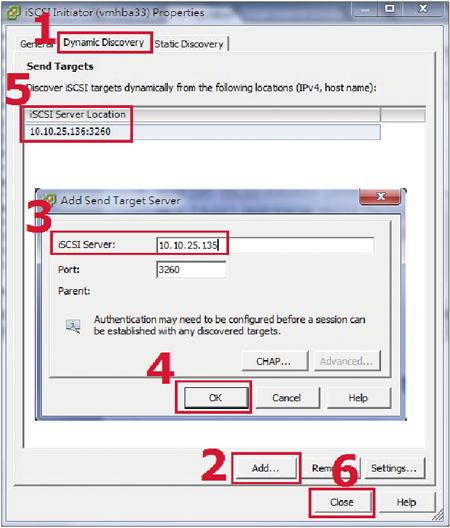 |
| ▲圖3 新增iSCSI Target儲存資源IP位址。 |
STEP 6:此時系統會提示要進行系統資源重新掃描(Rescan)的動作。按下〔Yes〕按鈕進行掃描。掃描完成後,便可看到iSCSI Target資源(圖4)。
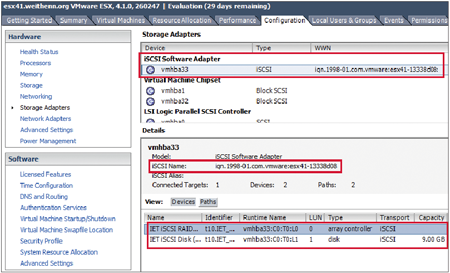 |
| ▲圖4 iSCSI Initiator裝置成功偵測到iSCSI Target儲存資源。 |
設定VMware ESX掛載iSCSI Target儲存資源
上述存取iSCSI Target儲存資源前置作業完畢後,便可開始設定VMware vSphere Hypervisor掛載iSCSI Target儲存資源,將該儲存資源掛載成為VMware vSphere Hypervisor資源池Datastore來使用。屆時,虛擬主機(VM)也將運作於此儲存資源池內,相關設定方式如下:
STEP 1:執行VMware vSphere Hypervisor控制台軟體「VMware vSphere Client」。
STEP 2:登入VMware vSphere Hypervisor後,先切換至〔Configuration〕標籤頁內,然後點選Hardware項目清單中的「Storage」項目。
STEP 3:在右邊Datastores視窗中點選「Add Storage」,準備新增iSCSI Target儲存資源至Datastores內(圖5)。
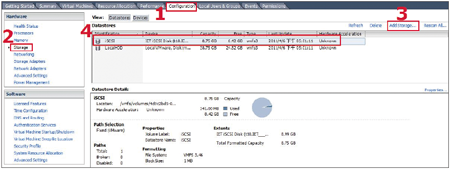 |
| ▲圖5 VMware ESX成功掛載iSCSI Target儲存資源。 |
STEP 4:在彈出的視窗中,先選擇所要新增的儲存資源種類,請選擇「Disk/LUN」項目並按下〔Next〕繼續後續的動作。此時,系統將開始透過剛才設定的iSCSI Initiator服務及設定的Dynamic Discovery,去偵測iSCSI Target儲存資源。
STEP 5:因為相關設定皆正確無誤,所以系統順利偵測到iSCSI Target儲存資源出現在視窗中。選擇儲存資源項目「IET iSCSI Disk 9 GB」後按下〔Next〕繼續。
STEP 6:系統會提示必須將剛才選擇的儲存資源進行格式化為vmfs檔案系統。然後,按下〔Next〕繼續後續的動作。
STEP 7:格式化完成後,輸入屆時在Datastore中要辨識此儲存資源的名稱,本例輸入名稱為「iSCSI」,然後按下〔Next〕按鈕。
STEP 8:選擇格式化此檔案系統時的Block size,此設定值為屆時可儲存的單一檔案大小極限值為何。此次設定中採用預設值即可,並按下〔Next〕繼續下一步。
STEP 9:上述設定都確定後,按一下〔Finish〕按鈕確定新增iSCSI Target儲存資源掛載至系統的動作。
當VMware ESX成功掛載iSCSI Target儲存資源之後,便可以開始將虛擬主機(VM)建立於該儲存資源內。
另外,可以在Primary Node上執行tgtadm指令搭配show參數來查看有誰掛載iSCSI Target儲存資源。如下所示,可以看到iSCSI Initiator資訊為VMware ESX(iqn.1998-01.com.vmware:esx41-13338d08)。
災難測試
以下透過手動切換叢集節點、交換器/網路卡損壞或網路線被踢掉、虛擬主機運作中切換叢集節點等三種方式來進行災難測試。
測試一:手動切換叢集節點
進行高可用性容錯機制,首先測試利用手動方式來切換叢集節點。待容錯機制測試成功後,再著手進行更進一步的災難測試。
假設情境為需要將Primary Node主機關機進行硬體維護(例如更換損壞的記憶體),但又想保持其服務持續運作,便可以使用手動切換叢集節點的方式來進行處理。
而手動切換叢集節點時,只要在Primary Node(Active Node)上將Heartbeat服務重新啟動即可。可以同時開啟兩個遠端登入視窗,一個登入Node1主機,另一個登入至Node2主機。
在Node2主機先執行「watch –n 1 service drbd status」指令來即時查看叢集運作狀態,接著在登入Node1主機的視窗中,執行Heartbeat服務重新啟動的指令「service heartbeat restart」,即可叢集服務切換節點主機的運作狀態變化,而且會提醒在此次實作中當原來的Primary Node上的Heartbeat服務再次啟動後,並不會將主動權搶回。
這是因為在Heartbeat通訊設定檔「/etc/ha.d/ha.cf」中錯誤後回復機制設定值「auto_failback」為「off」。
假若Heartbeat通訊設定檔中的「auto_failback」設定值為「on」,則當原來的Primary Node(現在為Secondary Node角色)其Heartbeat服務再次啟動後便會將主動權搶回,再次成為Primary Node(Active Node)。
當Heartbeat服務重新啟動指令執行時會看到,Node2主機中執行觀察的DRBD狀態變化,其Node1主機狀態為「Primary/Secondary >> Secondary/Secondary >> Secondary/Primary」。當Heartbeat服務重新啟動指令執行完成後,在Node2主機上就可以看到已經接手Primary Node角色及相關服務:
● 系統掛載「/dev/drbd0」(iSCSI Target儲存資源「/storage/iscsi」)。
● 接手iSCSI Target服務(tgtd)。
● 產生虛擬叢集網卡(bond0:0)以及IP位址「10.10.25.136」。
測試二:交換器/網路卡損壞或網路線被踢掉
因為此次實作的叢集架構中,不管是網路服務線路或叢集主機之間用來互相偵測的心跳線,皆有使用兩個實體網路卡及網路線分接不同的網路交換器進行容錯保護,所以這裡先測試在一個實體網路卡或一台網路交換器損壞的情況下,先前所設定的網卡綁定模組(Bonding)是否正常運作進行容錯切換。
接著,才測試當Primary Node叢集主機上用於同一服務的兩張實體網路卡都損壞的情況下,是否會自動將服務切換到Secondary Node。
由於先前設定網路卡綁定模組的運作機制為網卡容錯方式,也就是平時只有一個實體網路卡會進行資料傳輸,而另一個為待命狀態,待Active網路卡傳輸發生異常時,Backup網路卡才接手傳輸工作(Active/Backup由系統自動處理及判斷)。
因此,可以將兩個虛擬網路卡bond0、bond1中的實體網路卡成員中拔掉正連接於其中一個網路卡的網路線(或者將該網路卡停用也可以),來測試看看網卡容錯機制是否運作。
此測試動作為在Primary Node叢集主機上拔掉正連接於eth0、eth3實體網路卡上的網路線,而Secondary Node叢集主機上則拔掉接於eth1、eth2實體網路卡上的網路線,看看網路連線及叢集服務是否都正常運作。當然,也可以執行如下指令在叢集主機上來關閉指定的網路卡,而省略了實體主機前面拔線的動作。
在上述測試實體網路卡及網路線脫落的情況皆通過並恢復環境後,接著嘗試將其中一台網路交換器關閉,以測試叢集是否正常運作。
當上述情況都通過測試後,可以把接於Primary Node叢集主機bond0虛擬網卡上的eth0、eth1網路線拔掉,模擬當主機服務線路斷線時的狀況。
當主機服務線路斷線超過15秒鐘後,Secondary Node仍然無法偵測到對方主機存活時,是否會判定Primary Node主機失效,並觸發錯誤後轉移機制(Failover),進而將相關服務和儲存資源接手過來。筆者測試的結果當然是Secondary Node會正確接手相關服務及儲存資源。
測試三:虛擬主機運作中切換叢集節點
上述基本容錯測試都完成後,緊接著進行最後的容錯機制測試,由於此次建置的高可用性iSCSI Target儲存資源是提供運作於Hypervisor之上的虛擬主機,因此在此測試項目為,當虛擬主機在運作的情況下,儲存資源發生災難後虛擬機是否仍然可以存取及提供服務。
測試方式為同時開啟兩個遠端登入視窗,一個登入Primary Node主機,另一個為Secondary Node主機。先於Secondary Node執行「watch -n 1 service drbd status」指令,來即時查看叢集運作狀態,接著開啟「vSphere Client」選擇運作於iSCSI-Target的虛擬主機,然後按下滑鼠右鍵,選擇快速選單內的【Open Console】,以便等一下叢集節點切換時,可以在切換期間測試虛擬主機操作是否正常。
另外,也開一個視窗來持續Ping該虛擬主機IP位址,並且開啟「Datastore Browser」上傳檔案至VMware vSphere Hypervisor資源池內。
以上測試條件準備完成後,開始進入重頭戲,將Primary Node主機直接進行關機的動作(更甚者可以直接把電源線拔掉,但這樣的測試動作請盡量減少)。
當Primary Node主機執行關機的動作之後,一方面觀察已登入Secondary Node視窗,其叢集運作狀態是否正將相關服務及儲存資源接手過來,另一方面對虛擬主機進行相關操作,例如新增、刪除、複製檔案等動作。
同一時間,觀察持續Ping視窗在叢集節點切換期間是否有遺失封包的情況,當然還有上傳檔案至VMware vSphere Hypervisor資源池的狀況。
在筆者的測試環境條件下,叢集節點切換時間約35秒左右。在節點期間,虛擬主機仍然可進行相關操作,只是反應速度會比平常緩慢。至於持續Ping虛擬主機的動作,則是沒有遺失任何封包的情況發生。
而上傳檔案的視窗,在節點切換期間並沒有斷掉而是持續嘗試連接,且傳輸預估時間拉長而已。待節點切換完成恢復高速傳輸後,再衝全速把檔案傳輸完畢,至此災難測試完美結束。
叢集主機硬體維護
企業使用的伺服器硬體,雖然原廠在設計上皆為可供長時間持續運作,但實際上隨著運作時間一久,難免會遇到部分零件損壞或其他因素而需要關機檢修的情況。
當然,若僅僅是單台叢集主機須要關機進行檢修,可以利用於Primary Node重新啟動Heartbeat服務,將相關服務和儲存資源切換到備援叢集節點接手。
但是,若遇到特殊情況需要將兩台叢集主機都進行關機檢修,或者機器要轉移放置地點(如更換機房)的情況,叢集主機如何地正確關機及開機,以確定叢集服務運作無誤其標準作業流程將是必要的,以下簡述這些流程。
正確關機流程
首先,運作於Hypervisor之上的虛擬主機全部關機。接著,在Primary Node叢集主機上執行Heartbeat服務重新啟動的指令,以便將相關服務及儲存資源轉由Secondary Node主機接手。第三步驟則是,確認Secondary Node叢集主機接手成功後,即可將Primary Node主機關機,此時在Secondary Node看到的DRBD狀態應為Primary/Unknown。
接著,確認無人存取iSCSI Target資源後,將Secondary Node(現為Primary Node)主機iSCSI Target服務強制停止後,即可關機。
因為此時雖然沒有任何的iSCSI Initiator發出存取要求,但是因為iSCSI Initiator已經掛載iSCSI Target儲存資源,因此若先不強制停止iSCSI Target服務(將iSCSI Initiator連線斷開)便進行關機動作的話,系統可能會在關機程序中卡住。
最後,此時的Primary/Secondary Node皆已經關機完成,之後再依下面提到的正確開機流程進行開機的動作,即可恢復高可用性的iSCSI Target儲存資源。
正確開機流程
首先,將Primary Node開機,約莫等待1分鐘後再將Secondary Node開機。接著,當Primary Node開機程序運作至DRBD啟動程序的時候,會倒數60秒等待Secondary Node的回應。
在倒數讀秒期間Secondary Node運作至DRBD啟動程序時,兩台叢集主機會先確認區塊裝置「/dev/drbd0」內所儲存的資料是否同步一致,確認同步一致之後,繼續完成開機動作。
待兩台主機皆開機完成後,先登入至Primary Node查看相關服務及儲存資源是否正常運作,亦即Primary Node主機是否成功掛載「/dev/drbd0」至「/storage」、啟動iSCSI Target服務(tgtd)、擁有叢集虛擬網路卡bond0:0及叢集虛擬IP位址「10.10.25.136」。
緊接著,由於VMware ESX Host每隔一段時間就會自動檢查是否可以存取掛載的資源池,因此會發現先前因為叢集主機關機遷移時導致Hypervisor偵測到iSCSI Target儲存資源而發生暫時失聯的情況(圖6~7)。
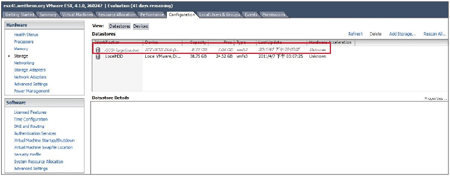 |
| ▲圖6 Hypervisor偵測到iSCSI Target儲存資源失聯的情況。 |
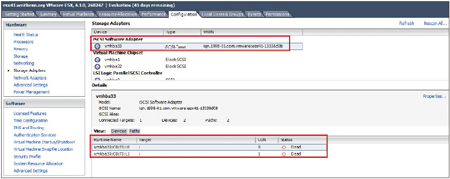 |
| ▲圖7 Hypervisor偵測到iSCSI Target儲存資源失聯,因而導致存取路徑不通。 |
此時叢集服務已經恢復運作,因此可以開啟「vSphere Client」,並選擇「Configuration」以及選擇Hardware下的「Storage」,然後按下「Refresh」即可回復iSCSI Target儲存資源池。
但請注意,不要按下「Add Storage」來新增iSCSI Target儲存資源,因為此舉有可能會不小心將儲存於iSCSI Target內的資料清除(格式化)掉。
當Hypervisor內的iSCSI Target資源池恢復存取後,即可將虛擬主機(VM)開機,並確定運作於虛擬主機上的相關服務是否運作正常。
至此,開機流程完成,高可用性iSCSI Target儲存資源恢復運作了。
若將叢集主機開機後仍然發生iSCSI Target服務並未自動把相關儲存資源掛載起來,請查看系統紀錄檔內容(/var/log/messages)。檢查紀錄檔內容中是否有「Could not open /storage/iscsi, No such file or directory」相關訊息。
此一錯誤訊息代表系統無法掛載iSCSI Target儲存資源因而導致這個錯誤,原因在於雖然DRBD(啟動順序S70)、Heartbeat(啟動順序S75)服務的啟動順序早於「/etc/rc.local」(啟動順序S99),但因為DRBD、Heartbeat服務在啟動後須要執行一些前置作業(例如檢查兩台叢集主機節點之間區塊裝置「/dev/drbd0」資料是否同步完成),因此須要花費一些檢查時間。
而在此同一時間內很可能會發生DRBD、Heartbeat服務還沒啟動完成(尚未掛載「/dev/drbd0」至「/storage」)的情況,但是系統已經執行「/etc/rc.local」中的內容,此時就會造成無法掛載iSCSI Target儲存資源的情況。
在筆者的測試環境中,延遲60秒的時間便已經相當足夠,倘若讀者所在的環境中系統還是發生來不及掛載iSCSI Target儲存資源的問題的話,請查看系統紀錄檔內容中的服務啟動訊息,以決定在該環境中到底應該延遲多少時間之後再進行調整。
例如,在下列系統紀錄檔「/var/log/messages」內容中,可以看到30分58秒時系統已經運作到執行「/etc/rc.local」的內容,但此時系統仍然尚未發現iSCSI Target儲存資源檔案(因為尚未掛載「/dev/drbd0」至「/storage」,當然無法發現「/storage/iscsi」檔案),一直到31分10秒時,系統才執行掛載「/dev/drbd0」至「/storage」的動作(此時DRBD、Heartbeat服務才整個啟動完成)。
所以由紀錄檔中可以得知,在此環境中至少須要延遲12秒以上後再執行iSCSI Target儲存資源開機自動掛載Script(/usr/local/sbin/tgtd_boot.sh)。
結語
就目前來看,虛擬化趨勢已經鋪天蓋地而來勢不可擋,而虛擬化技術之所以如此熱門,其原因在於導入虛擬化解決方案後對於IT管理上有諸多好處。
例如,伺服器合併後高集縮比,為企業所帶來的立即效益是,減少以往過多設備資源閒置的情況、設備耗費電力降低、設備產生的熱能減少、機房的冷房能力負擔降低、設備占用機櫃空間減少、網路布線的環境單純化等,進而減少企業IT整體成本。
並且,當企業須要建置新系統環境、部署研發測試環境、系統備援環境、系統災難復原環境上,都將比以往更能省下內部採購流程時間,及部署系統環境時所花費的人力物力及成本。
最後,則是虛擬化技術在不需要作業系統或應用程式支援的情況下,即可為企業服務達成高可用性的目標,並且可以視企業需要,隨時將虛擬主機進行線上遷移至別台主機,以便檢查實體伺服器或進行歲修。
然而,要建置具備高效率及高穩定性的虛擬化架構,通常必須採用光纖作為傳輸媒介的儲存區域網路(FC-SAN),也就是除了高效能的伺服器外,至少還要採購FC HBA卡及SAN交換器,並配合SAN儲存設備。但如此的高額建置成本,對於一般中小企業來說卻是一筆沈重的預算且遙不可及的。
但是,是否就因而放棄呢?答案是否定的。託IP-SAN技術之福,一般中小企業得以採用花費相對便宜的解決方案來為企業導入虛擬化技術。
本文便是採用自由軟體作業系統CentOS來架設IP-SAN儲存設備,並配合企業內部常見的網路交換器及安裝於伺服器上的一般網路卡來進行資料傳輸,並且採用免費版本的Hypervisor來承載虛擬機器提供服務。
當然為了確保資料的一致性及高可用性,也導入了自由軟體中知名的DRBD及Heartbeat套件來達成這樣的目標,希望能藉此架構為一般中小企業提供具備資料保全及高穩定性,卻又便宜的伺服器合併高集縮比的虛擬化環境解決方案。