「聽說就拿出來講?」這是前一陣子筆者同事和世界某知名智慧型手機製造商洽談時,所聽到的用語。到底「聽說」來的資訊,是否可以拿出來講?這可能要看情況,以網路路由器來說,把聽說來的資訊(也就是可能不準確的資訊)拿出來與其他路由器設備分享,可能就會造成很大的問題,因為出現了「路由?圈」。
同樣地,路由器A設備也會更新10.4.0.0網段的Hops Count為4。這個時候,錯誤已經到了難以彌補的地步,因為現在所有的網路設備對於10.4.0.0網段的資訊全都是錯誤的!10.4.0.0網段事實上根本就沒有辦法到達。
接下來,路由器A設備會一直傳送這樣的錯誤訊息給其他設備,所以各個路由器設備對於10.4.0.0網段的Hops Count值可能會趨近於無限大(Count to infinity),這就是第二個可能造成的問題。而且,這個時候若有任何封包是要送往10.4.0.0網段,那這個封包是根本不可能成功送到目的地,而會在各個路由器之間傳遞著,也就是出現路由迴圈(Routing Loop)問題。以下就來說明該如何解決Count to infinity和路由迴圈問題。
Count to infinity解決方案
Count to infinity所指的問題,就是路由器設備嘗試不斷地增加Hops Count,而其所要到達的網段根本就無法到達。這問題的解決方案較簡單,就是去定義一個Hops Count的最大值,RIP協定預設的最大值為16,所以當Hops Count增加到16後,就不會再繼續增加了。
同時也代表,當發現Routing Table中有Hops Count到達16這樣的最大值,就表示這條路徑是無法到達的,因此就不會繼續把這樣的資料分送給其他路由器設備。所以像剛剛之前這個範例,若套用這樣的解決方案,其各個路由器設備的Routing Table就會變成圖7這個樣子。
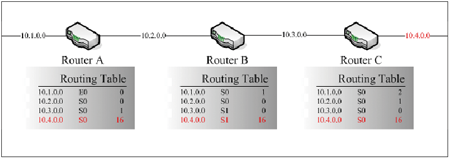 |
| ▲圖7 Count to infinity解決方案。 |
路由迴圈解決方案說明
路由迴圈問題的詳細情況,前面都已經提過了,而解決路由迴圈問題有很多種方法,其中包含Split Horizon、Route Poisoning、Poison Reverse、Hold-Down Timer以及Triggered Update,下面一一介紹這五種路由迴圈的解決方案。但要注意的是,這五種解決方案必須一起使用,並不是其中一種就可以完整地解決路由迴圈問題。
Split Horizon
Split Horizon這個解決方案的精神就是,絕對不向這筆資訊的來源端發送與這筆資料有關的更新動作。這個方法能夠有效避免路由迴圈問題,也可以加速Routing Table的資料收斂過程。所謂的收斂過程代表的是當網路發生變化,網路上各個網路設備的Routing Table從發生變化開始到真正把變化反應到Routing Table的過程,就叫做Routing Table的收斂過程。繼續使用上面提到的範例來說明,如圖8所示。
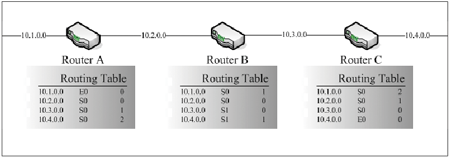 |
| ▲圖8 Split Horizon解決方案。 |
以圖8的網路圖為例,對路由器B設備而言,10.4.0.0網段可以從S1介面出去,透過路由器C設備而到達,而這樣的訊息是路由器C設備告訴路由器B設備,所以路由器B設備才知道可以透過路由器C設備而到達,所以以後根本沒有理由透過路由器B設備來告訴路由器C設備,路由器B設備可以到達10.4.0.0網段,因為路由器C設備事實上應該比路由器B設備還要了解10.4.0.0網段。
同樣的道理,路由器B設備也不應該發送有關10.1.0.0網段的更新資料從S0介面給路由器A設備,S0介面對路由器B設備而言,就是這筆資料的來源端,除了這個來源端外,這筆資料可以從其他的介面和其他Router設備做更新的動作。
Route Poisoning
Route Poisoning的解決方法主要是解決因為資料不一致的更新動作而產生的路由迴圈問題,如圖9所示:
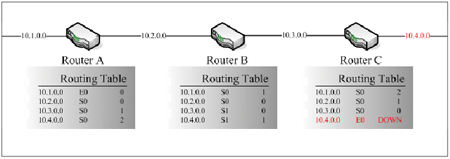 |
| ▲圖9 Route Poisoning解決方案。 |
其做法是當路由器C設備發現鄰近的10.4.0.0網段發生異常時,會在自己的Routing Table中將這一筆資料標示成無法到達,並把這樣的資訊傳送給其他Router設備,這樣一來,其他的Router設備才能知道10.4.0.0網段是有問題的。這種方式就稱為Route Poisoning。
Poison Reverse
接續剛剛的Route Poisoning,下一個所產生的解決方式就是Poison Reverse。上面的Route Poisoning範例中提到,當路由器C設備發現10.4.0.0網段無法到達的時候,路由器C設備會在自己的Routing Table中將關於10.4.0.0網段的資訊設定成DOWN,也就是無法到達,然後會把這資訊傳遞出去。
接著,當路由器B設備收到這樣的訊息後,路由器B設備會先更新自己的Routing Table,把10.4.0.0網段標示為Possibly Down,而路由器B設備也會傳送一個訊息給路由器C設備,這樣的回傳訊息動作就是Poison Reverse,如圖10所示。
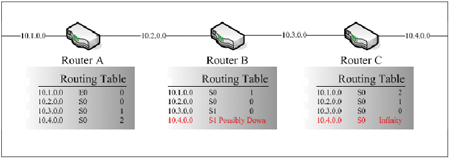 |
| ▲圖10 Poison Reverse解決方案。 |
所以,此時路由器B設備也知道10.4.0.0網段是無法到達的,而路由器C設備對於10.4.0.0網段的資訊也多了一台設備的確認,比較能夠解除擁有錯誤訊息的疑慮。
有些讀者應該可以發現,這個解決方式好像和Split Horizon有衝突,看起來的確是,但要注意,Split Horizon對於Poison Reverse是不適用的,也就是Poison Reverse會覆蓋原有Split Horizon的機制。
Hold-Down Timers
上一個Poison Reverse中提到,當路由器B設備收到路由器C設備所傳來關於10.4.0.0網段的「噩耗」之後,會在自己的Routing Table中,把10.4.0.0網段標示為Possibly Down,因為路由器B設備會覺得搞不好10.4.0.0網段很快就好了,或者可能會收到關於10.4.0.0網段的更新資訊,所以此時路由器B設備會等候一陣子。在這期間,允許其他Router設備重新計算對於10.4.0.0網段的路徑,並傳送到路由器B設備這裡來。這個等候機制就稱為Hold-Down Timers。
對於RIP路由協定而言,其Hold-Down Timers所等待的時間是一般定期路由資訊更新時間的三倍,也就是180秒,而IGRP路由協定是280秒。所以在Hold-Down Timers的時間內,路由器B設備有收到關於10.4.0.0網段更好的路徑資訊時,路由器B設備會接納這樣的路徑資訊,將10.4.0.0網段標示為可到達,並且把Hold-Down Timers關閉。但如果在Hold-Down Timers時間之內,收到比原本更糟的路徑資訊,或是與原本所持有的路徑資訊差不多的話,則路由器B設備會忽略所收到的更新資訊。