上一篇文章中,筆者為各位介紹許多有關Cisco設備上的訊框中繼網路技術,簡單說明了訊框中繼網路的封裝技術、專業用語、網路架構和訊框中繼網路所可能遇到的問題,這篇則預計為各位講解訊框中繼網路問題的解決方案。
訊框中繼(Frame Relay,又稱為幀中繼)網路協定是一個效能相當高的廣域網路協定,運作於OSI網路模型中的實體層(第一層)和資料連結層(第二層)。訊框中繼網路協定是連線導向的網路協定,因此訊框中繼網路協定可以提供高效率而且品質很好的網路連線。而在網路傳輸資料的錯誤偵測與保護方面,訊框中繼網路協定依賴於高階層的網路協定。訊框中繼網路協定定義了介於路由器和網路服務供應商的交換機設備之間的互動連線。但是,訊框中繼網路協定並沒有定義網路封包如何被傳送。
何謂虛擬線路
虛擬線路(Virtual Circuit)是由資料連結連線辨識元(Data-link Connection Identifier,DLCI)所辨識出來的,是邏輯性線路。虛擬線路用來保證兩台資料終端設備(DTE)之間的雙向通路。多條虛擬線路可以集結成單一一條實體線路。這種特性可以降低多台資料終端設備(DTE)之間的複雜度。而單一一條虛擬線路可以通過任意個中繼的資料線路終端設備(DCE),也就是用於訊框中繼網路的交換機。虛擬線路有兩種型態,一種是永久性虛擬線路(Permanent Virtual Circuit),另一種則是交換式虛擬線路(Switched Virtual Circuit)。單一一條虛擬線路可以是這兩種類型的其中一種,若不是永久性虛擬線路,就一定是交換式虛擬線路。
交換式虛擬線路(SVC)
在訊框中繼網路之中,交換式虛擬線路(Switched Virtual Circuit,SVC)主要針對偶然才會須要傳遞資料的連線,提供網路連線。當然,提供服務的對象是位於訊框中繼網路之中的資料終端設備。在使用交換式虛擬線路之前,必須建立連線,這種建立的動作是依據需求才產生的(On Demand),而連線結束時,也必須關閉連線。Cisco IOS在11.2以後的版本就支援交換式虛擬線路。
永久性虛擬線路(PVC)
在訊框中繼網路中,有些網路連線需要非常頻繁地流通,甚至是永久性流通,此時,永久性虛擬線路(Permanent Virtual Circuit,PVC)就可以針對這種需求,對於資料終端設備之間的訊框中繼網路提供永久性連線。藉由永久性虛擬線路產生的連線並不需要像交換式虛擬線路一樣還需要建立連線(Setup)和關閉連線(Teardown)等等的過程。
路由協定所使用的演算法 對於內部路由協定而言,其採用的演算法也不盡相同,其所採用的演算法大致分為以下三種:
簡單來說,Distance Vector是用方向與所必須經過的設備數目(Hops)來決定路徑。而Link State則是使用最短路徑演算法(Shortest Path First)。至於Balanced Hybrid則是綜合了Distance Vector和Link State兩種演算法。這三種演算法,並沒有所謂哪一種是最好的,只能說適用於不同的情況,因為這三種不同的演算法提供了不同的資訊。
Distance Vector路由演算法與Link State路由演算法最大的不同就是,Link State演算法只會傳遞少部分更新的路由資料,而且會把這樣的更新資料傳遞到各個Router設備中,而Distance Vector路由演算法則會傳遞整份的資料,而且只會傳遞給鄰近的Router設備而已。不過即使路由資料沒有任何的改變,Distance Vector也會將整份路由資料發送出來,而這裡指的整份路由資料指的就是發送端Router設備中Routing Table的完整資料。
當鄰近的Router設備收到這整份路由資料之後,會比較已知的路由路徑,並把有更新過的資料同步至本地端Router設備中,因為這種方式都會假設接收到的資料一定是比自己還要新的資料,所以也被稱為「謠言路由方式」(Routing by Rumor)。就是因為這樣類似「以訛傳訛」的運作方式,所以會產生很多問題,當然也有解決方案。只是這些解決方案套用在訊框中繼網路上,會不會又產生其他的問題呢?底下就來看看使用Distance Vector演算法的路由協定到底會有什麼問題。
Distance Vector路由協定的問題
接下來要講解的是Distance Vector路由協定的問題,因為筆者將在文末揭發訊框中繼網路的缺點,所以必須先講解一些相關的背景知識——Distance Vector路由協定所可能造成的問題和解決方案。
因為Distance Vector路由演算法只與鄰近Router設備分享整份Routing Table,而且會每隔一段時間就與其他Router設備分享Routing Table的資料,所以當更新動作不夠快的時候,就可能出現資料不一致的問題。以下面的範例來說明Distance Vector路由演算法是在怎樣的情況下讓Routing Table的資料產生不一致的情況。
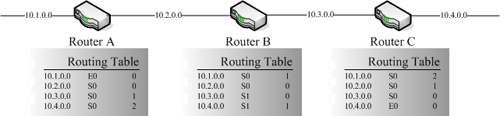 |
| ▲連接Router設備的網路架構圖 |
假設有以上三台Router設備,Router A的左邊為E0介面,右邊為S0介面,Router B的左邊為S0介面,右邊為S1介面,Router C的左邊為S0介面,右邊為E0介面。與之前的範例相同,所以上圖顯示出這三台Router設備目前的Routing Table資料情況。現在假設10.4.0.0的網路區段連線發生問題,同下圖所示。
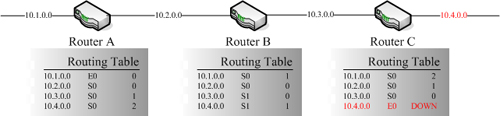 |
| ▲10.4.0.0網段開始發生問題 |
因為Router C設備與10.4.0.0的網路區段是直接連接的,所以Router C設備能夠在第一時間先發現無法到達10.4.0.0網路區段,因此Router C設備會更新自己的Routing Table,標示10.4.0.0網段為無法到達,並且不再發送任何網路封包透過E0介面前往10.4.0.0的網路區段。
但是,這個時候Router A和Router B兩台設備都還不知道10.4.0.0網段發生問題,所以還是相信10.4.0.0網段是可以到達的。接著,當Router B設備準備要發送它的定期對外更新資料的動作時,它會發送自己的Routing Table資料給Router C設備,如下圖所示。
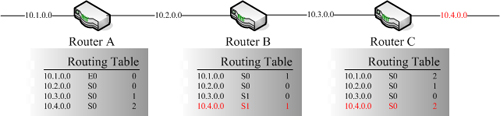 |
| ▲Router C收到關於10.4.0.0的錯誤資料 |
這個時候,因為Router C會從自己的S0介面收到由Router B設備所送過來的Routing Table資料,而此時資料中顯示10.4.0.0網段是可以到達的,所以Router C設備以為原來可以透過自己的S0介面出去,經過Router B設備能夠到達10.4.0.0網段,而且必須經過兩台網路設備(直接把Router B設備的Routing Table中針對10.4.0.0網段的距離加一),於是Router C就會更新自己的Routing Table。此時Routing Table中有錯誤資料的狀況就已經發生了,但是更慘的還在後頭。若此時,Router C設備也到了應該對其他設備做Routing Table同步的動作,如下圖所示。
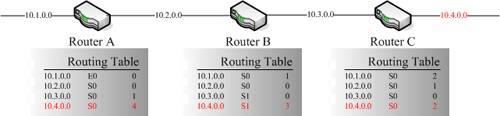 |
| ▲Router C把錯誤資料發送出去 |
Router C設備會先發送自己的Routing Table給Router B設備,此時與上面的情況類似,Router B設備會以為原來可以從自己的S1介面出去,透過Router C設備而到達10.4.0.0網段,所以Router B設備就會乖乖地更新自己的Routing Table,並紀錄前往10.4.0.0網段的Hops Count為3。同樣地,Router A設備也會更新10.4.0.0網段的Hops Count為4。這個時候,錯誤已經到了難以彌補的地步了,因為現在所有的網路設備對於10.4.0.0網段的資訊全部都是錯誤的。事實上,10.4.0.0網段根本就沒有辦法到達。
接著,Router A設備會一直傳送這樣的錯誤訊息給大家,所以各個Router設備對於10.4.0.0網段的Hops Count值可能會趨近於無限大(Count to infinity),這就是第二個可能造成的問題。而且,若這個時候有任何封包是要送往10.4.0.0網段的話,那這個封包是根本不可能成功送到目的地,而是在各個Router之間傳遞著,也就是Routing Loop問題。
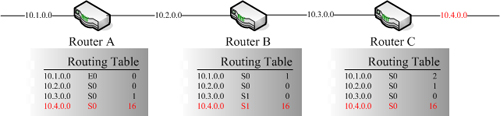
Count to infinity解決方案
Count to infinity所指的問題就是,Router設備嘗試不斷地增加Hops Count,而其所要到達的網段根本就無法到達。這個問題的解決方案比較簡單,就是去定義一個Hops Count的最大值,RIP協定預設的最大值為16,所以當Hops Count增加到16之後,就不會再繼續增加。同時也代表當發現Routing Table中有Hops Count到達16這樣的最大值,就表示這條路徑是無法到達的,因此也就不會繼續把這樣的資料分送給其他Router設備。所以像剛剛這個範例,若套用這樣的解決方案,其各個Router設備的Routing Table就會變成下面這個樣子:
 |
| ▲Count to infinity解決方案 |
Routing Loop解決方案
解決Routing Loop問題有很多種方法,包含Split Horizon、Route Poisoning、Poison Reverse、Hold-Down Timer和Triggered Update。這些都是相當重要的,準備CCNA認證的讀者必須完全了解。下面一一來了解這五種Routing Loop的解決方案,要注意的是,這五種解決方案必須一起使用,並不是其中一種就可以完整地解決Routing Loop問題。
Split Horizon
這個解決方案的精神就是,絕對不向這筆資訊的來源端發送與這筆資料有關的更新動作。這個方法可以有效避免Routing Loop問題,也可以加速Routing Table的資料收斂過程,所謂的收斂過程代表的是當網路發生變化,網路上各個網路設備的Routing Table從發生變化開始到真正把變化反應到Routing Table的過程,就叫做Routing Table的收斂過程。以下繼續使用上面所提到的範例來說明,如下圖所示。
|
| ▲Split Horizon解決方案 |
以上方的網路圖為例,對Router B設備而言,10.4.0.0網段可以從S1介面出去,透過Router C設備而到達,而這樣的訊息是由Router C設備告訴Router B設備,所以Router B設備才知道可以透過Router C設備而到達,所以之後根本沒有理由透過Router B設備來告知Router C設備,Router B設備可以到達10.4.0.0網段,因為事實上Router C設備應該比Router B設備還要了解10.4.0.0網段。
同樣的道理,Router B設備也不應該從S0介面發送有關10.1.0.0網段的更新資料給Router A設備,S0介面對Router B設備而言,就是這筆資料的來源端,除了這個來源端之外,這筆資料可以從其他的介面和Router設備做更新的動作。
Route Poisoning
Route Poisoning主要是用來解決因為資料不一致的更新動作而產生的Routing Loop問題,如下圖所示。
|
| ▲Route Poisoning解決方案 |
其主要的做法就是,當Router C設備發現鄰近的10.4.0.0網段發生異常情況時,在自己的Routing Table中將這一筆資料標示成無法到達,並且把這樣的資訊傳送給其他Router設備,這樣一來,其他的Router設備才能知道10.4.0.0網段是有問題的。這種方式就稱為Route Poisoning。
Poison Reverse
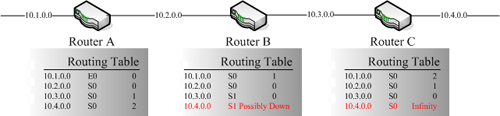
接續剛剛的Route Poisoning,下一個產生的解決方式就是Poison Reverse。上面的Route Poisoning範例中提到,當Router C設備發現10.4.0.0網段無法到達的時候,Router C設備會在自己的Routing Table中將關於10.4.0.0網段的資訊設定成DOWN,表示無法到達,然後把這資訊傳遞出去,接著,當Router B設備收到這樣的訊息之後,Router B設備會先更新自己的Routing Table,把10.4.0.0網段標示為Possibly Down,而Router B設備也會傳送一個訊息給Router C設備,如此的回傳訊息動作就是Poison Reverse,內容如下圖。
 |
| ▲Poison Reverse解決方案 |
所以,此時Router B設備也知道10.4.0.0網段是無法到達的,而Router C設備對於10.4.0.0網段的資訊也多了一台設備的確認,比較能夠解除擁有錯誤訊息的疑慮。不過,這個解決方式似乎與Split Horizon衝突,看起來的確是,但是要注意的是,Split Horizon對於Poison Reverse是不適用的,因為Poison Reverse會覆蓋原有Split Horizon的機制。
Hold-Down Timers
剛剛在Poison Reverse中提到,當Router B設備收到Router C設備所傳來關於10.4.0.0網段的「噩耗」之後,會在自己的Routing Table中把10.4.0.0網段標示為Possibly Down,因為Router B設備會覺得10.4.0.0網段可能很快就好了,或是可能會收到關於10.4.0.0網段的更新資訊,所以此時Router B設備會等候一陣子,在這一陣子期間,允許其他Router設備重新計算對於10.4.0.0網段的路徑,並傳送到Router B設備。這個等候機制稱為Hold-Down Timers。
對於RIP路由協定而言,其Hold-Down Timers所等待的時間是一般定期路由資訊更新時間的三倍,亦即180秒,而IGRP路由協定則是280秒。所以,在Hold-Down Timers的時間之內,Router B設備若收到關於10.4.0.0網段更好的路徑資訊時,Router B設備會接納這樣的路徑資訊,將10.4.0.0網段標示為可到達,並且關閉Hold-Down Timers。但是,如果在Hold-Down Timers時間之內收到比原本更糟的路徑資訊,或是和原本所持有的路徑資訊差不多的話, Router B設備則會忽略所收到的更新資訊。
而在Hold-Down Timers時間之內,當Router B設備收到要送往10.4.0.0網段的網路封包時,Router B設備還是會把這個網路封包送往10.4.0.0網段,因為,此時Router B設備對於10.4.0.0網段還是有信心的。
Triggered Updates
在之前的範例中,之所以會造成路由資訊不一致或是造成路由迴圈(Routing Loop)的情況,都是因為更新速度太慢所導致,因為唯一能收到由其他Router設備所傳過來的路由路徑更新資訊的時機,只有當其他設備的路由資訊定期更新動作啟動,才有辦法收到這些資訊,但總是慢了一步。這個時候,就需要最後一個解決方案—Triggered Updates。
當Router設備的Routing Table產生更新時,就會啟動Triggered Updates,也就是立即將自己的Routing Table向鄰近的設備發出更新的動作,而收到更新的Router設備也會啟動它們的Triggered Updates,所以一旦網路出現任何異常情況,就會在最快的時間之內讓所有的Router設備知道。
剛剛在Hold-Down Timers中曾經提到,在Hold-Down Timers時間之內,可以允許更好的路由資訊來更新自己的Routing Table,所以更需要Triggered Updates來即時送出更新的路由資訊。
訊框中繼網路的問題
訊框中繼網路雖然看起來都還不錯,也廣泛地被使用於廣域網路,但是訊框中繼網路還是有一些缺點——路由更新(Routing Update)的可到達性問題(Reachability Issue)和重複發送廣播封包問題(Broadcast Replication)。
非廣播式多重存取連線
在預設上,訊框中繼網路在遠端設備之間提供「非廣播式多重存取」(Non-broadcast Multi-access,NBMA)的連線類型,非廣播式多重存取連線類型其實和一般的廣播網路環境(如乙太網路)類似,差別只在於所有的路由器都位於同樣的子網路之中。
然而,因為成本的考量,非廣播式多重存取連線網路通常位於Hub-and-spoke網路拓撲之中。但是在這樣的Hub-and-spoke的網路拓撲中,實體拓撲並沒有提供像乙太網路一樣的多重存取功能,也因此,在同一個子網路內,每一個路由器並沒有專門的永久性虛擬線路分別連線到不同的遠端路由器。
因為訊框中繼網路的非廣播式多重存取連線架構,讓訊框中繼網路出現兩個問題:
1.路由更新的到達性問題。
2.當一個實體介面接上多個永久性虛擬線路時,必須重複發送廣播封包。
路由更新的可到達性問題
Distance Vector路由協定中,為了減少路由迴圈(Routing Loop)的問題,衍生出Split Horizon解決方案。如同剛剛所介紹的,但是在訊框中繼網路之中,Split Horizon卻衍生出其他的問題,這也就是為什麼剛剛要介紹Distance Vector路由協定的Split Horizon解決方案。
在訊框中繼網路的Hub-and-spoke的網路架構中,遠端的路由器(Poke端路由器)會發送路由更新給主要的路由器(Headquarter端路由器),而這個主要的Headquarter端路由器會透過同一個實體的介面來建立出很多不同條的永久性虛擬線路。
在這樣的環境內,若這台Headquarter端路由器由這個實體介面收到廣播封包(也就是路由更新),卻不能轉發這個路由更新封包透過同一個介面轉發給其他不同的遠端路由器(Spoke路由器),將造成無法傳送路由更新出去的問題。但如果Headquarter端路由器的每一個實體介面都只有建立一個永久性虛擬線路的話,就不會有這種路由更新的問題。
重複發送廣播封包問題
這個問題的發生環境和上一個問題相同,但是不同的是,如果要解決上面的問題,就會衍生出這個問題。就是因為主要的Headquarter端路由器會透過同一個實體的介面來建立出很多不同的永久性虛擬線路,所以一旦收到廣播封包,如果打算把這樣的廣播封包真的傳送到不同的永久性虛擬線路的話,那這些廣播封包就會耗盡大量的網路頻寬,而造成網路嚴重延遲。
可到達性問題的解決方案
現在,開始介紹所有可能的解決方案。這些解決方案包含關閉Split Horizon機制、使用全狀拓撲網路架構和使用子介面來模擬點對點的網路運作型態。其中,每一種的做法各有好壞,以下就一一作分析。
關閉Split Horizon
因為路由更新的可到達性問題都是因為Split Horizon所引起的,所以其中一種解決的方法就是把Split Horizon機制關閉,不過,如果把Split Horizon機制關閉,可能有兩種問題會發生。第一個可能的問題是,把Split Horizon機制關閉,Split Horizon所要解決的路由迴圈(Routing Loop)問題又會重新發生。另外第二個問題是,不見得所有的網路都可以關閉Split Horizon機制,必須考慮到各種網路架構的解決方案。
使用全狀拓撲網路架構
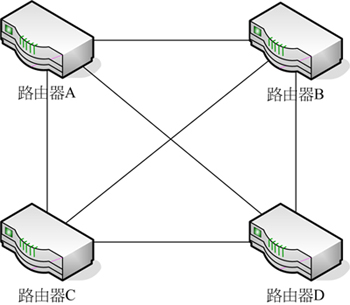
所以,最好考慮其他的解決方案來解決訊框中繼網路的路由更新可到達性問題。另一種解決方案就是維持使用Split Horizon機制,但是卻使用全狀拓撲(Full Mesh Topology)。這種網路拓撲架構,顧名思義就是每一台路由器與其他各個路由器都有永久性虛擬線路(PVC)的連線,如下圖所示。
 |
| ▲全狀拓撲 |
由上圖可以看出,這種網路拓撲架構需要架設的永久性虛擬線路數目最多,因此成本也最高。但是,也因為由一個路由器到另一個路由器的路徑不只一條,所以當某條網路路徑發生問題,路由器依然可以透過其他路徑傳送網路封包給目的端的路由器。
這種網路拓撲要注意的是,若增加一台新的路由器設備,則要多建立N-1條永久性虛擬線路(N是全部的路由器數目),而總共的永久性虛擬線路的數目會變成n ( n - 1) / 2個。
舉例來說,如果有20台路由器設備要使用這種網路拓撲結構,則必須架構190條永久性虛擬線路,但如果使用星狀網路拓撲結構,就只需要N–1條,亦即19條永久性虛擬線路就可以,兩者之間的成本就相差了十倍以上!因此,使用全狀拓撲網路架構時必須把成本加入考量。但是至少比剛剛第一個解決方案好一點,至少用錢就可以解決所有的問題,而且不會衍生出其他的問題。
使用子介面
如果不想衍生出其他的問題,也不想耗費太多成本的話,另外還有一個解決方案,那就是使用子介面(Sub-interface)。這種做法就是在訊框中繼的Hub-and-spoken的網路拓撲中啟動路由更新廣播封包的轉發功能(Forwarding)。
若要使用這樣的解決方案,必須在Hub路由器上設定子介面,而這些子介面實際上是實體介面的分支。如此一來,即使在Split Horizon的網路環境中,當一個子介面收到路由更新的封包之後,就會轉送到另一個子介面並且轉發出去。而在這種子介面的環境內,每一個虛擬線路都可以設定成點對點(Point-to-point)的連線型態。設定成點對點的連線型態後,就可以模擬成專線(Leased line)的運作模式。Leased Line是其中一種廣域網路的連線種類,就是所謂的Point-to-point或是Dedicated的連線,說穿了,它就是固定的電路,也就是專線,如下頁圖所示。
 |
| ▲Leased Line運作模式 |
這種做法的優點是可以保證頻寬,而且這頻寬是獨享的,不會與其他網路共享。不過,缺點是花費太高,因為是專線,所以成本相對地非常高。而在速度上,則可以到達45Mbps。不過,這裡使用模擬的方式讓子介面運作得像是Leased line一樣,所以相對地成本就沒有實體Leased line那麼高了。而像這裡所描述的,在訊框中繼網路中使用點對點的子介面,則每一對使用子介面的路由器,都是在屬於自己的子網路之中。
結語
在這篇文章之中,筆者為各位介紹了訊框中繼網路所可能帶來的網路問題,並且分析出幾種不同的解決方案。
綜合來看,第一種「關閉Split Horizon」解決方案的代價太高,因為它引發原本的路由迴圈問題,優點是設定簡單,但是無疑是走回頭路,並不是一個好的解決方式。
而第二種「使用全狀拓撲網路架構」解決方案,雖然已經比第一種還好,因為不會有路由迴圈的問題,但卻因為網路拓撲的改變而讓建構成本大量增加,對於一般企業而言,這種方式使用之前還是值得三思。最後的「使用子介面」解決方案,無疑地成本比第二種低,也不會有第一種解決方案所帶來的副作用,不過設定上有點複雜,但是整體看來,這才是最好的解決方式。