過去十年來,AI模型的複雜程度及運算能力快速成長,自2023年起,AI的發展重點也轉向效率及生成式AI的廣泛應用,因此靈巧模型(Nimble AI)應運而生。本篇文章將介紹Nimble AI一詞,並說明Nimble AI為什麼會成為大規模部署生成式AI的主要方法。
生成式AI的重大突破解鎖了許多AI應用的新場景,例如AI代理人能以簡明語言與使用者對話、總結及生成引人入勝的文字內容、創作影音、利用先前迭代的上下文資訊等等。本篇文章將介紹Nimble AI一詞,並說明Nimble AI為什麼會成為大規模部署生成式AI的主要方法。簡而言之,Nimble AI模型的執行速度能在更快、更短的時間內透過微調不斷更新,且更易於透過開源社群的集體創新加快技術改進週期。
過去十年來,AI模型的複雜程度及運算能力快速成長,自2023年起,AI的發展重點也轉向效率及生成式AI的廣泛應用。因此,靈巧模型(又稱Nimble AI)應運而生,尤其是針對特定領域所打造,參數少於150億,卻具有可與ChatGPT式巨型模型(參數超過1,000億)媲美的功能。雖然生成式AI已在各行各業中廣泛部署應用,但小巧且高度智慧模型的使用頻率仍不斷增加。在未來,少數的巨型模型,與大量的小型Nimble AI模型將成為應用趨勢。
雖然大型模型的發展已有長足進步,但就訓練和環境成本而言,大並不等於美。據市場研究機構集邦科技(TrendForce)估計,ChatGPT光是GPT-4的訓練成本就超過1億美元,相較之下,靈巧模型的預訓練成本就遠低了許多(例如MosaicML的MPT-7B報價約為20萬美元)。大多數的運算成本都在連續推論的期間產生,對於任何規模的模型而言皆是一大挑戰,包含運算成本昂貴的大型模型來說也是如此。此外,將巨型模型交由第三方環境託管也會帶來安全和隱私方面的挑戰。
相形之下,靈巧模型的執行成本就遠低得多,並能提供許多額外優勢,如適應性、硬體靈活性、安全性和隱私性、可解釋性且可整合於大型應用程式中(圖1)。過去普遍認為小型模型效能不及大型模型的看法也正在改變。小規模且針對特定領域打造的小型模型在商業、消費者和科學領域就能提供同等甚至更佳的效能,不只增加價值,同時也減少投入時間和成本。
 圖1 靈巧生成式AI模型的優勢。(圖片來源:Intel Labs)
圖1 靈巧生成式AI模型的優勢。(圖片來源:Intel Labs)
可以在效能上和ChatGPT-3.5等級的巨型模型媲美的靈巧模型越來越多,且效能及規模仍持續快速改進中。此外,如果靈巧模型能搭配上即時搜尋特定領域私人數據的功能,並可根據查詢內容檢索特定網路的內容,會比需要記錄廣泛記憶數據集的巨型模型更加準確且更具經濟效益。
隨著靈巧開源的生成式AI模型持續開發,進而帶動相關領域的快速發展,如同開創革命性技術成為主流的iPhone面對Android的挑戰,因為研究和開發人員以彼此為開源所付出的努力為基礎,組成了強大社群,打造出效能越來越強大的靈巧模型。
思考、執行、理解:針對特定領域的靈巧模型媲美巨型模型
欲進一步瞭解何時及如何使用小型模型,才能夠大幅提升生成式AI的競爭力,必須先明白無論是靈巧生成式AI模型還是巨型生成式AI模型,皆需要三大類能力才能運作(圖2):
 圖2 生成式AI能力分類。(圖片來源:Intel Labs)
圖2 生成式AI能力分類。(圖片來源:Intel Labs)
1. 思考認知能力:語言理解、總結、推理、計畫、經驗學習、長篇表述和互動對話。
2. 執行所需的功能性技能:場景文字閱讀、圖表閱讀、視覺辨識、程式設計(編碼和偵錯)、圖像生成和語音能力。
3. 需理解的資訊(記憶或檢索):網路內容,包括社群媒體、新聞、研究和其他一般內容或特別篩選的特定領域內容,如醫療、金融和企業數據。
思考認知能力
基於認知能力,模型可以「思考」和理解、總結、綜述、推理並創作語言和其他符號表現。無論是靈巧模型還是巨型模型,在這些認知任務中皆能有良好表現,至於這些核心功能是否需要巨型模型規模,目前尚未有定論。舉例來說,微軟研究院所開發的靈巧模型(如Orca)所展現出的理解、邏輯和推理能力在多個基準測試中已媲美甚至超越ChatGPT。此外,Orca也顯示了推理技能能夠以大型模型做為學習對象,從大型模型中汲取出來。然而,目前用於評估模型認知技能的基準仍相當基礎,尚須進一步研究和基準測試來驗證靈巧模型可透過預訓練或微調,達到完全媲美巨型模型「思考」優勢的程度。
執行所需的功能性技能
鑑於大型模型普遍強調其為一站式模型,越大規模的模型通常具備越多功能性技能和資訊。然而,對大多數的商業用途來說,任何應用的部署皆需特定範圍的功能性技能。商業應用中使用的模型應具有靈活性,以及可成長及演變的空間,但通常不需要不受限的功能性技能。GPT-4可生成多種語言的文字、程式碼和圖片,但會說上百種語言並不代表這些巨型模型本身擁有較高的基礎認知能力,而只是提供模型更全面的功能來「執行」更多任務。
此外,也可將生成式AI模型與功能專業化引擎相連,以在需要時使用特定功能,例如以模組化方式為ChatGPT增添「Wolfram超能力」,即可獲得首屈一指的運算功能,卻不會為模型帶來不必要的規模負擔(圖3)。舉例來說,GPT-4正積極部署利用小型模型的外掛程式以增添附加功能。為了達到功能和模型效率的最佳組合,未來的多功能模型很有可能採用更小巧、集中的專家組合模型,且每個模型的參數皆小於150億。
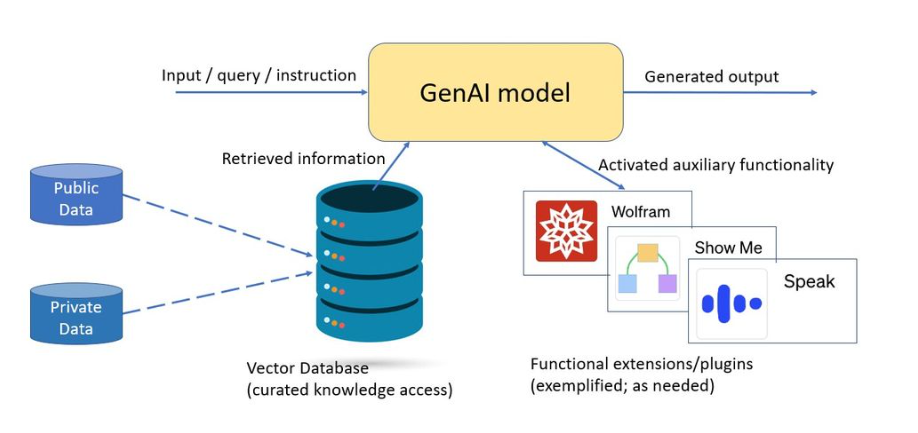 圖3 以檢索為基礎的功能擴展模型可提供廣泛功能和相關資訊,與模型大小無太大關聯。(圖片來源:Intel Labs)
圖3 以檢索為基礎的功能擴展模型可提供廣泛功能和相關資訊,與模型大小無太大關聯。(圖片來源:Intel Labs)
需瞭解的資訊(記憶或檢索)
巨型模型透過在參數記憶體中儲存大量數據來「理解」更多資訊,但這並不一定會讓模型更聰明,只是普遍會比小型模型具有更多知識。巨型模型在全新使用案例的零樣本環境中能發揮高度價值,在無特定針對領域時能提供一般的消費者基礎,並可作為學習模型來汲取和微調如Orca這類的靈巧模型。相較之下,具針對性的靈巧模型則可根據特定領域進行訓練和微調,為所需能力提供更專精的技能。
舉例來說,針對程式設計的模型可著重在有別於醫療保健AI系統的功能。此外,對經過編審的一組內部和外部數據進行檢索,可以大幅提升模型的準確性和及時性。近期一項研究顯示,在PopQA基準測試中,參數僅有13億、具檢索功能的模型在效能上可與規模較其大上百倍的模型(參數達1,750億)相匹敵(圖4)。
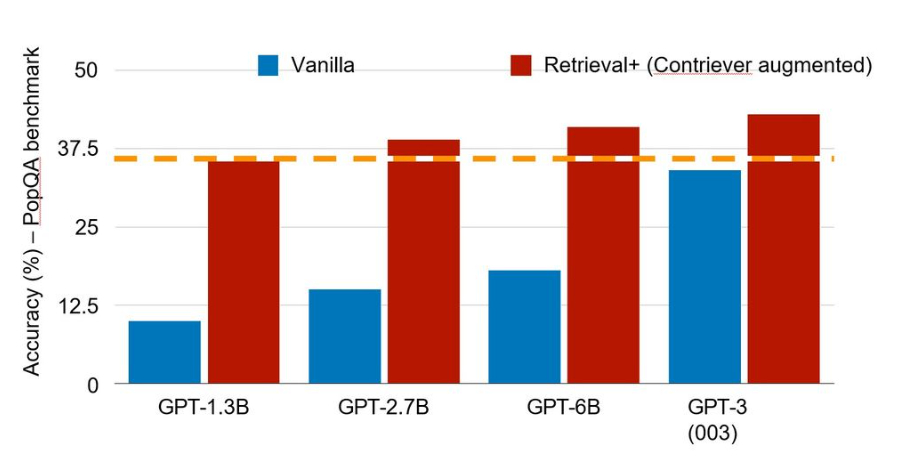 圖4 檢索的價值在於讓小型模型可與大型模型媲美(使用Contriever檢索方法)。 (圖片來源:Intel Labs,參考Mallen等人的研究)
圖4 檢索的價值在於讓小型模型可與大型模型媲美(使用Contriever檢索方法)。 (圖片來源:Intel Labs,參考Mallen等人的研究)
因此,具有高品質索引可存取數據的針對性系統,可能較一站式通用系統具備更廣泛的相關知識。這對大多數企業的應用來說可能更顯重要,因為企業需要的是特定案例或應用的數據,且在多數情況下,精準的本地知識比大量的一般知識更重要。這正是靈巧模型的關鍵價值。
靈巧模型爆炸式成長的三大因素
在評估靈巧模型的優點和價值時,須考量以下三大因素:
1. 在適當模型規模下達到高效率。
2. 開源或專有授權
3. �模型專業化,可分為通用型或針對性模型(包括檢索功能)。
就規模而言,無論是靈巧通用模型(如Meta的LLaMA-7B和LLaMA-13B,或阿布達比科技創新研究所的Falcon 7B開源模型),還是專有模型(如MosaicML的MPT-7B、微軟研究院的Orca-13B和Salesforce AI Research的XGen-7B),皆在迅速發展當中。選擇效能高、規模小的模型對營運成本以及運算環境具有重大影響。ChatGPT的模型參數達1,750億,據估計,GPT-4的參數高達1.8兆,因此需要安裝大量加速器(如具足夠運算能力的GPU)才能進行訓練和微調。
相較之下,靈巧模型通常可以在任意的硬體上執行推論,包括單插槽CPU、入門級GPU和最大型加速器。根據130億參數規模或規模更小的模型達成出色的結果,目前靈巧AI定義的參數上限為150億。總體而言,靈巧模型提供更具成本效益,且具備可擴大規模的新方法來處理新的使用案例(見靈巧模型的優缺點)。
第二項因素--開源授權讓大學和企業可以迭代模型,進而推動創意創新的蓬勃發展。透過開源模型,小型模型在能力上的進展令人矚目(圖5)。
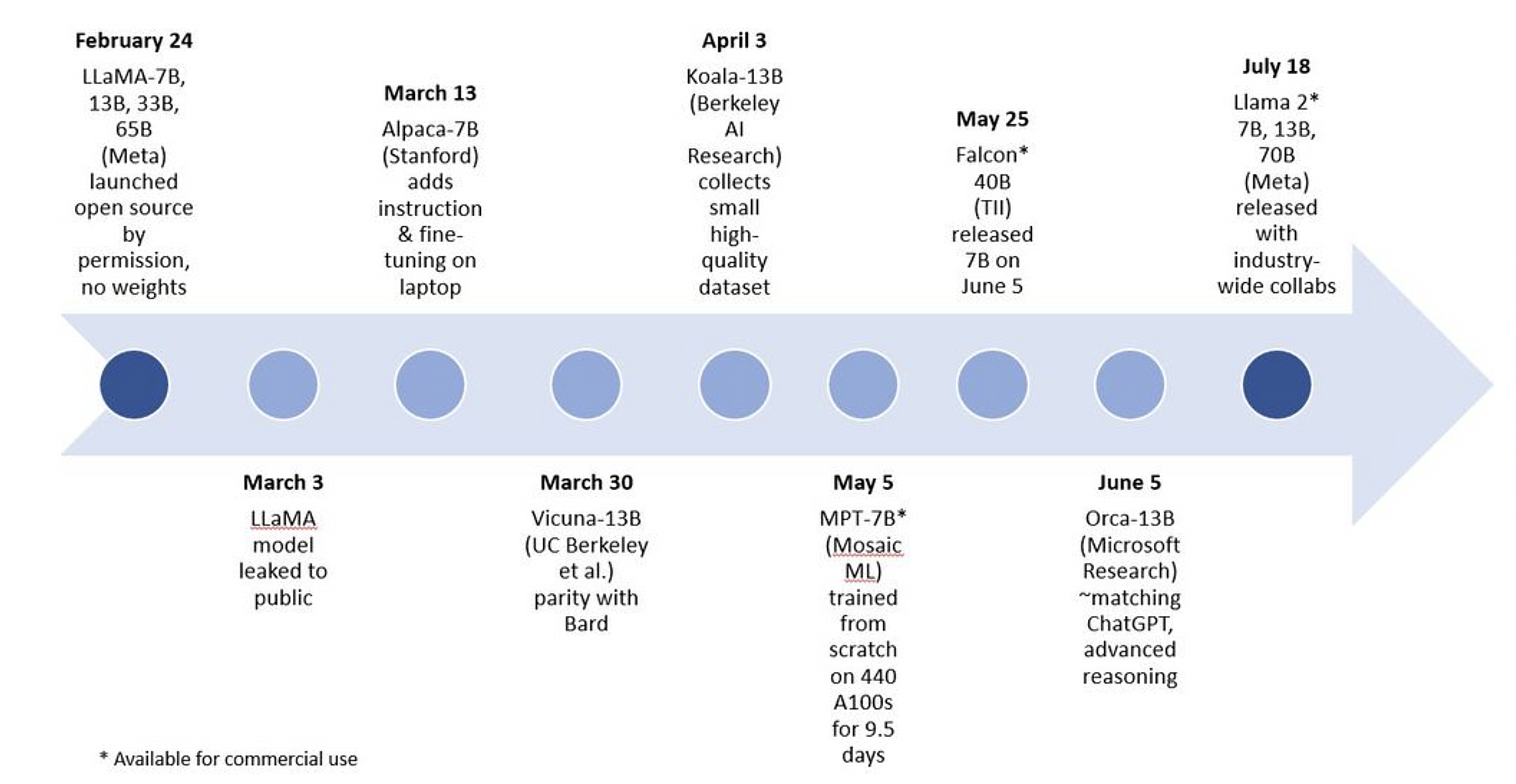 圖5 靈巧開源非商業及商業的生成式AI模型於2023年上半年的突破性進展。(圖片來源:Intel Labs)
圖5 靈巧開源非商業及商業的生成式AI模型於2023年上半年的突破性進展。(圖片來源:Intel Labs)
自2023年初開始,便可見諸多通用靈巧生成式AI模型的例子,首先是Meta的LLaMA,擁有70億、130億、330億和650億參數規模的模型。透過微調LLaMA所建立、參數範圍介於70至130億的模型則包括:史丹佛大學的Alpaca、柏克萊AI研究室的Koala以及加州大學柏克萊分校、卡內基梅隆大學、史丹佛大學、加州大學聖地牙哥分校和MBZUAI的研究人員共同打造的Vicuna。
最近,微軟研究院發表了一篇以尚未發布的Orca為題的論文,Orca是一個基於LLaMA、具130億參數規模的模型,其模仿巨型模型的推理過程,在尚未針對特定領域或微調之前,即已展現出令人印象深刻的結果。
Vicuna是在近期以LLaMA為基礎模型衍生而來的開源靈巧模型中很好的例子。Vicuna-13B是一個由大學合作打造的聊天機器人,其開發宗旨為「解決現有模型(如ChatGPT)缺乏訓練和基礎架構細節的問題」。在對ShareGPT的使用者共享對話進行微調後,Vicuna的回應品質與ChatGPT和Google Bard相比,提升了90%以上(以GPT-4作為評判標準)(圖6)。然而,這些早期的開源模型並不能用於商業用途。據稱,MosaicML的MPT-7B和阿布達比科技創新研究所的Falcon 7B商業可用開源模型在品質上與LLaMA-7B旗鼓相當。
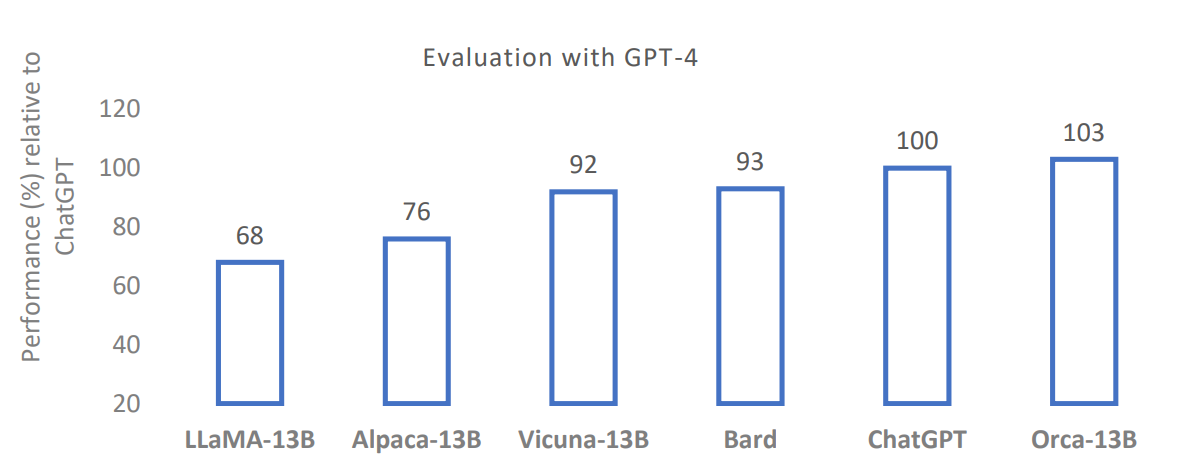 圖6 GPT-4評估開源聊天機器人的相對回應品質比較(使用Vicuna評估標準)。(圖片來源:微軟研究院)
圖6 GPT-4評估開源聊天機器人的相對回應品質比較(使用Vicuna評估標準)。(圖片來源:微軟研究院)
研究人員表示,Orca在Big-Bench Hard(BBH)等複雜的零樣本推理基準測試中,超過Vicuna-13B等傳統指令調整模型100%以上,在BBH基準上,其與ChatGPT-3.5不相上下(圖7)。相較於其他通用模型,Orca-13B展現出高度卓越的效能,這也強化了「巨型模型的規模可能源於早期的蠻力模型」的看法。對於一些規模較小的模型(如Orca-13B)來說,巨型基礎模型的規模在汲取知識的方法上至關重要,但並非推論的必要條件。須注意的是,只有廣泛部署和執行模型,才能對模型的認知能力、功能性技能和知識記憶進行全方面的評估。
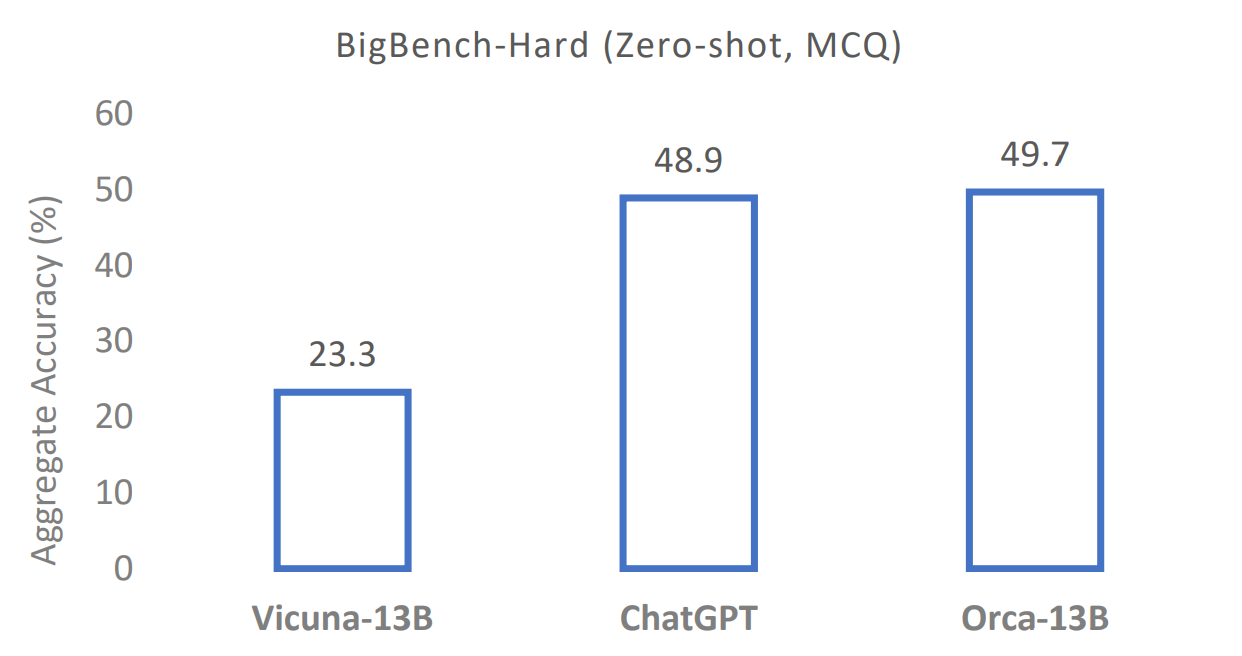 圖7 Orca-13B在BIG-bench Hard的複雜零樣本推理任務上的表現媲美ChatGPT。(圖片來源:微軟研究院)
圖7 Orca-13B在BIG-bench Hard的複雜零樣本推理任務上的表現媲美ChatGPT。(圖片來源:微軟研究院)
截至2023年7月為止,Meta發布了70億、130億和700億三種參數規模的Llama 2模型。Llama 2 13B的靈巧模型與上一代LLaMA規模較大的模型以及MPT-30B和Falcon 40B有相似的表現。Llama 2為開源模型,可免費用於研究和商業用途,由微軟以及英特爾等眾多合作夥伴攜手打造。Meta致力於推動開源模型及建立廣泛合作,這將進一步加快開源模型跨產業與學術界的改進週期。
靈巧模型的第三項要素為專業化。許多新推出的靈巧模型都是通用模型,例如LLaMA、Vicuna和Orca。一般的靈巧模型可以只依賴參數記憶,透過微調方式進行低成本更新,使用方法包括LoRA(Low-Rank Adaptation of Large Language Models)以及檢索增強生成(Retrieval-augmented Generation),後者可在推論過程中從篩選的語料庫中即時提取相關知識。
隨著LangChain和Haystack等生成式AI框架的持續發展,檢索增強解決方案也逐漸成熟與精進。透過這些框架,模型可以輕鬆且靈活地整合索引,並有效地存取大型語義資料庫以進行基於語義的檢索。
多數商業用戶偏好採用針對其特定關注領域進行調整的針對性模型。這些針對性模型通常以檢索為基礎,利用所有關鍵資訊資產。例如,醫療保健使用者可能希望實現病患溝通自動化。
針對性模型的建立,有以下兩種方式:
1.根據特定使用案例所需的任務和數據類型對模型本身進行專業化(Specialization),可操作的方法有很多種,包括根據特定領域知識預訓練模型(例如phi-1以網路上的教科書品質數據進行預訓練)、微調相同規模的通用基礎模型(例如Clinical Camel對LLaMA-13B進行微調),或者以巨型模型做為學習對象以建立靈巧模型(例如Orca學習及模仿GPT-4的推理過程,包括解釋追蹤、過程思考及其他複雜指令)。
2. 篩選及索引相關數據以便即時檢索,數據量可能很大,但仍在特定使用案例的可行範圍與空間之內。模型可以檢索不斷更新的公共網路、消費者或企業內容。使用者可決定要對哪些資料來源進行索引,進而可選擇網路上的高品質資源及更完整的資源,例如個人的私人數據或公司的企業數據。雖然檢索功能現已整合至巨型及靈巧系統中,但由於小型模型可提供攸關模型效能的必要資訊,這項功能仍至關重要。此外,這個方法也讓企業可將所有私人和本地資訊提供給在其運算環境中執行的靈巧模型。
靈巧生成式AI模型的優缺點
未來小巧模型的參數規模可能發展至200億或250億,仍遠低於1,000億的參數範圍。同時,雖然目前有各種中等規模的模型,如MPT-30B、Falcon 40B和Llama 2 70B,且市場普遍預期中等模型在零樣本提示狀況下比小型模型有更好的效能,但個人認為在特定功能方面,中等模型的表現未必會優於靈巧、針對性且基於檢索的模型。
與巨型模型相比,靈巧模型有許多優勢,若是針對性和基於檢索的模型,這些優勢會更加顯著。靈巧模型的優勢包括:
永續且低成本
靈巧模型的訓練和推論運算成本遠低於巨型模型。推論執行時的運算成本是業務導向模型能否整合至全天候使用的決定性因素。此外,在廣泛部署的情況下,整體大幅降低的環境影響也相當重要。最後,靈巧模型為永續、特定及功能導向的系統,由於並非以實現通用AI(Artificial General Intelligence)作為遠大目標,因此也較少捲入與AGI相關的公眾及監管爭議。
微調迭代更快速
小型模型可在幾個小時內(或更短的時間內)完成微調,可透過LoRA等調適方法(Adaptation Methods)為模型增加新資訊或功能,此方法相當適用於靈巧模型。藉此,可讓改進週期更為頻繁,以持續更新模型以滿足使用需求。
基於檢索模型之優勢
檢索系統會對知識進行重構,引用直接來源的大部分資訊,而非模型參數帶有的記憶(Parametric Memory)。這有助於改善以下面向:
‧可解釋性:檢索模型使用來源歸因(Source Attribution)來提供出處或追溯資訊來源,進而提升可信度。
‧及時性:一旦某最新數據來源被編入索引,模型即可立刻使用,無須任何訓練或微調,這使模型得以近乎即時地連續新增或更新相關資訊。
‧精準資料範圍:按需求檢索的索引資訊可非常廣泛且詳細。如針對特定目標領域檢索,模型所涵蓋的私人及公共數據既深且廣,在其特定目標範圍內,甚至可提供較巨型基礎模型訓練數據集更大量且細緻的數據。
‧準確性:直接存取原始數據,包括其形式、細節和上下文,此有助於減少幻覺(Hallucination)和數據近似。只要在檢索範圍內,模型就能提供可靠且完整的答案。對於較小的模型,根據需求檢索的可追蹤篩選資訊與記憶資訊(如在巨型模型中)之間的衝突也較少,因為記憶資訊可能過時、片面或來源不明。
硬體選擇
靈巧模型的推論基本上在任何硬體上皆可進行,包括可能已成為運算環境一部分的全方位解決方案。舉例來說,Meta的Llama 2靈巧模型(參數70億和130億)在英特爾的資料中心產品(包括Xeon、Gaudi2和Intel Data Center GPU Max系列)上皆執行良好。
整合、安全和隱私
目前的ChatGPT和其他巨型生成式AI模型皆為獨立模型,通常在第三方平台上的大型加速器上執行,並透過介面存取。Nimble AI模型可以作為引擎,嵌入大型的業務應用程式中執行,並可完全整合至本地運算環境中。由於不須與第三方模型和運算環境交換或暴露資訊,能大幅提升安全和隱私。此外,所有安全機制都可以應用於生成式AI引擎。
最佳化和模型降維
最佳化和模型降維技術透過將輸入值轉換為較小的輸出值來減少運算需求,這項技術使靈巧模型的功率效率有所提升。
詳細內容請見:https://community.intel.com/t5/Blogs/Tech-Innovation/Artificial-Intelligence-AI/Survival-of-the-Fittest-Compact-Generative-AI-Models-Are-the/post/1508220
<本文作者:王宗業,美商英特爾公司網路暨邊緣運算事業群平台研發協理,負責Intel Edge AI平台生態系統的推廣,帶領過智慧零售、智慧製造、智慧交通與智慧醫療等專案的開發。在20多年的軟硬體開發、推廣、客戶支援經驗中,含括嵌入式系統、智慧型手機、物聯網、Linux及開源軟體、AI硬體加速器在影像與自然語言處理等領域,並擔任過台灣人工智慧學校經理人班、技術領袖班與Edge AI專班的講師,以及大專院校的深度學習課程業師。>