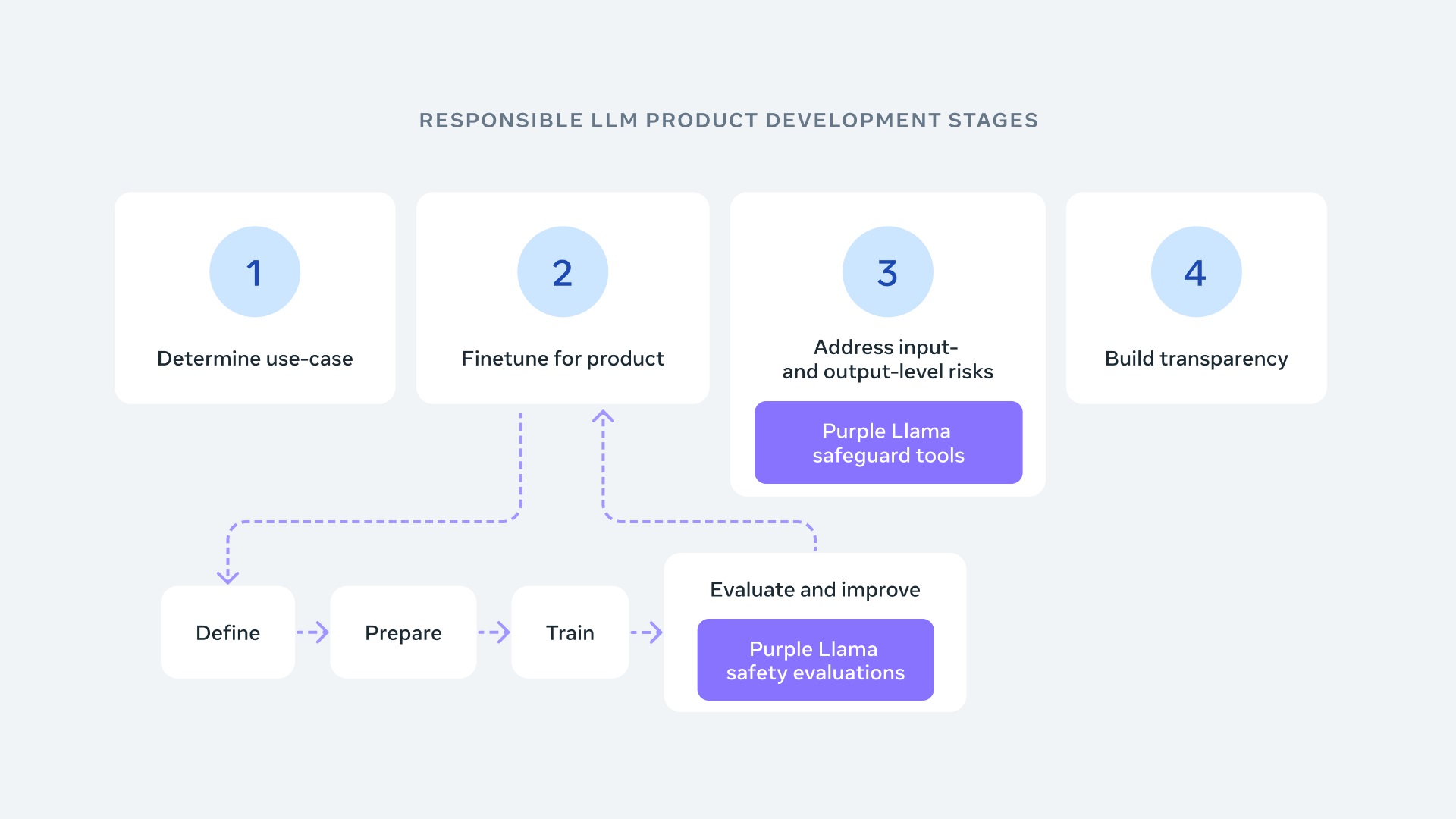
許多AI創新內容都是建立在開放模型之上,Meta的Llama模型下載數量也突破1億次!在這波創新中,為了建立對開發者的信任,Meta推出Purple Llama,該項保護傘計畫將匯集各類評測方式與工具,幫助開發者負責任地運用開放的生成式AI模型建構。
引用資安領域的概念,為了應對生成式AI帶來的挑戰,需要同時模擬攻擊(紅隊)與防禦(藍隊)的模式,紫隊便是由紅隊及藍隊協作組成,同時考量評估風險與減輕潛在威脅的作法。
Meta推出業界第一套針對大型語言模型的網路安全評測工具,這些標準是基於產業指南及規範,並與Meta的安全專家合作建構而成。透過Purple Llama的初始版本,期待提供工具應對向白宮做出的安全承諾中概述的風險,包括:
- 量化大型語言模型網路安全風險的指標。
- 評估不安全程式碼建議發生頻率的工具。
- 評估使大型語言模型難以產生惡意程式碼或協助網路攻擊的工具。
相信透過這些工具,可從本質上減少由大型語言模型建議出不安全生成式AI程式碼的頻率,並減少對網路上攻擊者的幫助。
如Llama 2負責任使用指南中所述,Meta建議開發者根據適合的內容規範,檢查及過濾大型語言模型的所有輸入及輸出內容。為了支持開發者執行此流程,Meta發布 Llama Guard,此項公開可用的基礎模型幫助開發者避免產出具潛在風險的輸出。為持續實現公開、透明的科學研究精神,Meta將在論文中公開研究方法及對結果的延伸討論。此模型已經過一系列公開可用的資料集訓練,能夠檢測常見的潛在風險或違規內容,最終期待開發者能根據各自需求自行調整合適的內容,支援相關使用狀況,並更輕鬆地採用最佳作法,進而改善整個開放生態系。
 Meta 推出 Purple Llama 實現安全及負責任的 AI 開發。
Meta 推出 Purple Llama 實現安全及負責任的 AI 開發。