專攻於IT基礎架構中蒐集並處理「機器資料」的Splunk,隨著製造業力求轉型,試圖藉由改善製程良率來提升核心競爭力,如今也涉足從未思考過的IC製造、封裝測試、設計等領域。
Splunk台灣區資深技術顧問陳哲閎指出,自2006年Splunk創立時,即是基於搜尋引擎技術發展,原先目的是為了協助網管人員,統合基礎架構中的所有資料,進而追蹤問題。
「近來在韓國的製造業客戶應用案例發現,Splunk不僅可協助IT維運、資安分析,亦可整合至半導體製程、封裝測試、IC設計等應用,借助Splunk平台的機器學習(Machine Learning)引擎之力,快速地彙總、整理、分析非結構化資料,再以搜尋引擎查詢方式,透過關鍵字抓取特定時間、機器、產出的資料,完全不需仰賴資料庫。」陳哲閎說。
以半導體製程而言,從晶圓、光罩、封裝、測試,到最後出廠的晶片,不同環節的產線機台均會產生半結構化格式的資料,過去多數是匯入至關聯式資料庫,必須依據欄位擷取相對應的值,再透過商業智慧軟體產出視覺化的報表。當時該半導體廠考量資料庫與分析軟體的建置成本過高,曾經改以Hadoop來取代,但資料處理速度始終不盡理想,只好放棄專案的進程。最後則是利用Splunk介接TIBCO Rendezvous(RV)中介軟體,蒐集來自十?六條產線的資料,Splunk搜尋引擎技術則依據事前定義近三百種告警規則自動搜尋,一旦發現符合條件者即刻發出通知產線管理者,以免未發現製程錯誤導致重工。陳哲閎表示,該韓國客戶因為Splunk協助提升2%的良率、機器問題少10%、機台管理的工作效率提升50%、晶圓成本下降5%。
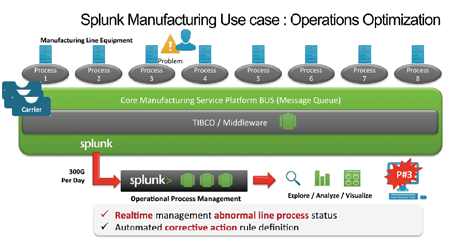 |
| ▲Splunk協助韓國半導體製造廠即時分析產線資料,提升製程良率。(資料來源:Splunk) |
Splunk技術運行架構不採用資料庫,資料蒐集後可立即進行搜尋與分析,以視覺化圖形介面呈現。「主要是仰賴MapReduce核心技術,類似於Hadoop,但Splunk強調的是即時性,Hadoop則是批次處理為主。」陳哲閎說。「確實有製造業客戶是建構Hadoop平台來協助,才發現在即時資料處理方面的限制,來自於資料蒐集過程不夠快,畢竟仍舊得仰賴HBase轉換成結構化的資料。客戶發現Hadoop速度不夠快後,於是將HBase轉為In-Memory技術處理,試圖提升整體速度,但終究是資料庫思維架構,無法避免受限。」
他進一步說明,由於資料庫的特性是「Schema-on-Write」,必須依據規範載入資料。若為批次處理與分析資料的應用模式,關聯式資料庫的確游刃有餘,但生產線的資訊分析必須為即時,就必須由Splunk這類「Schema-on-Read」,在執行查詢讀取時才驗證Schema的資料處理,以加快反應速度。
此外,未來在物聯網的發展下,不論感測器回報的資料格式是否固定,只要是明文,即可經Splunk統整,以辨識感測器的廠牌與用途、取得參數值的定義,並且可進一步設定當數值超過臨界值後,自動觸發執行的動作。由此亦可知其實資料控管的概念各行業都類似,只是應用情境不同而已。