網路服務若想不中斷地服務用戶,必須具備高可用性(HA)。可建立一個叢集架構,善用多台服務主機串連來做即時備援。本文介紹的Heartbeat能夠即時監測叢集上的主節點,若發現主節點服務異常,就會啟動接管程序,即時接手主節點的服務。
身為系統管理者,總是希望自己所掌管的網路服務能夠具有高可用性(High Availability,HA)的特質,可以長年不中斷地服務用戶。為了達成這樣的目標,通常會建立一個叢集(Cluster)架構,利用多台服務主機串連的方式來完成即時備援的功能。
在平常的時候,僅會由一台主要服務主機(Primary,可稱為主節點)進行網路服務,而另一台服務主機則當成備援主機(Secondary,可稱為備用節點),備援主機在平常時並不進行網路服務,而是即時監測主節點。
一旦發現主節點服務發生異常時(例如不正常的關機)就會即時地接管(Takeover)主節點的服務,讓使用者感覺不到網路服務曾經發生異常。
為了能夠無縫接軌地接替主節點的服務,除了各個節點上的資料必須同步更新並保持一致外(前幾期介紹的DRBD軟體就是利用網路同步的方式來保持各個節點上資料的一致),還可以使用本文所要介紹的Heartbeat軟體來即時監測叢集上的主節點,一旦發現主節點服務發生異常,便會即時地啟動接管程序來接管主節點的服務。接下來的實作示範,將採用CentOS 7作業系統。
認識Heartbeat
從1999年開始,Linux就開始致力於高可用性(HA)的應用,其中最有名的組織是Linux-HA(其官方網址為http://linux-ha.org/),而Heartbeat就是該組織所開發維護的HA軟體。
Heartbeat主要是擔任偵測及接管主節點網路服務的工作。在平常的時候,Heartbeat以傳送偵測封包的方式來確認對方主機是否還存活,就像監聽心跳一樣,故命名為Heartbeat。如果在指定的時間內未收到對方的回覆,便會認定對方主機已失效,此時Heartbeat就會啟動接管對方主機網路服務的程序。在此簡單的說明一下Heartbeat的接管動作,如圖1所示為常見的叢集架構。
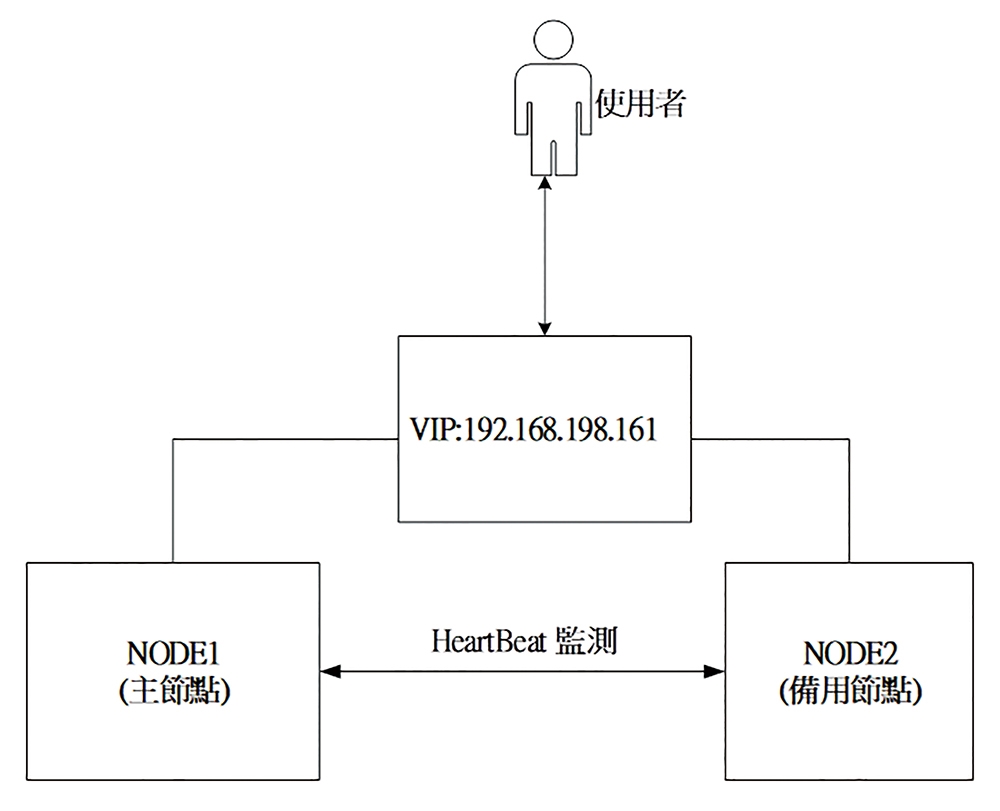 圖1 常見的叢集架構。
圖1 常見的叢集架構。
當Heartbeat服務啟動時,會在主節點上產生一組虛擬網路卡介面(以下簡稱為VIP),而後外部使用者並不會直接利用主節點的IP來存取網路服務,而是利用VIP來存取網路服務。一旦主節點發生異常而由備用節點接管時,備用節點便利用產生VIP來取代主節點,並執行使用者所設定的程序(通常是用來啟動某個網路服務)。如果能夠即時地切換,對於外部使用者而言,並不會感覺到網路服務有任何的異樣。
如果以傳遞偵測封包的介質來區分,Heartbeat提供了串列接口和網路的方式來傳遞偵測封包。由於串列接口的方式較不常見,因此本文只討論以網路方式來傳遞偵測封包。
Heartbeat提供了廣播(Broadcast)、群播(Multicast)以及單點傳播(Unicast)的網路傳遞方式,以下簡單說明此三種傳播方式:
廣播(Broadcast)
當傳送端欲傳送封包給接收端某個主機時,並不會直接將封包傳遞至該主機,而是先利用廣播的方式將封包廣播至該網段,再由該網段的主機在接收封包後,自行判斷是否為屬於自己的封包。如果答案為肯定的話,就接收此封包並進行處理,否則即放行該封包,其相關架構圖如圖2所示。
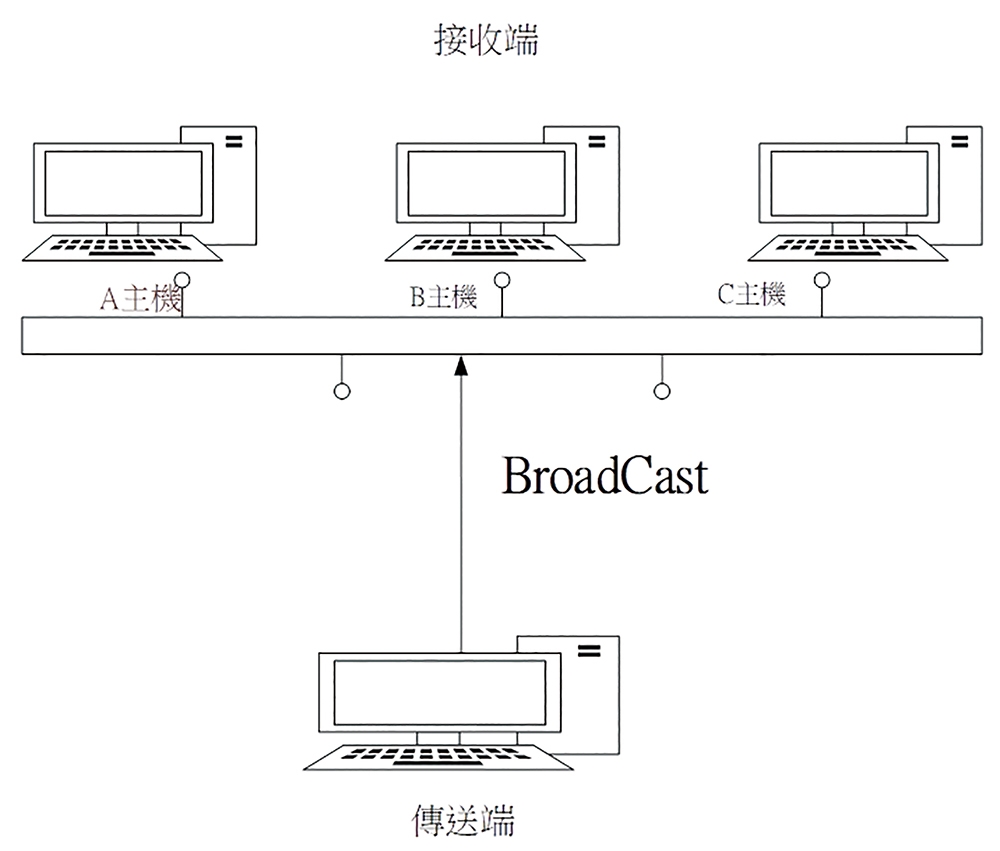 圖2 廣播(Broadcast)運作示意圖。
圖2 廣播(Broadcast)運作示意圖。
群播(Multicast)
相對於廣播的方式,群播則是將同一個網段上的主機分群(稱為Multicast Group),當傳送端傳送資料時,只會將封包傳遞至目的群組的主機上,如圖3所示。
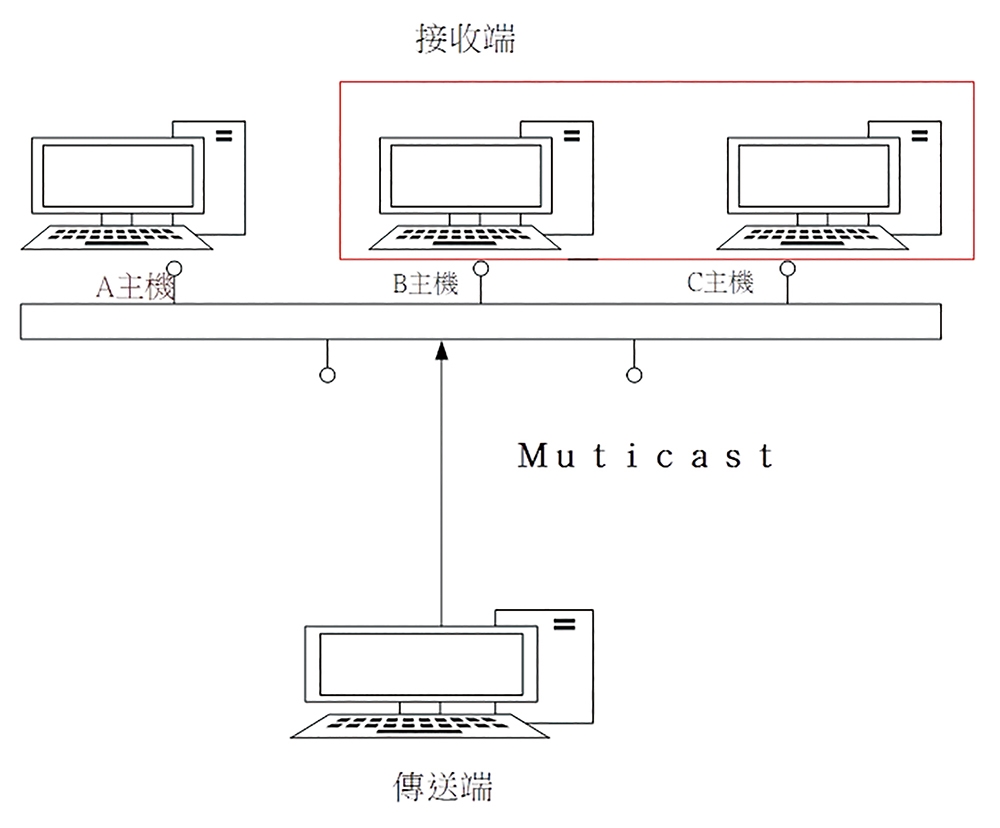 圖3 群播(Multicast)運作示意圖。
圖3 群播(Multicast)運作示意圖。
單點傳播(Unicast)
相對於上述的廣播與群播的方式,此種傳輸方式則是直接將封包傳遞至目的主機。這也是目常最常使用的網路傳播方式,在本文中即是使用此種方式。
安裝Heartbeat
在簡單說明過Heartbeat相關的背景知識後,接著開始安裝Heartbeat。
Heartbeat是由glue、heartbeat、agents三個子項目所組成,可由「http://linux-ha.org/wiki/Download」網頁下載,必須分別安裝這三個軟體。
首先安裝glue,本文所使用的版本為1.0.12。在下載原始碼並解壓縮後,即可執行下列指令進行安裝:
./autogen.sh ./configure make make install #將相關的程式安裝到系統上
接著安裝heartbeat主項目,本次使用的版本是3.0.6,同樣地在下載原始碼並解壓縮後,執行下列指令進行安裝:
./bootstrap ./configure
在此步驟實作的過程中,筆者曾發生「Core development headers were not found」的錯誤,如果在執行過程中也有出現此類錯誤,只要利用「./ConfigureMe configure」來取代「./configure」,即可排除狀況:
make make install
最後安裝agents,將採用3.9.6版本。同樣地,在下載原始碼並解壓縮後,執行以下的指令進行安裝程序:
./autogen.sh ./configure make make install
完成安裝後,Heartbeat便會在「/etc/ha.d/」目錄下產生相關的預設組態檔,並提供一個名稱為「heartbeat」的主程式,以及預設接管時所使用的程序。
由於在啟動Heartbeat服務時,發現Heartbeat預設會讀取「/usr/etc」目錄下的組態檔,而非使用「/etc/」目錄下的組態檔,因此還必須手動建立一個連結,請執行如下的指令:
ln -s /etc/ /usr/etc
ha.cf設定檔說明
成功安裝後,接著說明相關組態檔的常用設定,首先說明主要的設定檔,檔案名稱為「ha.cf」,其常用的組態說明如下:
debugfile
設定儲存Heartbeat在執行過程中相關偵錯紀錄的檔案位置。建議設定此選項,以便在發生錯誤時能夠快速地找出相關的線索。
logfile
設定儲存Heartbeat在執行過程中所產生相關紀錄的檔案位置。
keepalive
設定偵測對方主機是否存活的時間間隔,單位為秒。例如「keepalive 10」,表示每隔10秒便偵測對方是否依然存活。
warntime
設定多久時間未接收到對方主機的回覆,就開始警告提示,單位為秒。
deadtime
設定判定對方主機失效(Dead)所需的時間。當判定失效時,備用主機就會進行接管對方主機服務的動作。所以,此數值要根據所在的網路環境而定,如果設定過低,有可能會因為網路壅塞而未能在時限內接收到對方主機的回覆,因此誤判已失效。但如果數值設定過高,則有可能在對方主機失效時,未能即時地接管對方主機。例如,設定「deadtime 300」表示在5分鐘內如果沒有收到對方主機的回覆,就判定對方主機失效而進行接管。
initdead
表示在重新啟動後,經過多少時間才會執行偵測對方主機的動作。有此選項的原因在於,當主機重新啟動後到網路重新啟動成功,可能會需要一點時間。如果僅設定deadtime選項,有可能會因為deadtime選項值過低,而造成網路重新啟動前所需的時間就已經超過deadtime選項值,而造成誤判主機已失效,因此Heartbeat會在確認網路已經成功後才進行偵測。就官方網站的建議,此數值最好設定為兩倍的deadtime選項值。
bcast
如果Heartbeat的偵測訊息是採用廣播的形式發出,便須設定此選項,指定要利用系統上的哪張網路卡來監聽Heartbeat所發出的廣播訊息,其使用方式如下:
bcast dev
而與bcast相關的參數,說明如下:
dev:設定系統上要用來監聽Heartbeat所發出之廣播偵測封包的網路介面卡名稱,例如「bcast eth0」表示使用系統上的eth0網路介面卡來監聽廣播訊息。
mcast
如果Heartbeat的偵測訊息是採用群播的形式發出,就必須設定此選項來設定監聽Heartbeat的群播封包所使用的網路卡介面及相關資訊,其使用方式與相關參數說明如下:
mcast dev mcast-group udp-port ttl
dev:設定系統上要用來監聽及發送Heartbeat所發出的群播偵測封包的網路介面卡名稱。
mcast-group:設定將參與要監聽及發送群播偵測封包的群組名稱。
udp-port:設定監聽和發送群播偵測所使用的UDP通訊埠。
ttl:設定群播偵測封包的TTL(Time To Live)的值。
如果Heartbeat的偵測訊息是採用單點傳播的形式發出,即須設定此選項來設定監聽Heartbeat的單點傳播封包所使用的網路卡介面及相關資訊,其使用方式與相關參數說明如下:
mcast dev peer-ip-addr
dev:設定系統上要用來監聽及發送Heartbeat所發出的單點傳播偵測封包的網路介面卡名稱。
peer-ip-addr:設定欲偵測對方主機的IP位址。
設定當主節點恢復正常後,是否要自動切換回原來的服務角色,即原來為主節點回復成主節點,原來為備用節點則回復成備用節點。相關參數說明如下:
On:自動切換回原來的服務角色。
Off:不自動切換回原來的服務角色。
設定在叢集中的主機,其使用方式如下:
mode 主機名稱
例如「mode machine1」,就表示名稱為「machine1」的主機是叢集中的主機。
haresources資源檔介紹
在說明過ha.cf設定檔之後,接著介紹Heartbeat的資源檔,名稱為「haresources」, Heartbeat服務啟動時,就會參考此檔案內容來設定相關資源,通常會用來設定網路服務的VIP資訊,其語法如下:
node-name network <resource-group>
與haresources資源檔相關參數,分別說明如下:
node-name:表示主節點的主機名稱,要特別注意的是,此主機名稱必須和ha.cf文件中指定的節點名稱一致(以node選項設定)。
network:用於設定IP位址、網路遮罩(Netmask)、網卡介面名稱等網路資訊。而這裡所指定的IP位址,表示叢集對外服務的IP(亦即VIP)。
resource-group:用來指定需要Heartbeat託管的服務,也就是說,當Heartbeat啟動或關閉時,可利用所設定的程式來啟動或關閉相關程式。
例如「node1 IPaddr::192.168.198.161/24/ens33 apache」,即表示主節點的主機名稱為「node1」,對外服務所使用的IP是「192.168.198.161」並使用網路介面名稱為「ens33」的裝置,當Heartbeat服務在啟動或關閉時,執行Apache程序來啟動或關閉相關網路服務。其執行Apache程序的方式,為當Heartbeat服務啟動時,以「apache start」執行Apache程序,而當Heartbeat服務關閉,則以「apache stop」執行Apache程序。
認證檔案說明
最後,說明叢集中所使用的認證檔案,在叢集中所有節點主機均須具有相同的認證檔案,方可相互認證為同一個叢集中的節點,其檔案格式如下:
auth <num>
<num> <algorithm> <secret>
與其相關的參數,分別說明如下:
num:設定索引值(從1開始的數值),基本上一個認證檔案只需要一個索引值。
algorithm:表示要用來加密認證字串所使用的演算法,例如md5或sha1。
secret:表示實際的認證字串,以下例子即表示設定使用md5演算法來加密Hello認證字串:
auth 3 3 md5 Hello
最後要特別提醒的是,此認證檔案的檔案權限必須設定為600,否則在啟動Heartbeat服務時會出現錯誤。
完成安裝Heartbeat並解說了需要設定的組態檔案後,接下來就可以開始進行系統實作。
開始系統實作
如圖4所示,為本文所要實作的系統架構圖,為了簡單說明起見,在此僅實作當主節點失效時(以中斷網路來模擬),測試Heartbeat是否能夠即時監控到主節點已失效,並且啟用備用節點來接管。亦即當主節點中斷網路服務時,備用節點是否可以即時啟動VIP網路介面來接管主節點,而這裡使用的傳遞偵測封包方式為單點傳播的方式。
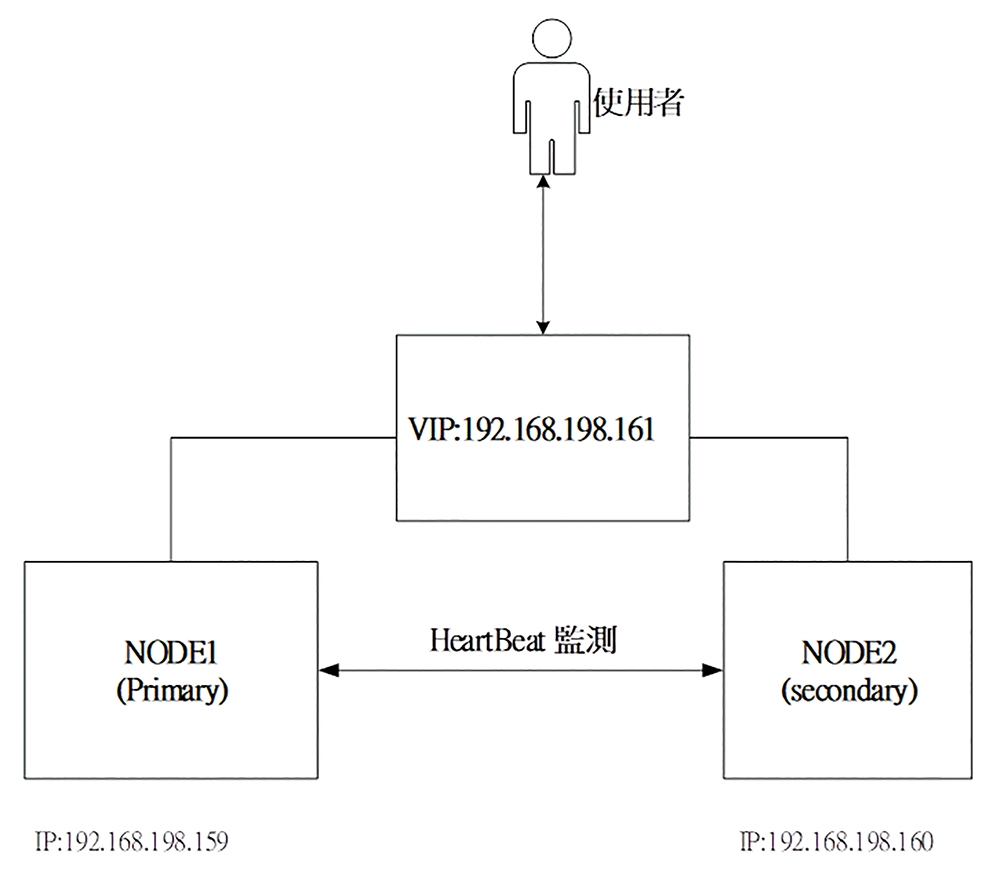 圖4 本次實作之系統架構圖。
圖4 本次實作之系統架構圖。
由於Heartbeat會使用查詢主機名稱的方式來取得叢集上各個節點主機的IP資訊。因此,首先要在node1(主節點)和node2(備用節點)的「/etc/hosts」,新增主機名稱對應IP的資訊,內容如下所示:
192.168.198.159 node1 #表示主機名稱為node1的主機,其IP為192. 168.198.159 192.168.198.160 node2
接著,設定「/etc/ha.d/ha.cf」組態檔。先在node1節點上設定「ha.cf」組態檔,檔案內容如下:
debugfile /var/log/ha-debug logfile /var/log/ha-log logfacility local0 ucast ens33 192.168.198.160 #須指定node2節點的IP位址,ens33為實 作環境所使用的網路卡介面名稱,此名稱須 視實際的系統環境而定
udpport 694 #使用通訊埠694來傳送偵測封包 warntime 5 deadtime 15 initdead 60 keepalive 2 node node1 node node2 auto_failback on #當主節點回復時,自動回復原來的角色
然後,在node2節點上設定「/etc/ha.d/ha.cf」組態檔(除了ucast的組態不同,其餘組態設定應與node2相同),其內容如下所示:
debugfile /var/log/ha-debug logfile /var/log/ha-log logfacility local0 ucast ens33 192.168.198.159 #須指定node1節點的IP位址 udpport 694 warntime 5 deadtime 15 initdead 60 keepalive 2 node node1 node node2 auto_failback on
設定好「ha.cf」組態檔後,接著繼續設定「/etc/ha.d/haresources」組態檔。
同樣地,在node1和node2節點上的haresources檔案中設定如下的內容:
node1 IPaddr::192.168.198.161/24/ens33
設定內容表示,主機名稱為node1是主節點,並使用IP位置為192.168.198.161來當VIP,其使用的網路介面卡名稱是ens33,而網路遮罩為255.255.255.0。
最後,再來設定認證檔案。同樣地,在node1和node2節點上設定「/etc/ha.d/authkeys」認證檔,相關內容如下:
auth 3 3 md5 Hello #表示使用md5加密演算法 來加密Hello字串
完成設定authkeys組態檔之後,記得在node1和node2節點上執行「chmod 600 authkeys」,為認證檔指定適當的權限。設定好相關的組態檔之後,即可啟動Heartbeat服務。 一開始,在node1節點上執行「/etc/init.d/heartbeat start」以啟動Heartbeat服務。在啟動後,可利用檢查「/var/log/ha-log」的方式來確定執行狀態是否正常,在該紀錄檔中應該會發現有類似如圖5所示的訊息,此時要特別注意的重點,在於是否已正常地監測到node2節點以及是否已成功地在node1節點上新建了一個虛擬IP(VIP)。圖5中的訊息(A)表示已順利監測到node2節點,而訊息(B)表示已成功在node1建立一個VIP。
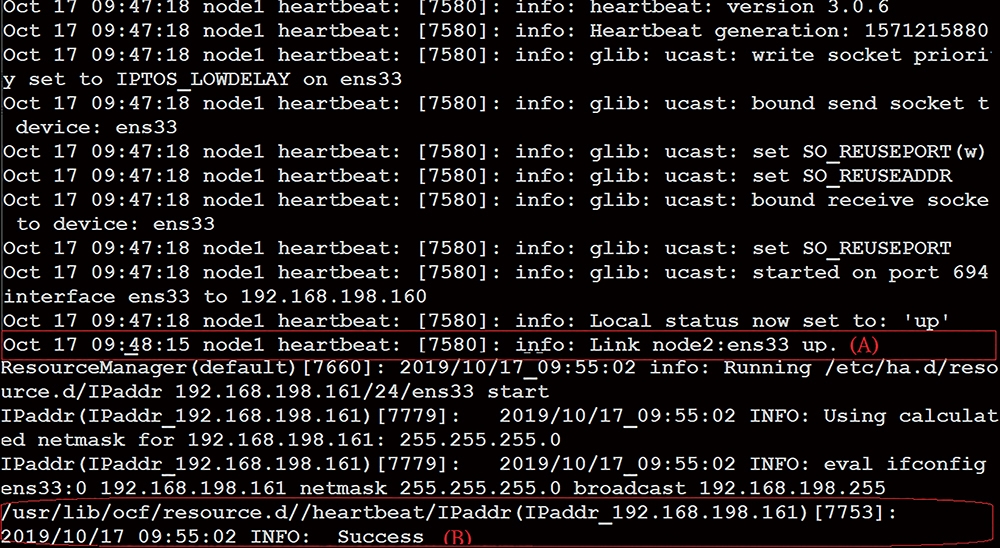 圖5 檢視紀錄檔內容。
圖5 檢視紀錄檔內容。
此時,在node1節點上利用「ifconfig」指令來檢查是否已經產生VIP,如圖6所示,將發現在原有的網卡介面上新建了一個別名(ALIAS)網路卡介面。
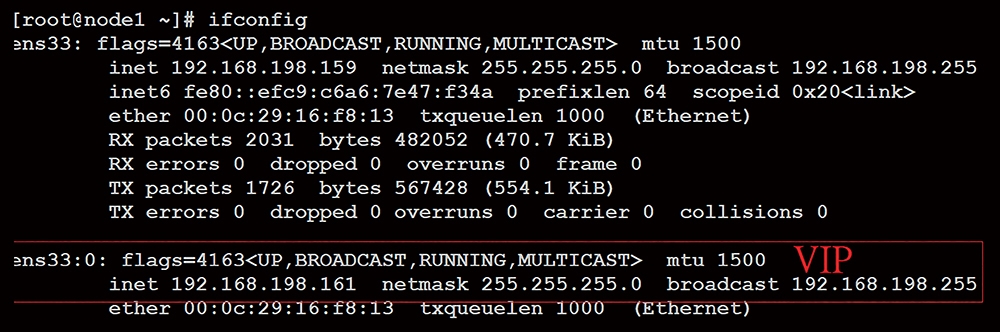 圖6 執行「ifconfig」指令檢查是否已經產生VIP。
圖6 執行「ifconfig」指令檢查是否已經產生VIP。
在實作的過程中,筆者曾遇到一直無法正常建立VIP的問題,並且會在偵錯紀錄檔案內發現「Resource is stopped」的錯誤訊息,後來經過一番痛苦的摸索後,發現原因在於此版本中的IPaddr(用來建立VIP的程序)內容中有一個系統變數並未定義到正確的系統路徑,導致此程序無法執行成功,因而不能正確地新建VIP。所以,如果遇到類似的問題,可以在啟動Heartbeat服務之前,先執行「export OCF_ROOT=/usr/lib/ocf」來定義該系統變數,即可順利執行IPaddr程序。
成功啟動node1節點上的HeartBeat服務後,繼續在node2節點上執行「/etc/init.d/heartbeat start」,以啟動Heartbeat服務。
在node1和node2都成功啟動Heartbeat服務之後,接著在node1節點上利用「service network stop」暫時停止網路的服務,利用此方式來模擬node1節點已經下線。此時,可觀察node2節點是否會因無法監測到node1節點而進行接管。
如果一切都正常,此時在node2節點上將會直接新增VIP(其IP與原先node1所設定的一樣)的網路介面來取代node1。再檢查node2節點上的「/var/log/ha-log」,應該會發現如圖7所示的訊息。
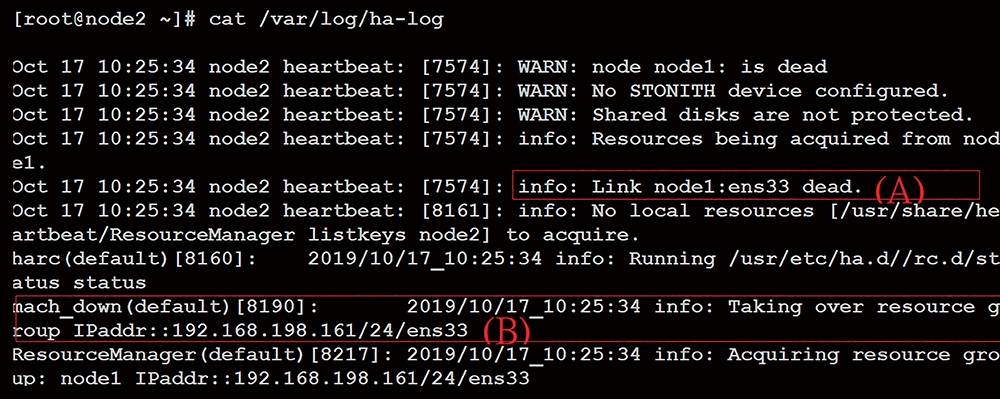 圖7 檢查node2節點的「/var/log/ha-log」內容。
圖7 檢查node2節點的「/var/log/ha-log」內容。
透過圖7中的(A)訊息,會發現node1節點已經失效,而(B)訊息則表示已經接管node1節點,並根據haresources檔案內的設定來重啟VIP,以接管node1主機繼續進行服務。
至此,高可用性架構中的Heartbeat服務就建立完成了!
<本文作者:吳惠麟,多年資安經驗,喜好利用開源碼建構相關解決方案,著有「資訊安全原理與實驗」等書。>