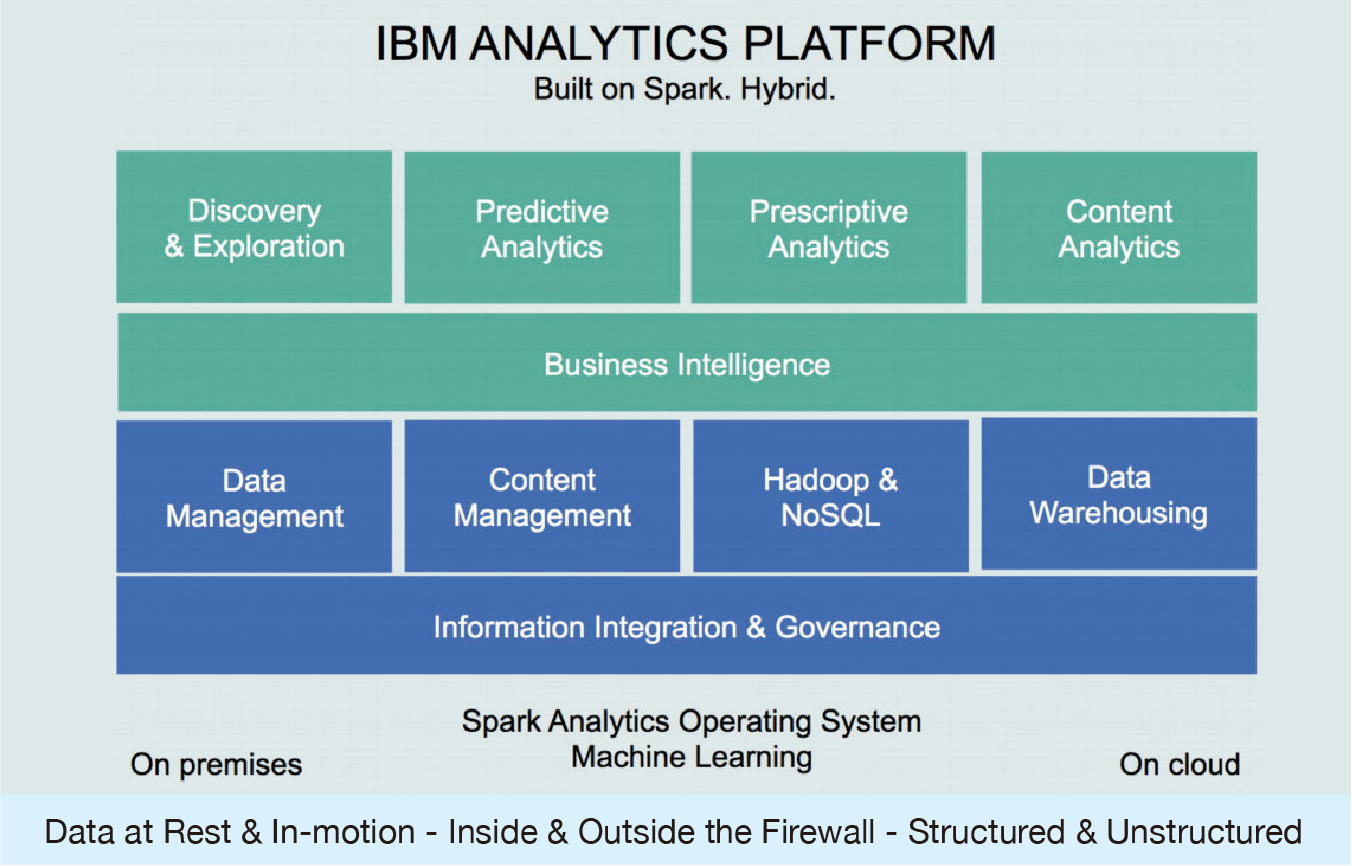
近年來在大數據(Big Data)應用驅動下,資料的整理存放、分析與呈現,成了眾所注目的焦點。為了加快企業部署資料分析環境的腳步,IBM整合旗下資料庫、商業智慧、統計與分析等相關資源,以及開放原始碼技術,擴大雲端資料服務(Cloud Data Services)可提供的範疇,讓IT管理者、開發人員、資料科學家,得以基於既有的知識、熟悉的操作方法,在最短的時間內挖掘出營運業務所需的關鍵資料,不僅提供發展決策參考,更進一步從中創造新商機。
IBM軟體事業處協理胡育銘觀察,雲端平台可提供的服務價值不僅是裸機或強大硬體資源,更重要的是立即可應用的系統,特別是針對資料的處理與分析。無論IT基礎架構如何變遷,幾十?年來,資料科學始終不退流行,因為不管企業採用任何架構,最終都需要做資料處理與分析。然而以往只有大企業有能力建置的系統平台,例如資料倉儲、中介軟體、商業智慧分析工具等,隨著雲端運算模式興起,如今各行業不論規模公司大小,皆可透過雲端服務取用。胡育銘指出,IBM已整合底層的IaaS與PaaS建置,至於應用工具,只要環境參數配置即可。
資料庫與分析工具 增添雲端版
IBM雲端資料服務主要包含:資料儲存、分析與呈現、回饋資料,三種不同面向。針對資料的儲存,不論是自建或雲端服務,會依據不同存取運用方式決定存放位置,例如DB2 on Cloud,負責的即是關聯式資料庫;dashDB為雲端資料倉儲服務;Compose資料庫即服務(DBaaS)特點在於提供NoSQL資料庫(例如Mango等)。此外,若非結構化資料量過大,必須採以Big Data協助執行取用與分析,亦可選擇基於Hadoop平台設計的BigInsights on Cloud,或是近年來竄紅的Apache Spark,同樣可透過雲端服務方式立即使用。
「不論是自建或是採用雲端服務,應用架構皆一致,如此才得以讓客戶移轉到雲端平台時,不需要改變既有的邏輯框架與工作流程。」胡育銘強調。
就應用面來看,姑且不論建置位置,傳統資料倉儲環境主要是做結構性分析,但現在的Big Data趨勢,是先建置「資料資源池(Data Lake)」來存放結構與非結構資料,再透過建立於Hadoop平台上的ETL(Extract-Transform-Load)工具整理出必須存放至資料倉儲中的資料,因為Big Data資料量相當大,傳統技術有先天限制,才有新與舊技術的整合應用模式出現。即便是雲端平台上運行,也是同樣的架構。
Data Lake先行收容結構與非結構資料
近來備受關注的Data Lake,有稱為資料湖或資料瀑布,但胡育銘認為,資料資源池更貼近應用概念的描述。過去IBM曾統計,企業內部結構性資料大約15%,其他85%皆為非結構性資料,實務上能用來建立模型、執行分析的系統交易資料僅只有15%,主要即是受限於硬體運算、資料結構原生的能力。但近年來,隨著Big Data應用發展,大量的非結構化資料亦可獲得進一步處理與分析,因而企業的思考模式也改變,掌握15%資料已是基礎必備,更多心思花費在另外85%的資料,試圖從中取得對業務營運有價的資訊。
更進一步是除了內部營運產生的資料,外部社群網站、討論區等網路服務平台上討論的話題,諸如此類來自外部的資料,也必須一併統合整理。若仍以傳統資料倉儲來處理如此龐大資料,實務上根本不可行,因此會在資料倉儲之前先建立Data Lake,也就是把所有爬取外部網站蒐集到的資料,以及內部營運資料,全數皆存放在Data Lake環境,之後再透過資料轉換工具建立模型,從中萃取出有用的資訊,並匯入資料倉儲存放,如此也才得以更有價值地運用資料倉儲系統。
 |
| ▲ IBM基於Apache Spark打造資料分析平台。 |
而Data Lake底層就是運用Hadoop平台,屬於Big Data應用的一環。當資料量過於龐大時,主要會遇到如何儲存、如何存取問題,若採用傳統掃描方式,要去撈取特定資料,相當耗時費資源;其中的MapReduce技術則可以把資源分配到多台主機上同時執行,因此速度相當快,正適合於Big Data應用環境。
但自從2014年在國際資料排序基準競賽(Sort Benchmark Competition)中,參賽隊伍以Spark平台運行In-memory技術,不到30分鐘排序完成100TB的資料量,重寫Hadoop的72分鐘記錄之後,Spark開始受到各界關注。胡育銘從台灣學術單位觀察,現況皆是採用Spark搭配R語言為主要教學模式。
「不論如何,只要是具未來性的應用趨勢,IBM自然會投入資源全力支持,如今IBM在舊金山成立的Spark實驗室,已有一千多名研發人員,由此可印證IBM相當看好Spark發展,就我所知,已有15個產品線的底層都改成Spark環境。」胡育銘說。
資料分析與呈現服務 產出報表不費力
至於資料分析與呈現服務,則包含Watson Analytics、商業智慧與財務績效管理Cognos Analytics,以及圖形資料庫服務IBM Graph。以往用戶為了因應特殊需求設計的分析報表,至少要耗費三天時間才得以產出,此平台設計提供自我服務(Self-Service)特性,讓終端用戶以拖拉方式即可產生,不用再向IT部門提出需求。
胡育銘說明,IBM將近年來推動的認知運算運用到資料分析領域,只要把資料匯入分析系統,即可主動讀取資料,懂得欄位的定義,例如可自動辨識出資料屬於電信業,且依照內容來看,判定需執行流失率分析;若發現資料來自航空業,則可能要做的是客戶滿意度分析。同時,不同用途適合採用的資料呈現方式,例如圓餅圖、長條圖等,也會主動提供建議。
「懂得欄位定義與資料內容,稱為自我學習。傳統概念是分析判斷必須事先定義運算基礎才能達成,IBM的認知運算即是超越此框架,經由持續地自我學習建立模型並且強化認知能力。」