今年3月,Google人工智慧圍棋程式AlphaGo挑戰南韓圍棋九段棋手李世 ,這場人機之間的對弈受到眾多矚目,最終AlphaGo在五局比賽中以總比分4:1勝了「人類代表」李世 。這場看似話題性居多的賽事,背後想要凸顯的卻是機器設備所具備的深度學習能力。
事實上,隨著資料量激增以及商業模式的快速變革,深度學習(Deep Learning)這種由機器學習延伸而來的人工智慧技術,受到的矚目正在與日俱增,包含亞馬遜(AWS)、IBM、微軟以及Salesforce等業者,也都紛紛搶攻深度學習領域,現階段市場已見運用在語音辨識、購物推薦、醫療演算模型等相關的系統中。而日前,NVIDIA也在NVIDIA GTC 2016年度大會上,正式發表首款適用深度學習模型的超級電腦DGX-1,投入企業應用市場。
DGX-1的強大運算能力主要是來自於8張Pascal架構NVIDIA Tesla P100,搭配2顆20核心Intel Xeon E5-2698 v4處理器、512GB DDR4記憶體以及4顆1.92TB SSD的配置,根據官方資料顯示,其效能就等同於250台x86伺服器組成的運算叢集。
以企業為目標市場
NVIDIA解決方案架構師廖振詠指出,深度學習的需求正在攀升,包含AWS、Google、Facebook、百度以及阿里巴巴等大型雲端服務業者都已投入大量資源,聘雇許多工程師以及資料科學家,甚至成立專門的深度學習中心。對大多數企業而言,不管是人力部署或資金投入,想要跟隨建置門檻並不低。更極端一點,有些單位可能只有資料科學家的職位,而沒有專屬IT人員的配置,資料科學家既不會管理IT設備,也不懂如何安裝已調校過的軟體來管理IT叢集,這時如果能有一台設備能夠解決這些問題,無疑能夠節省大量安裝與調校的時間,加速資料分析的速度,這就是NVIDIA DGX-1想達成的目的。
 |
| ▲NVIDIA GTC 2016年度大會上,NVIDIA正式發表首款適用深度學習模型的超級電腦DGX-1,投入企業應用市場。(資料來源:NVIDIA官網) |
他提到,過往企業部署超級運算環境,除了採購大量伺服器之外,還需要花費很大的力氣,確保設備與設備之間的互連,例如InfiniBand的架構設計。如果能夠將數百台的伺服器集中在單台設備內,就能夠減少頻繁的網路溝通。也因此,NVIDIA設計了DGX-1這款設備,在3U高的設備中,放上8張Tesla GP100 GPU卡,滿足企業對運算速度的超高需求。
針對NVIDIA DGX-1適用領域,目前也鎖定了教育單位(針對物理、數學、氣象等領域的高速運算應用)、電信業者、醫療產業以及高科技產業。廖振詠強調,其實,在還沒有NVIDIA DGX-1之前,企業也能用大量的伺服器來建構深度學習環境,並非不能做到,但是NVIDIA DGX-1更重視時間效益,透過NVIDIA的完整支援,設備採購後就可以直接開機使用,而不用花費長達2至3個月的採購流程以及後續部署、最佳化調校以及軟體安裝等曠日廢時的作業。
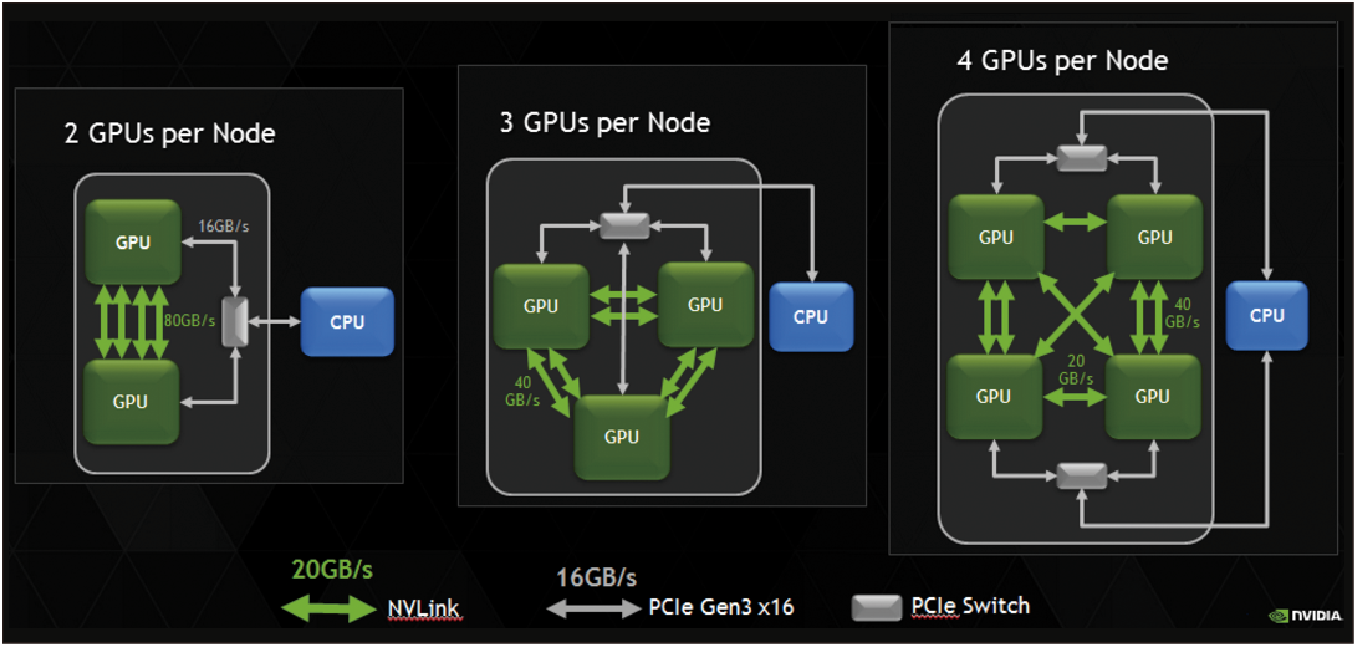 |
| ▲藉由NVLink混合式立方網絡(Hybrid Cube Mesh)的技術,可有效解決GPU之間的溝通瓶頸。(資料來源:NVIDIA官網) |
NVLink加速溝通
當然,如果僅僅只是把8張GPU卡加以集中在一台伺服器內是沒有意義的,想要達成高達170 Teraflops半精度尖峰運算效能,需要特殊的加速溝通機制,NVIDIA DGX-1採用的是NVLink混合式立方網絡(Hybrid Cube Mesh)的技術。所謂的Hybrid,係指混合了PCIe Gen3以及NVLink這兩種不同的通訊協定,實際的配置上,2顆CPU的溝通主要是透過PCIe Gen3,以16GB/s的傳輸頻寬進行訊息溝通,而兩個GPU之間則是以NVLink互聯,由於NVLink的數據交換速度至少比PCIe快5倍,頻寬可達80GB/s,因此能有效解決溝通瓶頸。
而Cube Mesh則指的是,每個GPU都有4個對外NVLink的連繫通道,以4個GPU為一單位時,兩兩GPU之間的連繫就會用掉3個NVLink,而多出來的一條NVLink,就負責串接另一個Cube,而形成一個綿密的網絡,如此一來,每個GPU都能藉由NVLink找到最短的路徑,由於NVLink的頻寬可達80GB/s,平均分配後,兩兩GPU之間的傳輸頻寬可達20GB/s,也比PCIe Gen3來得快些,藉此解決GPU之間的瓶頸。
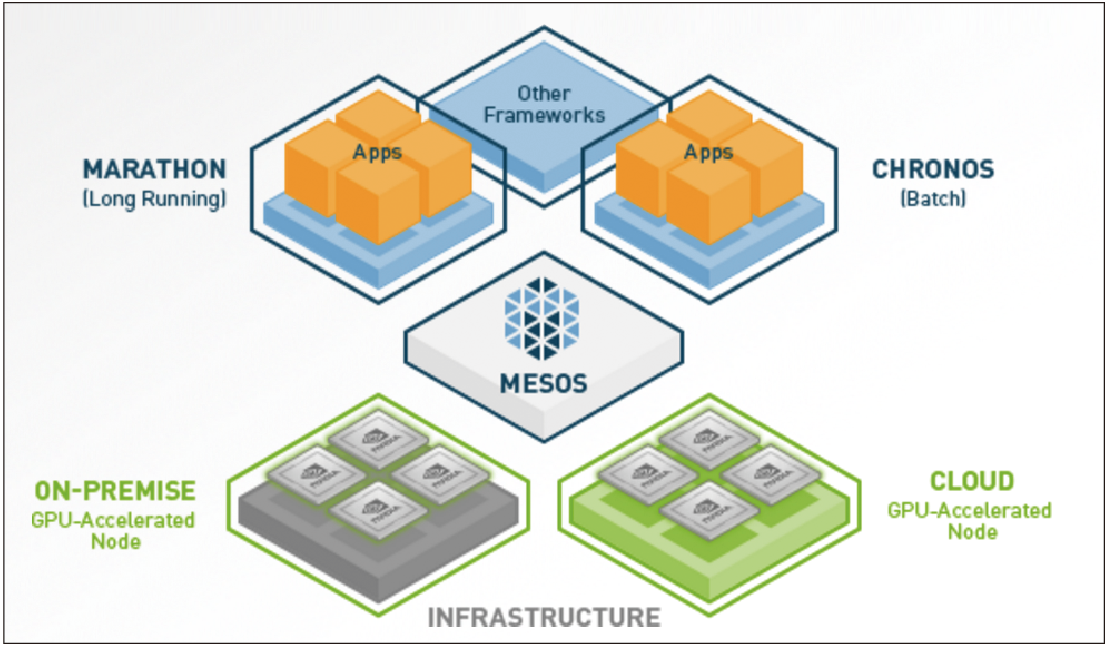 |
| ▲運用Apache Mesos技術,相關軟體已被打包成容器,方便企業下載執行。(資料來源:NVIDIA官網) |
先進製程記憶體
當GPU被用來運算大量資料時,就需要高頻寬的記憶體,NVIDIA DGX-1搭載以16nm FinFET製程HBM2記憶體,存取的頻寬也可以快3倍。這是因為以往的GDDR5記憶體(雙倍資料傳輸率記憶體,Graphics Double Data Rate, version 5)只有280…^300GB/s的頻寬,現在則可以上看到1,000GB/s以上。
另外一個特別之處是,過往Tesla顯示卡的ECC mode需要佔用記憶體空間,平均是6…^7%,換句話說,只要ECC mode的功能一打開,總記憶體容量就只剩93%,同時也會犧牲時間與頻寬。而HBM2由於採用了全新的記憶體製程,ECC mode就無須成本。原因是GDDR5記憶體在設計時並沒有考慮到ECC mode,因此要額外設計ECC mode,才能做好bit校驗,而這會佔用到空間、時間以及頻寬,但HBM2在規格的制定上,就有預留ECC mode這種機制,不用額外佔用記憶體空間做ECC mode校驗。
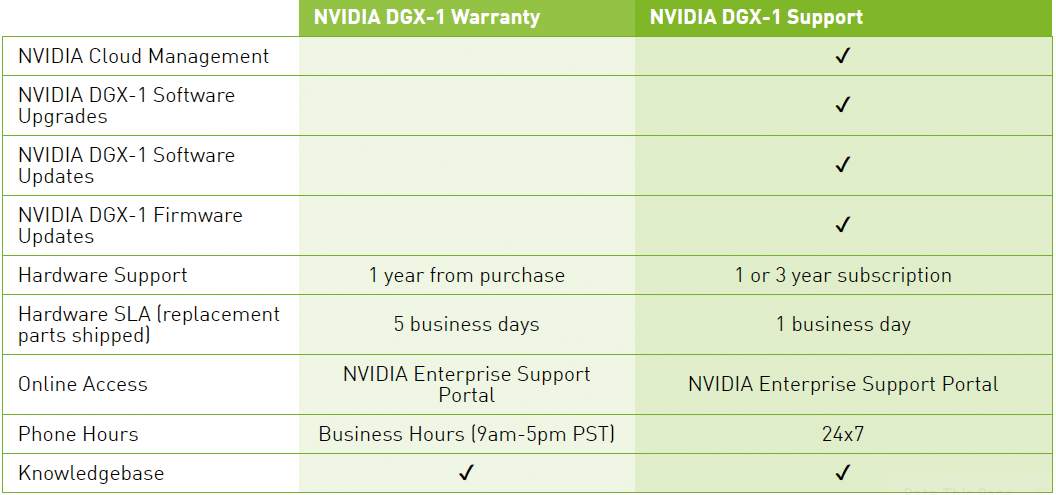 |
| ▲加購升級服務不僅能提高硬體支援年限,SLA服務層級也會提高,同時確保軟體的穩定性。(資料來源:NVIDIA官網) |
容器技術打包軟體
建構深度學習基礎架構環境需要軟、硬體密切的配合,NVIDIA DGX-1已預先安裝多層次應用軟體,其中包含可加速所有主要深度學習架構的程式庫、NVIDIA Deep Learning SDK、DIGITS GPU訓練系統、驅動程式及CUDA等等。而這些軟體已被打包成容器(採用Apache Mesos技術),並且放置在容器的農場中,使用者可自行下載、啟動,如此就可以執行服務。
 |
| ▲NVIDIA解決方案架構師廖振詠指出,NVIDIA DGX-1有五大技術突破,包含Pascal架構、NVLink混合式立方網絡(Hybrid Cube Mesh)技術、16nm FinFET製程、HBM2堆疊記憶體以及新的AI演算法。 |
另外,當軟體需要很多的GPU一起幫忙時,如何分散工作量到每個GPU,以便讓工作負載平衡也相當重要,也因此,軟體在撰寫的過程中,就要考量硬體。廖振詠解釋,NVIDIA DGX-1可以提供高達170 Teraflops半精度尖峰運算效能的原因,正因為軟體與硬體相互配合,軟體認為精準度不需要到32 bit,而要調整為16 bit時,硬體也能提供16 bit的指令,協助提高速度。例如單張NVIDIA Pascal有5.3 TFLOPS以上的Double Precision,乘2之後就變成10.6 TFLOPS Single Precision,再乘2之後就變成21.2 TFLOPS的Half Precision。將8張Pascal半精度浮點數加乘,就接近170 TFLOPS。
廖振詠認為,DGX-1並不只是一台硬體,而是一個平台,也因此,NVIDIA DGX-1除了提供硬體之外,還包含了軟體、後續維護以及版本升級等服務。為了因應企業不同需求,NVIDIA DGX-1能以裸機模式(Bare OS Mode)購買,亦即只採購硬體與維護服務,由企業自行安裝軟體,但若打算軟、硬體均採用NVIDIA方案,那麼就可以加購升級服務,此項升級服務主要針對容器技術,NVIDIA會負責容器版本升級並且保持穩定,以年約來計算。
事前評估三要項
儘管這種透過模仿人類大腦神經網路的運算模式已成為新興的研究領域,而藉由NVIDIA DGX-1也能大幅減少運算時間,對企業創新與新產品上市極為有利,不過在導入之前,仍有一些必要的環境與技能需要備齊,舉例來說,NVIDIA DGX-1在3U的空間中要耗電3200W,當設備需要較高的電力時,機櫃是否有足夠的電力支撐,有無不斷電系統以防止電力中斷情形發生,另外冷卻空調是否足夠?
而在技術方面,由於相關的軟體已被打包成容器,IT人員必須熟悉Apache Mesos才能做好管理。另外,假設企業只打算採購Bare OS Mode,那麼設備上所需安裝的軟體與授權也是需要事先準備好,由於NVIDIA DGX-1目前只運行在Ubuntu Server Linux OS,而且不支援Red Hat,軟體的相容性也需要考量。萬一軟體是運行在Windows作業系統之上,企業必須先虛擬化後再安裝容器,因此虛擬化平台的授權費用也需事先備妥。
「當然,IT人員有沒有熟悉NVDIA線上Documentation也是很重要的一點,以上都準備好後,導入NVIDIA DGX-1才能得心應手。」他說。