Big Data平台顯然需要次世代的資料中心,才能徹底發揮能力。但是,多數人以為只要透過虛擬技術或Hadoop來建立伺服器群(Server farm)就足以擔當重任,卻忘了分散式運算系統需要在伺服器之間高速傳遞大量資料,若沒有打造一個先進的網路架構,勢必不足以支撐高速資料處理所需的效能要求。
幾乎每隔幾年,IT科技界總是會出現某種革命性的技術發展,伴隨著難以快速理解的名詞,例如5年前興起的「雲端」(Cloud)一詞。不過時至今日,雲端的重要性早已不言可喻,IT界還會出現另一個足以改寫產業趨勢,卻又難以理解名稱的新科技嗎?
有的,那就是Big Data!打從一開始,Big Data和雲端一樣,連定義都眾說紛紜,能夠精確講出「何謂Big Data」的人屈指可數,甚至連中文譯名都無法統一;中國稱之為大數據,臺灣稱之為巨量資料或是海量資料。
眾說紛紜裡 看穿Big Data特點
那麼,究竟什麼是Big Data呢?根據Wikipedia上的定義,Big Data意指一個異常龐大與複雜的資料組合,難以透過現有的資料庫管理工具或傳統的資料處理流程進行處理。用白話文來說,所謂的Big Data,是一種能夠蒐集各種多樣化資料數據,以非常高效率的資料處理技術,分析出對使用者有意義的資訊之方法。換言之,Big Data應具有以下特點:
多樣性:Big Data應能夠蒐集各式各樣的資料,匯聚一堂,如推特(Twitter)的貼文資訊、車隊行車GPS記錄、網站廣告點擊記錄等各式各樣資料記錄,無須如同傳統關聯式資料庫,必須先設計好欄位,才能將資料放入。
資料量驚人:究竟要多「大」的資料量,才配稱得上Big Data呢?舉例而言,中華電信每月保留的用戶瀏覽網頁記錄有3?4TB的資料量,約等於幾千萬筆的記錄,而eBay每天需要分析的交易記錄資料量更甚至有50PB--等於50,000TB。
高速資料處理:事實上,處理巨量資料並非史上頭一遭,過去資訊科技界已經發展出資料倉儲(Data Warehousing)技術,協助企業分析巨量資料。然而,資料倉儲技術多半將各種結構化資料集中儲存於某處後進行分析運算,而Big Data技術不但能夠儲存多樣化資料之外,亦能夠透過分散式運算,在極短的時間內進行資料分析運算,不但沒有資料儲存容量上限,更可以隨需要不斷投入運算資源。
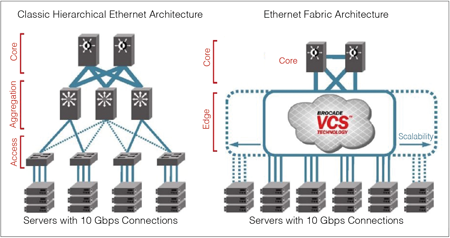 |
| ▲為了因應新型資料中心的網路需求,Ethernet Fabrics架構採取了迥異於傳統三層式網路的機制。 |
真實性:這講起來有點玄,但這正是Big Data的精神所在,與其他資料處理技術如資料倉儲技術或商業智慧技術有所不同,Big Data能夠在短時間內處理難以想像的巨大資料,這讓使用者能夠以全新視角挖掘出隱藏在眾多資料中的真相,而不只是跑一些例行性報表。
傳統資料中心 面臨巨量大挑戰
如今,各行各業開始尋求各種以Big Data獲取更多利潤的解決方案,不論是金融、運輸、零售、電信等產業,都在嘗試引進各種Big Data技術與平台。然而,Big Data不同於其他商業化資訊技術,因其高速、分散式運算等特性, 為企業原有的資料中心架構迎來一場壓力巨大的挑戰。
首先是分散式運算所帶來的挑戰,傳統資料中心多半是將同一種應用的伺服器放置在一個機櫃中,再連接到同一個交換器上,以降低伺服器之間的通訊延遲。然而,Big Data所需要的分散式運算,往往將資料分散儲存於橫跨交換器,甚至橫跨多地機房的伺服器上,然後將資料分析工作切割成一個個片段,交給最高可達數萬台伺服器同時進行運算。
因此,傳統資料中心的三層式網路架構,相當不利於分散式運算系統所需,一旦Big Data的運算節點需要增加或擴充時,繁瑣的網路管理設定難以滿足Big Data平台所需要的靈活變動需求。
再來是高速資料處理所帶來的挑戰。現有許多傳統資料中心系統,設計之初是為了滿足批次處理資料所用。換言之,所有的資料處理流程已經事先設計好範本,資料傳輸流量也根據範本需求予以最佳化,方能夠在一定的時間內,從龐大的資料當中分析整理出使用者所需要的報表。
但是,Big Data平台所處理的資料分析,往往不見得有固定的範本與流程,甚至是透過類似搜尋引擎的方式,即時從龐大的資料當中分析比對出答案。傳統的資料中心系統,無法支援Big Data能持續不斷地處理源源而來資料,協助企業部門即時進行決策。
顯然Big Data平台需要次世代的資料中心,才能徹底發揮能力。但是,多數人以為只要透過虛擬技術或Hadoop來建立伺服器群(Server Farm)就足以擔當重任,卻忘了分散式運算系統需要在伺服器之間高速傳遞大量資料,若沒有打造一個先進的網路架構,是不足以支撐高速資料處理所需的效能要求。
那麼,Big Data技術又需要何種先進的資料中心網路架構,才能徹底發揮能力呢?
Ethernet Fabrics 打造最佳網路架構
以常見的Big Data平台Hadoop來說,需要一個低延遲、可擴充,且至少10GbE連結速度的資料中心網路。但傳統的三層式網路架構,是一種樹狀結構,每台交換器管理固定數量的IP與網路卡,增加了資料傳輸路徑的複雜度,也往往為了避免資料傳輸路徑衝突,而限制了網路的使用率與擴充性。更別提每台交換器都需要個別設定管理的麻煩,以及必須為備援增加設備的成本支出。
因此,Big Data平台需要更為先進的Ethernet Fabrics網路,能夠感知網路上所有的路徑、節點、資源及需求,並根據需求自動進行設定與擴充。想要增加資料中心的網路節點?很簡單,把新的交換器接上Ethernet Fabrics就可以了,它能夠自動接手新增交換器的設定,自動決定最佳的資料傳輸路徑;想要將伺服器搬移到另一個機櫃,甚至是另一個機房?很簡單,甚至不必麻煩到網管人員,儘管把伺服器搬過去,接上另一個交換器!Ethernet Fabrics將會自動辨認出伺服器的移動,並重新決定交換路徑。
以Brocade 的Ethernet Fabrics網路架構為例,讓Big Data平台部署虛擬機器(VM),或是進行分散式運算,將零碎的運算任務同時傳送給所有的運算單元時,都能夠得到最佳的資料傳輸路徑、最低的傳輸延遲時間,甚至還能達到網路零停機的能力,這對必須時時刻刻蒐集源源不斷的資料之Big Data平台來說,更是降低營運風險的有力措施。
(本文作者現任Brocade大中華區技術總監)